CVPR2019人脸防伪检测挑战赛Top3论文代码及模型解析
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
来源:知乎
链接:https://zhuanlan.zhihu.com/p/69542283
本文经作者授权转载,未经允许,不得二次转载
赛事简介

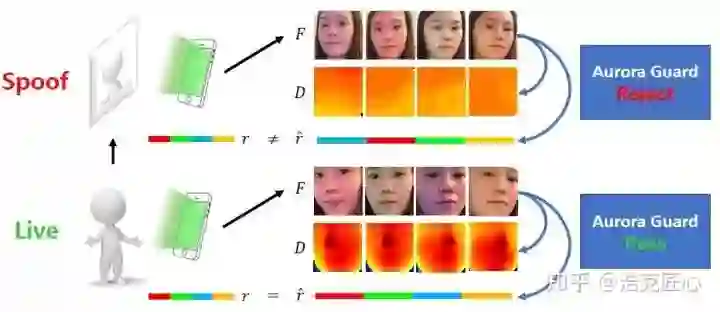
衡量指标
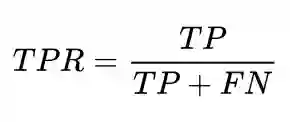
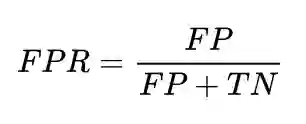
比赛数据集
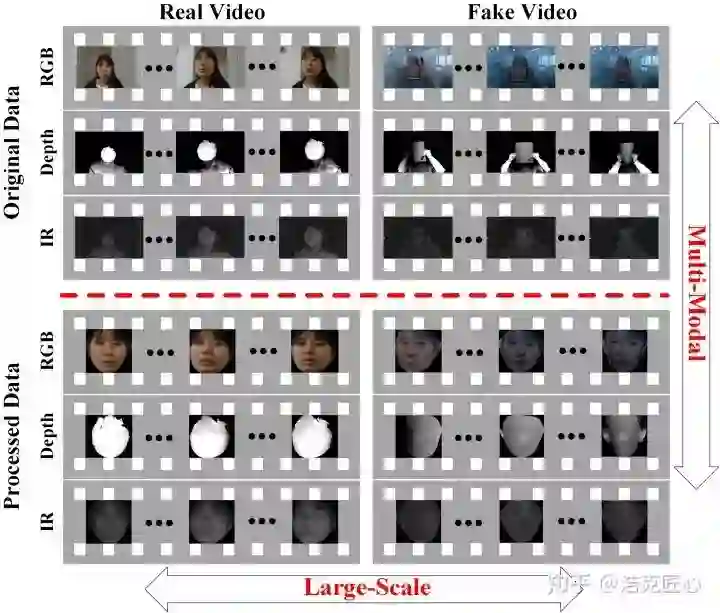
Top3团队及参赛模型介绍

冠军:Visionlabs -俄罗斯明星面部识别初创公司
VisionLabs是俄罗斯的一家专注于人脸识别、物体识别、增强现实和虚拟现实的公司,是全球视觉识别市场的领导者。
这家公司充分发挥了战斗民族的数学天赋(雪地里能格斗,回屋里能解题,能文能武。。),其技术团队由计算机视觉和机器学习专家组成,拥有独家开发的最先进的算法和技术。
VisionLabs处理了俄罗斯和独联体几百万摄像头中的数据流。占据俄罗斯和独联体人脸识别技术引进的80%份额。
美国情报局举办的全球人脸识别挑战赛(IARPA)上,包揽了识别速度和识别准确率两项比赛的冠军。美国情报局承认其人脸识别技术是世界第一。
VisionLabs 与 Facebook 和 Google 是合作伙伴关系,他们共同开发了一个开源计算机视觉平台(Facebook和谷歌为该项目提供了资金支持),这个平台整合了OpenCV和Torch两个最受开发人员欢迎的神经网络和人工智能库。他们与NVidia合作打造了人脸识别汽车钥匙。
CVPR2019的这次挑战赛上VisionLabs拿了冠军。公司长期目标是15到20年内用生物特征取代全俄罗斯的护照。

