香港中文大学胡枭玮:用于阴影检测的 DSC 特征

雷锋网AI研习社按:阴影检测向来是计算机视觉中基础且富有挑战性的问题——对于一张输入图像,我们通过生成二进制图像来标记阴影区域,阴影区域的检测为进一步获取图像中的光照情况、物体的形状与位置,以及摄像机的参数提供了可能。与此同时,阴影的存在也为计算机视觉中进一步理解图像的算法,例如物体的检测与跟踪,带来了障碍。
来自香港中文大学的胡枭玮采用了提取 DSC 特征的方式来解决这个问题,他在近日的 AI 研习社大讲堂上向我们分享了具体操作思路。
公开课回放地址:
http://www.mooc.ai/open/course/523
分享主题:用于阴影检测的 DSC 特征
分享提纲:
阴影检测相关工作与研究动机
DSC模型介绍
实验结果与讨论
最新工作---阴影去除
雷锋网AI研习社将其分享内容整理如下:
大家好,我是胡枭玮,来自香港中文大学。很荣幸能和大家介绍一下我们的工作「Direction-aware Spatial Context Features for Shadow Detection」。这篇文章已经被 CVPR2018 收录,并做口头报告 (Oral)。
作为计算机视觉中的基础问题,最近一些年来,阴影检测已经被广泛的研究。
最近的两个工作是基于深度学习的方法来检测阴影,目前看来已经达到了比较好的性能,这两种方法——scGAN 与 stacked-CNN,分别发表在了 2017 年的 ICCV 与 2016 年的 ECCV 上,主要是通过深度神经网络从大量的数据样本中自动学习特征,用于检测阴影区域。
然而,它们仍然可能将黑色的物体误检为阴影,或者漏掉一些不太明显的阴影区域。

在这幅漫画中,左边的这个人举着刀子指向右边的人,可能会让我们以为左边的家伙是一个杀手,但如果我们观察整幅图像,就会发现右边的这个人才是真正的杀手。在同一幅图画中,我们看到了两个完全不一样的故事。
在检测阴影区域的时候,我们也面临类似的问题。

正如这幅图展示的这样,如果只从局部区域来判断它是不是阴影,这个问题是十分困难的。
我们并不知道这个黑色区域到底是一个阴影还是一个黑色物体,所以我们需要通过分析更大的区域或者周围区域来决定它是否是阴影——换句话说,阴影检测需要去理解全局图像的上下文信息。
除此之外,我们还需要分析不同方向的上下文信息。

如图所示,当我们比较 A 区域与 B 区域的时候,由于 B 区域要比 A 区域亮许多,给了我们一个很强烈的指示:A 是阴影区域。
可是当我们去比较 C 区域和 A 区域的时候,我们并不能从 C 区域来判断 A 是不是阴影(C 区域与 A 区域同样都是阴影,且 C 区域更暗)。所以,为了进一步理解阴影,我们提出从不同方向的上下文特征来分析图像。

