冠军方案 | 第二届中国“高分杯”美丽乡村大赛(遥感图像)第一名总结
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
作者 | lsh呵呵
来源 |
https://blog.csdn.net/nima1994/article/details/89849773
第二届中国“高分杯”美丽农村大赛实验阶段从2019年1月底到2019年3月中旬。从我公布第一个baseline版本
(https://blog.csdn.net/nima1994/article/details/86685024 ,2019年1月29日)到最后,已经通过大量实验,将精度由最初的0.2686提升到了0.4861,位于第三,与精度第一名的团队差0.0004。
比赛4月中旬结束,最终获得第一名。此文为提交文档的精简版。 第一次得大奖,哭唧唧😂。
方案关键点
1. 波段选择和归一化
本次实验选择波段8、5、1进行波段组合,并由ArcGIS直接导出为RGB颜色,这样的话就得到一副RGB彩色图像,其归一化范围为0~255。

2. 异常检测添加“其他”类别样本
采用了异常检测的思想,使用孤立森林(iForest、Isolation Forest)模型,将其他类当作“异常”类,从而增加第四类样本。我们以三类训练样本中心点取得大小为7x7x3的数据参与模型训练,在训练的高分影像数据上随机选点,并将预测值等于1也就是异常的样本加入训练集。该步骤选择了3000个“其他”类别地物样本。

3.构建分类模型
用了深度学习构建了浅层的CNN模型,5372个样本点数据增强,选用了25x25x3的特征窗口作为卷积网络的输入,选用了F1值较为高的训练模型。
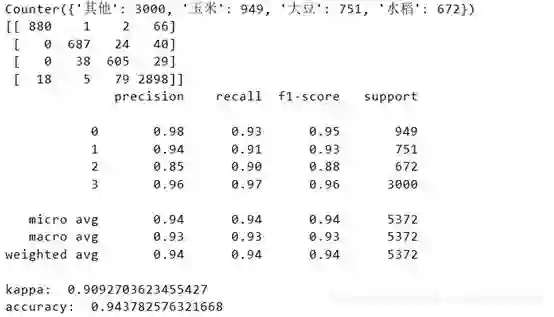
4.多进程全图预测
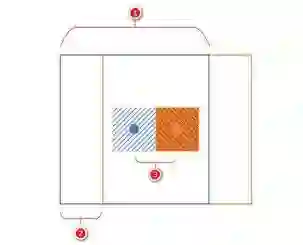
1处表示采样窗口大小为size=25,2处表示左上角步长step,3处表示中心点的移动步长step。比如当step等于3时,中心点(center_x,center_y)每次移动步长也为3,此时我们标注[center_x - 1,center_y - 2)的区域。这样减弱了逐像素标注缓慢(即步长为1),以及大块标注出现的边缘锯齿现象。
5.分类后处理
实验仅仅使用ArcGIS提供的“空间分析工具-邻域分析-焦点统计”,统计类型为众数。
实验结果
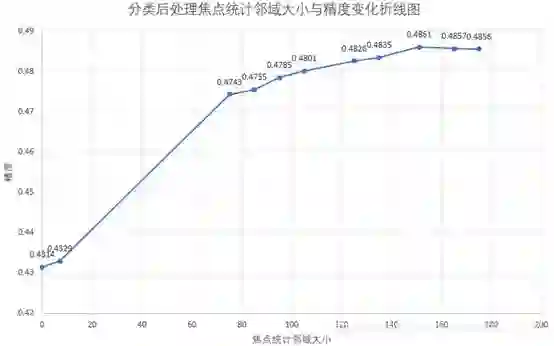
表6.3 焦点统计邻域大小与精度折线图,0表示没有进行焦点统计即原始预测输出。

图6.5 焦点统计大小为151处理结果,局部
总结
这次比赛持续时间较长,我们的主要工作是在寒假。除了本文的方法,我们基于八个波段数据、使用了三分类+阈值的方法(如上文提到的baseline),分类效果并不好,我们认为这主要是因为缺少其他类的信息,模型不能学习有别与其他类的特征。在八波段的实验中,我们使用过深度方向的可分离2D卷积(SeparableConv2D)用于学习未归一化数据特征,效果并未有明显改善。由于数据的不平衡,我们使用了smote算法进行样本过采样,发现影响不大,大概是因为本实验的样本不平衡并不是很严重。除了IForest进行异常检测生成其他类别样本,我们也尝试过OneClassSVM和AutoEncoder,最终选择了表现更好的孤立森林。在我们面向对象的分类实验中,精度很快达到0.4526,但后处理优化提升空间不足。除此之外,我们还做过其他实验,限于篇幅,不再说明。
原始的训练影像有明显的拼接痕迹,在不同的区域有色彩差异,训练样本每类1000左右,在局部小区域的样本更容易被模型“忽略”。所以,使用特征提取+距离度量(如KNN)的方式进行实验似乎效果更好。我们使用了小型的卷积神经网络模型,模型训练表现出不稳定,收敛有时会到一个不好的极值,我们通过多次运行并选取F1值 较好的模型。事实上,虽然小型网络的损失函数的局部极小值更少,也比较容易收敛到这些局部极小值,但是这些最小值一般都很差,损失值很高。相反,大网络拥有更多的局部极小值,但就实际损失值来看,这些局部极小值表现更好,损失更小。因此,更合理的方法是使用较复杂的网络和一些减少过拟合(如正则化)的方法。
感谢主办方以及所有提供过帮助的人。
完整代码:
https://github.com/lsh1994/tianchiorgame/tree/master/dianshi_gaofenbei_1901
*延伸阅读
结构化数据的迁移学习:嫁接学习(分享竞赛大牛经验技巧)
竞赛推荐 | CVPR 2019 十大细粒度视觉识别挑战赛来袭,谷歌发来参赛征集令!
竞赛推荐 | 快手 ICIP2019 移动视频修复挑战赛
竞赛推荐 | DAVIS Challenge:视频目标分割挑战赛(CVPR2019)
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

觉得有用麻烦给个好看啦~




