干货 | Kaggle 光度测定 LSST 天文时间序列分类挑战赛冠军出炉,看他提高分数的秘诀

AI 科技评论按,几百年来,人眼一直是夜空中天文源(astronomical sources)分类的仲裁者。但是,一个新的设备——大型天气观测望远镜(LSST)——即将彻底改变这个领域,它发现了 10 - 100 倍于我们所知的在夜空中变化的天文源,其中一些天文源是以前完全没有被发现的。
为了帮助一些世界领先的天文学家掌握宇宙最本质的特征,光度 LSST 天文时间序列分类挑战赛(PLAsTiCC)要求 Kaggers 对这项新调查的数据进行分类。参赛者将被要求把随时间变化的天文数据源分为不同的类,类的大小不一,从小的训练集到 LSST 能够发现的非常大的测试集都有涉及。该比赛于 2018 年 12 月 10 日截止报名,2019 年 2 月 15 日,会公布LSST研讨会公告。
比赛的评估方法:
使用加权多分类的对数损失评估提交。总体效果是,每个分类对最终分数的重要性大致相同。
每个对象都有一个类型的标签。对于每个对象,必须提交一组预测概率(每个类别一个)。公式是这样的:
其中,N 是某个类别里面的对象数,M 是类别数。ln 是自然对数,对于 yij ,如果观测 i 属于 j 类,那么yij 为 1,否则为 0。pij 为观测 i 属于 j 类的预测概率。
给定对象的提交概率不需要求和为 1,因为它们在计分之前被重新校准(每行除以行和)。为了避免对数函数的极值,将预测概率替换为
。
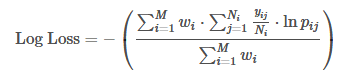
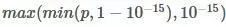
比赛奖励:
比赛主办方还会参赛选手提供了价值不菲的奖励,第一名奖金为 12000 美元,第二名为 8000 美元,第三名为 5000 美元,而且,优胜选手还可以额外受邀参加即将举行的 LSST 研讨会之一,如 2019 年 2 月在美国旧金山举行的 LSST 合作会议,2019 年 5 月在澳大利亚悉尼举行的 LSST 合作会议,以及 2019 年 7 月在法国巴黎举行的 LSST 合作会议。
目前,本次比赛的冠军 Kyle Boone 已经在 kaggle 上分享了他的方案,雷锋网 AI 科技评论编译整理如下:
大家好,相关代码现在可以在我的 Github 页面上找到。
首先,感谢所有参加这次比赛的人!我学到了很多,我很喜欢和你们讨论问题。以下是我在本次比赛中获得第一名的模型的概述。我将很快发布完整的代码。
我是一名研究超新星宇宙学的天文学家,我的工作主要是区分不同类型的超新星。最终模型的结果很不错,因为其他的东西都很容易区分。以下是我的解决方案的概述:
通过减弱训练集中易于观察的光度曲线来增强训练集,以匹配测试集的属性。
使用高斯过程预测光度曲线。
测量了原始数据和高斯过程预测的 200 个特征。
训练一个 5 倍交叉验证的 LGBM 模型。
我首先使用高斯过程(GP)回归来提取特征。我用一个在波长方向上具有固定长度刻度和在时间方向上具有可变长度刻度的 Matern Kernel 对每个物体进行了 GP 训练。我的机器每秒可以进行 10 次拟合,因此需要大约 3 天的时间来完成所有拟合。高斯过程为采样良好的光度曲线生成了非常好的模型,即使测量是在不同的波段也是如此。对于采样率很低的光度曲线,GP 很好地拟合了可用的数据,但并不总是能很好地进行预测。下面是一个例子:
我用 GP 预测计算了许多不同的特征。超新星的显著特征是它们的峰值亮度和光度曲线的宽度,所以我在模型中对它们进行了一些测量。对于采样率很低的光度曲线,GP 并不总是能给出很好的结果,所以我添加了一些特性。这基本上归结为计算在最大光周围不同窗口中的观测次数。我还增加了与每个波段的信噪比相关的特性以及一些简单的峰值检测和计数,来帮助对非超新星进行分类。
现在的训练集和测试集有很大的不同。为了解决这个问题,我把训练集中的每一条光度曲线都减弱了 40 次,得到了一个看起来像测试集中采样不好的光度曲线的东西。减弱包括:
修改银河系中物体的亮度。
修改银河系外物体的红移(包括延长时间和改变亮度)。
增加一些空缺值,例如由于时间不同在真实数据中出现的空缺。
基于模型的数据中的 spec-zs 转为 photo-zs,在观察中选择一个新的 photo-z 和 photo-z 错误
进行模拟检测,以选择将哪些对象包含在给定的数据集中。
这种减弱都是针对训练数据或测试数据集进行的,没有使用外部数据。经过这个过程,我最终得到了一个含有大约 270000 个对象的训练集,它比原来的训练集更能代表测试集。我使用 5 折交叉验证在这个训练集上训练了一个 LightGBM 模型,并确保在同一个数据集中保持每个对象多达 40 次减弱。在调整了这个模型之后,我在原来的训练集上得到的 CV 系数约为 0.4。下面是误差矩阵:
这个模型的误差矩阵与 CPMP 的误差矩阵相比,有一些有趣的区别,比如我在类别 6 对象上的精度比 CPMP 低很多。这似乎是因为在我的减弱过程中,类别 65 相对于类别 6 来说信噪比更高。
我在如何识别类别 99 对象方面做了很多工作。我发现我使用的基于树的模型不太适合异常值检测。我最好的结果出现在选择一个平分给类别 99 的对象,然后在 soft-max 中使用它来获得最终概率。通过这个,我在公共排行榜上获得了我认为最好的真实分数 0.726。
在努力提高这一分数很长一段时间后,我一无所获。接下来的一个星期,我意识到我可以通过观察排行榜找出类别 99 的对象。这种做法违背了预测类别 99 对象的目的,并且不幸的是,我得到的结果比任何对类别 99 对象的实际估计都要好得多。我就此事联系了组织者,并被告知这是符合 kaggle 规则的。最后,我发现我对类别 99 对象的最佳预测是类别 42、52、62 和类别 95 预测的加权平均数。这个把戏让我在公众排行榜上的最后得分提高到 0.670。看看其他竞争对手做了什么是一件很有趣的事情。
总的来说,我非常喜欢这场比赛,从比赛中我学到了很多东西!目前,我正在努力整理我的代码,以方便其他人阅读。我认为我的模型调优还有很大的进步空间,我没有尝试做任何集成或使用除 LGBM 之外的分类器。
对于任何参与的天文学家来说,我将在几周后进入 AAS,我很想和大家见面讨论比赛!
来源:https://www.kaggle.com/c/PLAsTiCC-2018/discussion/75033