比如在这幅图中,阴影投射在不同颜色的背景上面。
如果我们使用之前的方法,位于黄色区域的阴影可能会检测不到。但是,当我们方向性地分析图像上下文信息,就可以从图像的上面或者下面来传播阴影信息,同时可以使用左边或右边的信息来推断阴影区域。
因此,我们的方法可以有效的检测到位于黄色区域的阴影。
什么是 spatial context features?
为了传播图像的全局上下文信息,我们使用空间 RNN 来获取空间上下文特征,该特征叫做 spatial context features。先输入一张特征图(这个特征图可以是卷积神经网络中任意的一张特征图),再从四个方向独立的传播信息,用来获得局部的空间上下文特征。
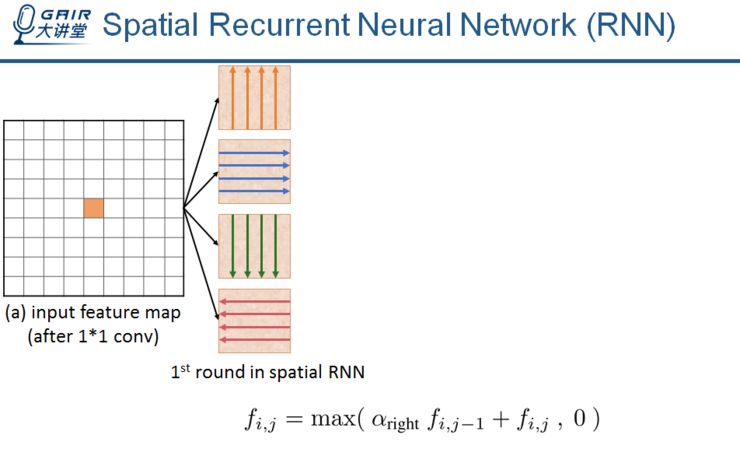
以向右传播为例,每一个特征值都会被它左边的这个值更新。
在这个更新的过程中,信息在整张特征图上从左到右传播(公式中的权值 alpha right 是共享的并且可以自动学习的)。通过聚合四个方向的结果,对于每一个像素点来讲,就可以获得它所在的行和列的信息。
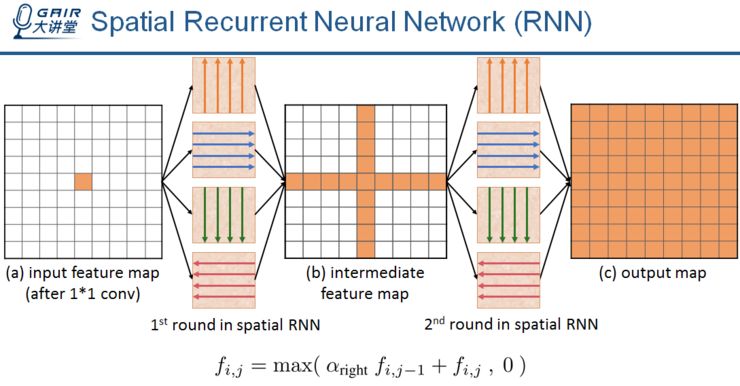
通过两次这样的操作,每个像素点就可以得到全局的信息。
具体来说,就是将一个卷积神经网络中的 2D 特征图作为输入,首先经过一个 1 乘 1 的卷积操作,之后是四个方向的 recurrent translation。接着我们将四个结果综合起来作为中间的特征图,然后重复上述过程,最终得到全局的空间上下文特征。
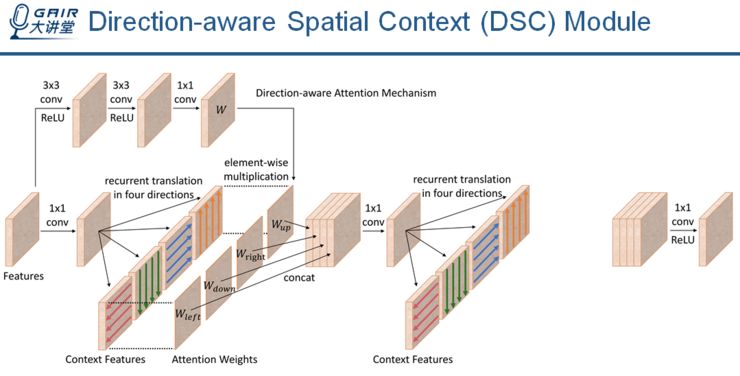
为了进一步方向性的分析空间上下文特征,我们采用的是 attention 机制,来生成一组权值,并且将他们分成四张权值图,分别通过点对点的方式,乘上四个方向的空间上下文特征。
这些权值会在两次 recurrent translation 中共享(且可以跟整个深度学习网络一起进行训练),因此,我们可以通过在不同方向上选择性的使用空间上下文特征来得到 direction-aware spatial context feature,这个结果我们叫做 DSC 特征。
至于获取该特征的过程被称作 DSC 模块。
如何训练网络?
我们将在深度神经网络中采用多个 DSC 模块:对于一张输入图像,首先使用卷积神经网络提取不同分辨率下的特征图像(「特征金字塔」),位于低层的特征图像分辨率高,能够提取到图像的细节信息,但是缺乏语义信息;位于高层的特征图像分辨率低,可以提取到图像的语义信息,但是缺乏图像细节信息。
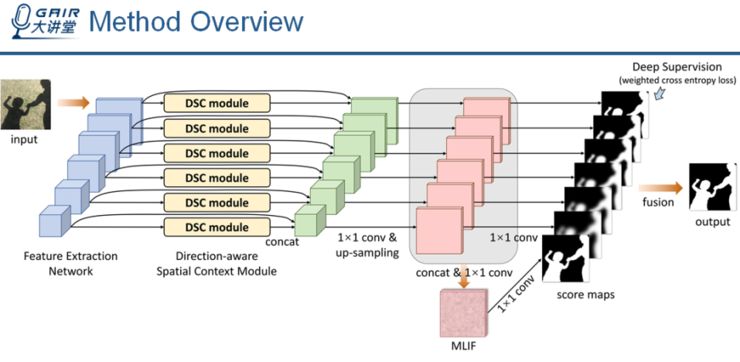
我们将 DSC 模块应用到每一层特征图上,并将得到的 DSC 特征与原来的特征相连接,然后放大这些特征图像到原图大小。
这些放大之后的特征图像组合为 Multi-level integrated features(简称为 MLIF),之后我们使用包括 MLIF 特征在内的每一层特征来预测阴影区域,最后将每层的预测结果综合起来,作为网络最终的输出结果。
整个网络是在 SBU training set 上面训练的,训练好的 model 会在 SBU testing set 以及 UCF testing set 上进行测试。
在自然图像中,阴影区域的面积往往大于非阴影区域的面积,如果我们只是以提高整体的训练精度为目标,结果会倾向于匹配占的面积大的非阴影区域。
因此,我们设计了 weighted cross entropy loss 来训练网络——它由 L1 和 L2 两部分组成。