论文: Recognizing Multi-modal Face Spoofing with Face Recognition Networks 链接: http://openaccess .thecvf.com /content _CVPRW_2019/papers/CFS/Parkin_Recognizing_Multi-Modal_Face_Spoofing_With_Face_Recognition_Networks_CVPRW_2019_paper.pdf
代码:
AlexanderParkin/ChaLearn_liveness_challenge
链接:
https://github.com/AlexanderParkin/ChaLearn_liveness_challenge
模型简评:
模型基于经典的ResNet-34和ResNet-50做backbone,加入了SE模块。
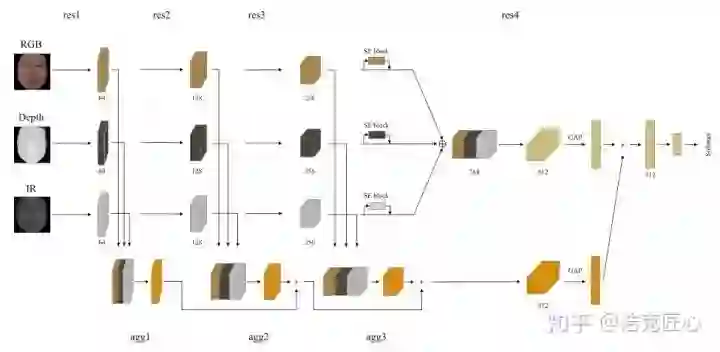
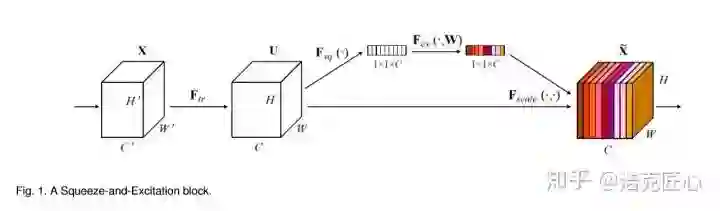
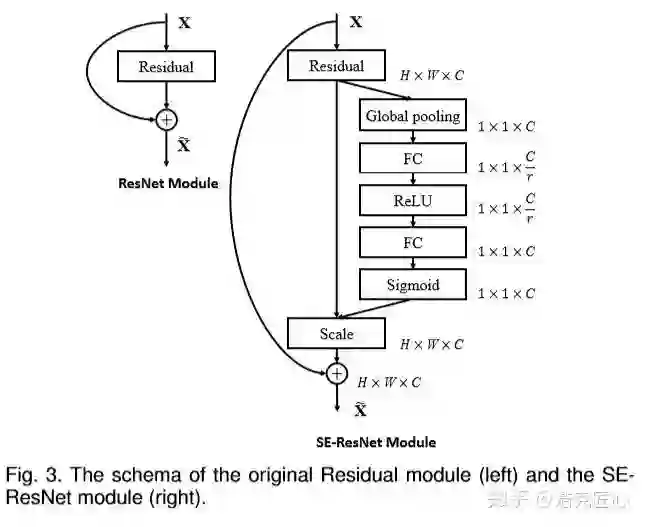

一系列技巧,让冠军的方案TPR@FPR=10-4已经无限接近100%;但是,这个模型并不是完美的,因为网络复杂,子模型众多,还有SE模块这种子结构增加了系统复杂性,使得它准确率出色,速度却比较尴尬,不能达到实时。这也是该团队下一步的工作重点。
亚军:上海阅面科技有限公司-中国视觉AI新秀
阅面科技是上海交大AI博士赵京雷的初创公司,成立于2015年的上海。
定位明确,致力于在低功耗AI芯片端进行视觉AI应用的开拓,拥有一系列行业领先的核心技术。
核心研发团队由来自阿里、百度、以及卡内基梅隆大学的顶尖人工智能研发人员组成。

论文: FaceBagNet: Bag-of-local-features Model for Multi-modal Face Anti-spoofing 链接: http://openaccess.thecvf.com/content_CVPRW_2019/papers/CFS/Shen_FaceBagNet_Bag-Of-Local-Features_Model_for_Multi-Modal_Face_Anti-Spoofing_CVPRW_2019_paper.pdf
代码:
SeuTao/CVPR19-Face-Anti-spoofing
链接:
https://github.com/SeuTao/CVPR19-Face-Anti-spoofing
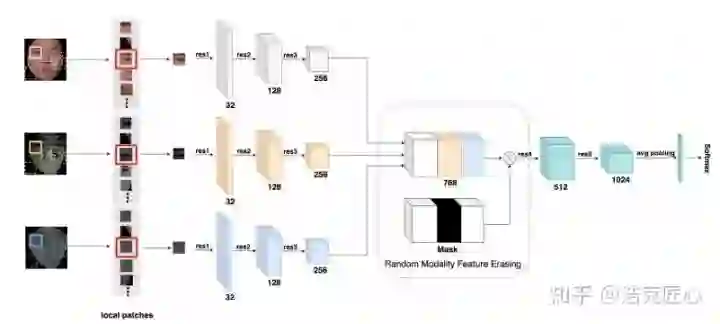
模型简评:
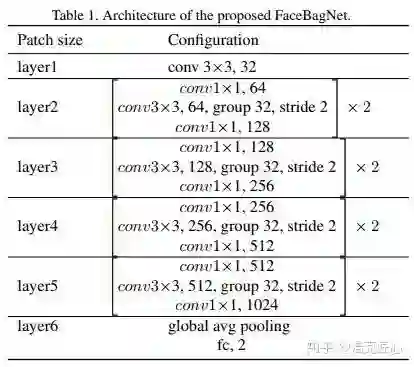
季军:英特尔公司+华科大
英特尔,没什么好说的,老牌美企,半导体行业的常青树,对深度学习领域不断投注资本(并购狂魔)。这次的季军来自位于上海的亚太研发中心,鉴于英特尔长期致力于和国内高校进行合作研究,论文也属名了华科大。
论文: FeatherNets: Convolutional Neural Networks as Ligh as Feather for Face Anti-spoofing 链接: https://arxiv.org/pdf/1904.09290.pdf
代码:
https://github.com/SoftwareGift...
链接:
https://github.com/SoftwareGift/FeatherNets_Face-Anti-spoofing-Attack-Detection-Challenge-CVPR2019
模型简评:

主要是替代全局平均池化GAP(Global Average Pooling)。
GAP被众多state of the art 目标检测网络采用,比如ReasNets,DenseNet,MobileNetV2,ShuffleNetV2,非常主流,适合降维和防止过拟合。但是在人脸相关的任务中,GAP对准确性却容易造成负面影响,主要原因在于其中的“equal importance”不适合人脸任务。为什么呢?简而言之,人脸图像不同于一般的目标检测图像,中心区域应该比边缘区域享有更高的权重,GAP是无法做区域权重区分的。能做到这一点的,一个可能选择是全连接层,但是会大量增加模型参数和过拟合的风险,不可取。
作者选用了(DWConv)Depthwise convolution layer来解决这个问题,读者会觉得有点儿眼熟,因为在2018年有一篇论文“Mobilefacenets: Efficient cnns for accurate real-time face verification on mobile devices. ”,里面就论证了Global Depthwise Convolution (GDConv) layer对于人脸任务的有效性。
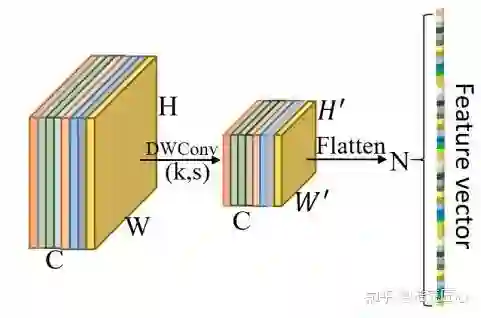
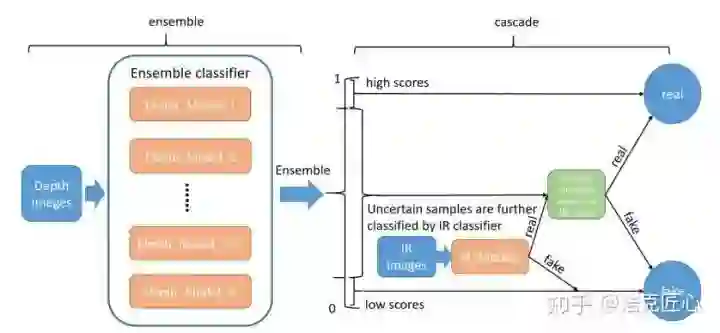
结语
参考文献
[1] ChaLearn Face Anti-spoofing Attack Detection Challenge@CVPR2019,link
[2] Shifeng Zhang, Xiaobo Wang, Ajian Liu, Chenxu Zhao, Jun Wan, Sergio Escalera, Hailin Shi, Zezheng Wang, Stan Z. Li, " CASIA-SURF: A Dataset and Benchmark for Large-scale Multi-modal Face Anti-spoofing ", arXiv, 2018 PDF
[3] Aleksandr Parkin et al, "Recognizing Multi-modal Face Spoofing with Face Recognition Networks" (1st place)
http://openaccess.thecvf.com/content_CVPRW_2019/papers/CFS/Parkin_Recognizing_Multi-Modal_Face_Spoofing_With_Face_Recognition_Networks_CVPRW_2019_paper.pdf
[4] FaceBagNet: Bag-of-local-features Model for Multi-modal Face Anti-spoofing (2nd place)http://openaccess.thecvf.com/content_CVPRW_2019/papers/CFS/Shen_FaceBagNet_Bag-Of-Local-Features_Model_for_Multi-Modal_Face_Anti-Spoofing_CVPRW_2019_paper.pdf
[5] Peng Zhang et al, "FeatherNets: Convolutional Neural Networks as Ligh as Feather for Face Anti-spoofing"(3rd place) https://arxiv.org/pdf/1904.09290.pdf
[6] Squeeze-and-Excitation Networks https://arxiv.org/abs/1709.01507
-End-
*延伸阅读
CV细分方向交流群
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群(已经添加小助手的好友直接私信),更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台
觉得有用麻烦给个在看啦~