L1 用来平衡阴影区域与非阴影区域的比重,如果阴影区域的面积小于非阴影区域,会惩罚误检的阴影区域多一些。
L2 帮助网络去学习不容易识别的类型(这里主要指阴影或非阴影)。如果正确识别的阴影区域较小,那么他的损失函数的权值就会变大,反之亦然。
在测试过程中,我们使用 MLIF 层以及 fusion 层的均值作为最后的结果。并且使用 CRF 作为后处理,用来改进检测到的阴影区域的边界。
这里是我们的方法与最新的两个阴影检测方法的比较结果。
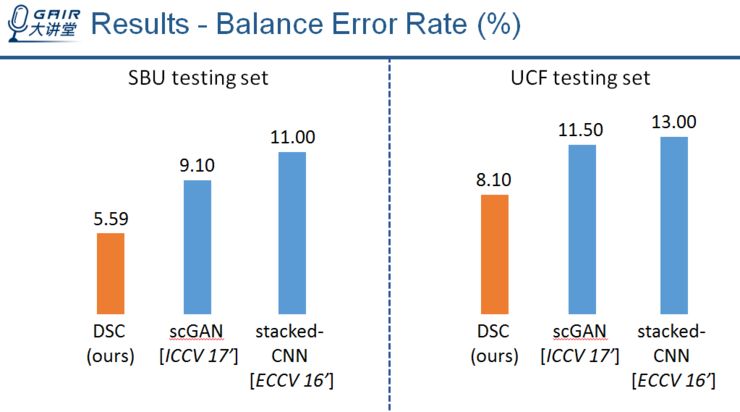
可以看到,我们的方法在两个阴影检测数据集上都取得了最好的效果。
阴影检测效果展示
接下来,我来展示一些视觉比较结果。
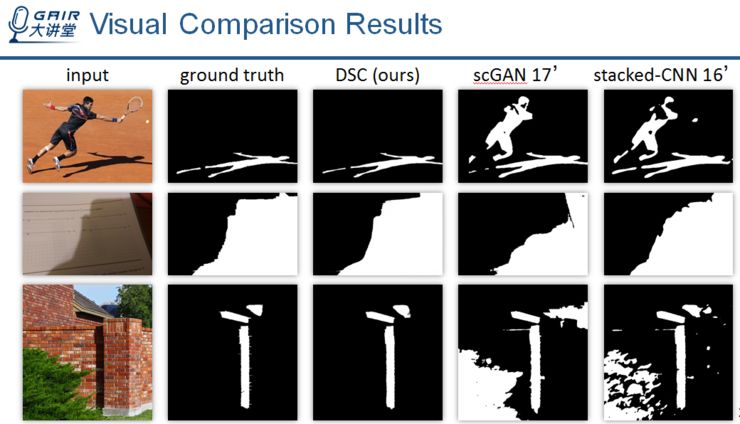
图中从左到右分别对应:输入图像,ground truth(人工标注的数据),我们的结果,以及其他方法的结果。
可以看到,我们的方法能够有效的识别出黑色的物体,同时检测到位于不同颜色的背景上面的阴影,相比之下,其他方法可能会失败。
这是另一组比较结果。
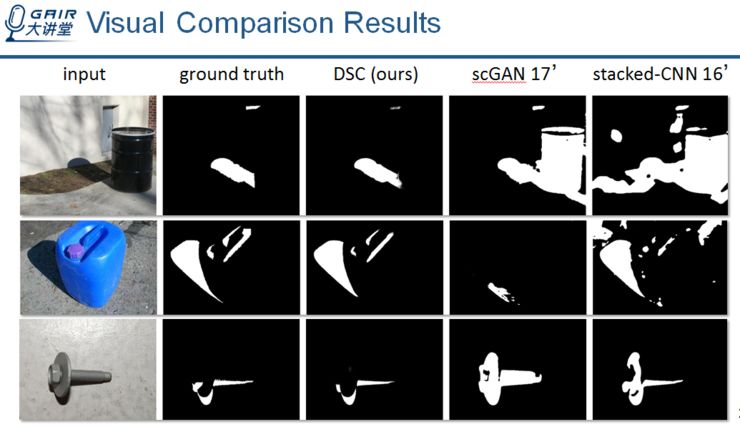
通过方向性的分析图像上下文特征,我们的方法可以区分出黑色的桶与阴影区域,以及减少漏检区域等等。
这是一个评价网络设计的实验。
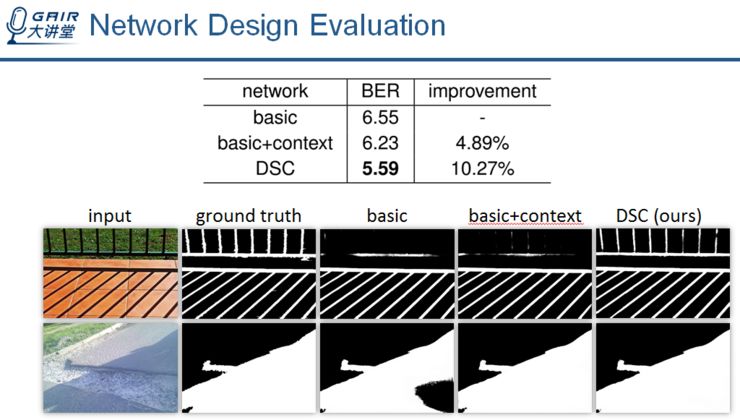
图中 Basic 指的是去除掉所有 DSC 模块的网络,而 basic + context 则指考虑上下文信息,但忽略掉不同方向上下文的影响。
可以看出,通过考虑 DSC 特征,能够有效的提高检测精度。
这里展示一下更多的阴影检测结果。

图 A 中的阴影投射到不同颜色的背景上面;图 B 有一些小且零碎的阴影;图 C 中阴影区域与非阴影区域的边界不清晰;图 D 是一些不规则的阴影。
这些阴影通过我们的方法可以比较准确地检测出来。
然而,该方法在一些情况下可能会失效。
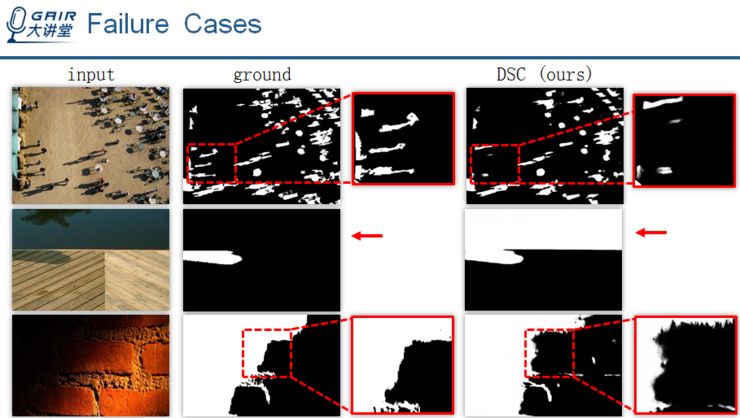
比如,第一幅图拥有许多小的阴影区域;第二幅图拥有一块大的深色区域,然而缺少上下文信息;第三张图主要是 soft shadow,它与非阴影区域的差别不是很大.
阴影去除机制
近期我们将网络用于阴影去除,在两个阴影去除数据集上取得了最好的效果。

为了将该网络用于阴影去除,我们先让网络预测 shadow-free image(去除掉阴影的图像),再接着用 Euclidean loss 训练整个网络。
同时,我们发现在现有的阴影去除数据集当中,输入图像与 ground truth 的非阴影区域存在颜色和亮度不一致的问题。
为了准备阴影去除的训练数据,人们通常会先对有阴影的场景拍一张照片,然后拿掉产生阴影的物体,再拍一张照片。在这两次拍照的过程中,环境光照与照相机的曝光参数都可能会发生变化,导致训练样本的颜色与亮度不完全一致。
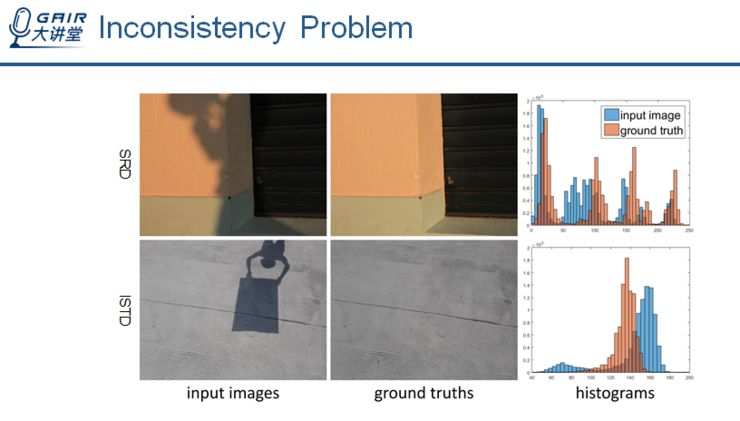
这两张图是分别从 SRD 和 ISTD 两个公开数据集中找的样本,可以从颜色直方图中清楚看到输入图像与 ground truth 之间的偏差。
现有的基于深度神经网络的方法,会去学习匹配 ground truth,因此,如果直接用这些图像去训练,网络可能会生成有颜色偏差的图像。

为了解决这个问题,我们设计了颜色补偿机制——对于一组训练样本,我们通过最小化输入图像与 ground truth 非阴影区域的误差,来学习一个颜色转换函数,然后将这个函数应用到整幅 ground truth 图像上面来调整颜色误差。
在实验中我们发现,只要使用简单的线性函数就可以学习的很好(该函数在公式中用 Tf 表示),也就意味着我们可以使用最小二乘法计算函数中矩阵 M alpha 的参数。
图中的 R,g,b 分别对应图像的红绿蓝三个通道的颜色值。
实际上每张训练样本都有一个转换函数,由于每张拍摄样本的偏差可能都不一样(每张样本都有各自的颜色转换函数),所以我们将学到的颜色转换函数应用到原始的 ground truth 上,就可以得到与输入图像非阴影区域的颜色亮度相匹配的结果。

我们分别在 SRD 与 ISTD 上训练与测试网络,并且通过计算整幅图像(包含阴影区域与非阴影区域)的 Euclidean loss 来优化整个网络。
在测试的过程中,我们采用 MLIF 与 fusion 层结果的平均值作为最终结果。
阴影去除效果展示
接下来我会展示一些视觉比较结果。
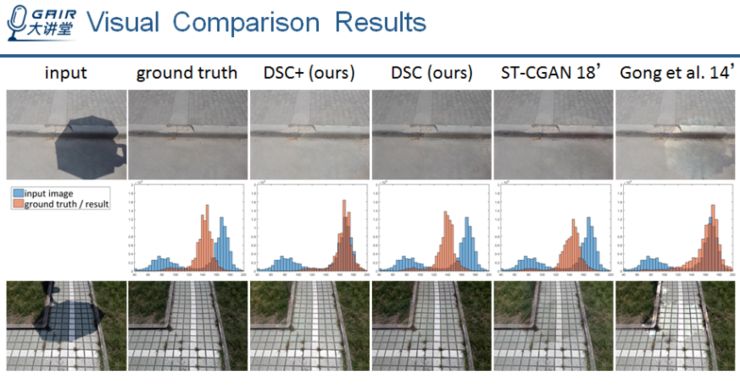
第一行,从左到右分别对应的是:输入图像、ground truth、DSC(我们的结果)、DSC+以及其他方法的结果。其中 DSC+是用调整之后(颜色转换函数)的训练样本训练的,而 DSC 则是使用原始的训练样本训练网络。
第二行则是:每张图片(红色)与输入图像(蓝色)的颜色直方图对比。可以看到,DSC+可以生成和输入图像颜色与亮度更匹配的结果。而 DSC 以及 ST-CGAN 这些基于深度神经网络的方法,直接用原始的 ground truth 训练,生成的图像与原始的 ground truth 更接近,与输入图像存在颜色偏差。
第三行是另一组结果。
可以看到,我们方法能够有效的去除阴影,同时保留非阴影区域的颜色。

这是在另一个数据集上面的测试结果,相比之下,其他方法可能会改变非阴影区域的颜色,或者不能有效去除阴影区域。
然后我们比较了 DSC 与 DSC+和原始的 ground truth (In) 与调整之后的 ground truth (Tf(In)) 的数值结果。
可以看到,DSC+能够明显减少与调整后没有阴影的图像的误差。
我们继续来看更多展示结果。

我们的方法可以去除在不同背景上的阴影区域 (如图 AB),也可以去除如图 C 中墙砖上不规则形状的阴影,以及图 D 中复杂背景下的阴影。

或者我们需要更多的训练样本来解决这些问题。
总的来说,在这项工作中,我们通过方向性地分析图像空间上下文信息来进行阴影检测与去除,并在两个阴影检测数据集以及两个阴影去除数据集上都达到了顶尖的性能。
我们公布了文章的代码与结果(https://github.com/xw-hu/DSC),同时在个人主页上传了更多相关的资料(https://xw-hu.github.io/ )。
接下来我们还会继续深入研究这个方向,建立更大、更复杂的数据集。如果大家对这个项目感兴趣,可以帮助我们收集数据或者标记图像,欢迎直接联系我(邮箱:xwhu@cse.cuhk.edu.hk),我们会有相关的经费支持给到大家。
以上就是本期嘉宾的全部分享内容。更多公开课视频请到雷锋网AI研习社社区(https://club.leiphone.com/)观看。关注微信公众号:AI 研习社(okweiwu),可获取最新公开课直播时间预告。



