CVPR | 基于级联生成式与判别式学习的乳腺钼靶微钙化检测


关键词:ASN, T-test loss, Huber's loss


导读
本文是计算机视觉领域顶级会议CVPR 2019入选论文 《基于级联生成式与判别式学习的乳腺钼靶微钙化检测(Cascaded Generative and Discriminative Learning for Microcalcification Detection in Breast Mammograms)》的解读。
该论文由深睿医疗与北京大学王亦洲课题组合作,是其自研算法在智慧医疗领域的应用,针对乳腺钼钯中的微钙化(直径<=1cm)检出问题提出了结合生成式和判别式模型的新思路。钙化检测对于乳腺癌的早期诊断十分关键,根据美国放射学院第五版BI-RADS标准,可疑恶性钙化点通常直径在1cm以内。因此,研究微钙化的检出算法具有重要的临床意义。
乳腺钙化检测
乳腺癌是目前女性最常见的恶性肿瘤。每年发病率不断增高,影像学对于乳腺癌的早期发现及准确诊断十分重要。钙化点的出现是乳腺癌最重要的征象之一,而形态不同的钙化簇、肿块都以早期的钙化点不断发育聚集而成,因而可以通过简单的聚类方法将其识别。因此,钙化点的检出是乳腺癌诊断,尤其是早期诊断中最重要的部分,为诸如肿块、钙化簇检测等问题提供了基础。
由于钙化点通常体积小于1立方毫米,呈现在钼靶图像上,且往往不超过14个像素;此外,钙化点的亮度、对比度、形状变化很大。因此,现有的钙化点检测算法 [1-3] 面临特征较难提取的问题。
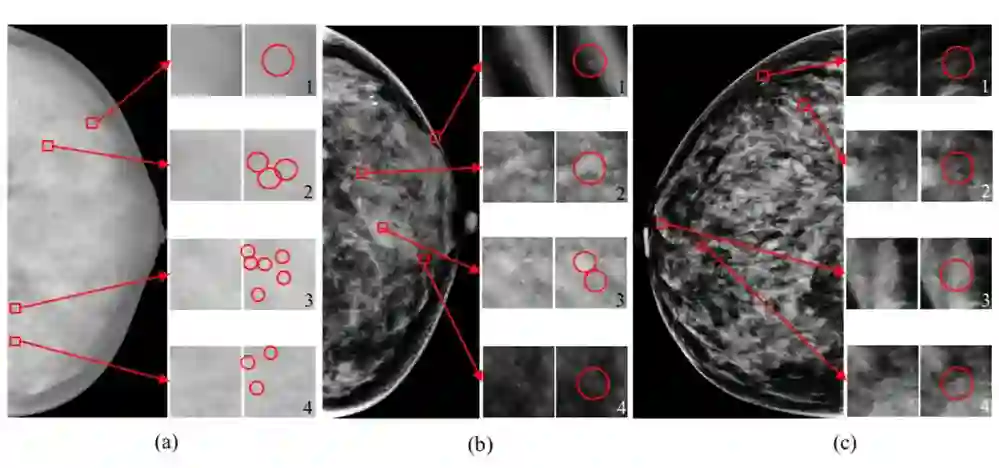
钼靶图像中的钙化点示意图
(a), (b), (c) 中的左边分别表示原始图像,右边是钙化点放大的图像。(a) 来自INBreast数据集 [12],(b), (c) 来自私有数据集
另一方面,真实数据中只有少量样本含有钙化点,导致数据呈现样本不平衡问题。因此,在训练中,分类器往往会过度拟合负样本,导致正样本的检出格外困难。
异常检测框架
由于钙化点形状不规律,且相对于非钙化样本数量较少,因此,我们可以将这一问题转化为有监督的异常检测问题,即将钙化点作为异常点。基于这个先验知识,我们试图拟合正常样本图像,而将钙化点当成异常点并试图将这部分检测出来。为此,我们提出了连续的生成和判别学习框架,主要分为两步:第一步是异常分离网络(Anomaly Seperation Network,ASN),借助重构网络强大的表示能力和T-test损失函数来帮助我们将正负样本分开;第二步是假阳性消除(False Positive Reduction,FPR),来消除不属于钙化但形态上具有异常的区域,比如血管钙化、锯齿钙化等。
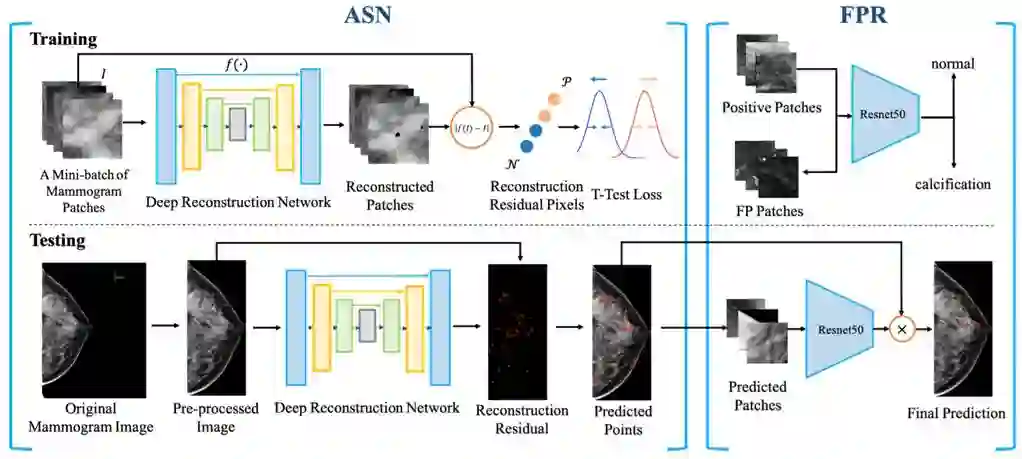
方法示意图
该方法包括两步:(1) ASN (2) FPR
ASN即通过Anomaly Seperation Network去检出候选的钙化点,而FPR通过二值分类网络来做进一步假阳性消除。在ASN的训练阶段,我们通过U-Net来重构钼靶的patch图,并用T-test 损失函数来将正常样本和钙化样本分开。在FPR中,我们利用ResNet-50来做分类,而样本为ASN中检出的候选钙化点中的负样本和正样本。
异常分离网络(ASN)
由于深度重构网络被证明在多种图像任务中能够稳定地表现良好,因此我们采用深度重构网络来对钼靶图像进行重构。具体地,我们采用U-Net [6] 来进行像素点的重构。在跳跃式传递中,我们用3个下采样和3个上采样阶段。每个阶段包含了3个卷积层。采用这样的网络设计有如下三点好处:
首先,下采用操作可以带来有效地感受野大小,这在像素的重构和图像一致性上方面是有优势的。
我们每次只按照8倍的幅度来进行下采样。这是因为钙化点大小通常在14个像素以内,因此可以避免过多地信息损失。
跳跃式连接可以利用浅层的特征,进而帮助提升准确率。
我们用f (·) 重构网络函数。给定一张图像I,重构的残差值定义为:

我们希望能够重构出负样本(正常点),而把正样本当成异常值检测出来。因此,我们希望对这两类样本的重构值分布不同,为此,我们提出如下T-test损失函数来让两者分布不同。

与异常检测的联系

假阳性消除(FPR)
ASN可以较好地重构负样本,并把钙化点当成异常值检测出来。然而,在乳腺钼靶中,除了乳腺钙化点之外,还有其他种类的钙化,它们不属于乳腺钙化点。如下图所示,左边patch中的绿色长方体是血管钙化,通常是很多钙化点的组合。而对于ASN来说,它们也异常于负样本,因此被当成异常值被检测出来。但实际上,它们和乳腺钙化点在形态等特征上有较大的不同,如下图右边的patch上的橘黄色圆圈所显示的那样。也就是说,它们和钙化点并不难区分。因此,我们提出深度分类网络来讲其它类型的钙化和乳腺钙化点区分开来,从而完成假阳性的消除。

左:血管钙化;右:乳腺钙化
更具体地,我们将 ResNet50 [8] 作为分类网络。对于每一个patch中的连通区域,我们将其中心作为预测的位置,并计算周围像素重构误差值的和,我们将其记为ASN分数。对于每一个ASN的patch,我们将其大小从原来的56x56调整为224x224,并将其输入到ResNet50中。我们使用ASN得分和FPR得分的乘积作为其最后得分。
实验设置
我们通过将数据格式为DICOM的原始钼靶数据的每个像素值线性映射成0-255,从而转化为8-bit灰度图像。我们应用Otsus方法 [9] 来分割乳腺区域,并将其钼靶图像中的背景去掉。我们采用Adam优化算法,初始化的学习率为0.0001, 伴随着10^(-4) 的参数下降。梯度的平均值和平方值分别为0.9和0.999。β 设为0.8,正则化参数λp 和λn 分别设为1和0.1。在训练阶段,钼靶图像被调整为112 x 112的大小。我们将这些patch图像放入到ASN网络中进行训练,我们将正负样本比例控制在1:1,以提取出更多的候选patch。
FPR首先在ImageNet上预训练,我们用SGD进行训练,学习率为0.001。所有被ASN检出的候选钙化点和真正的钙化点被放入到ResNet 50中进行再一次训练。
实验结果
我们在公开数据集InBreast [5] 和私有数据集上面,与Faster RCNN [4] 和U-Net [6] w FPR对比了结果。InBreast数据集包括115个病例,410张钼靶图像,6880个已标注的钙化点。表1中汇报了5折交叉验证的结果。可以看到,本文的方法击败了目前最有效的几种钙化检测算法。
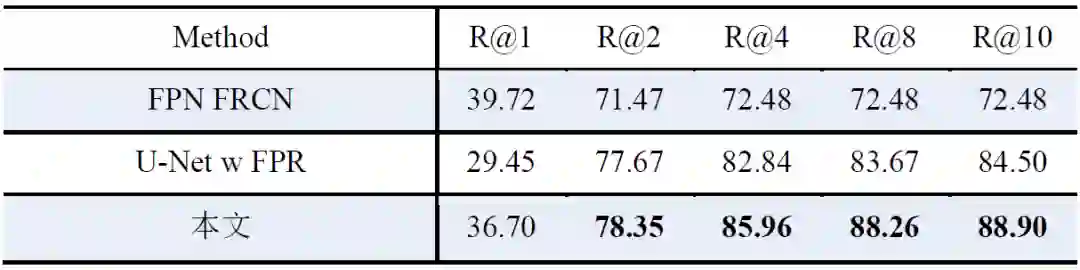
表1 在InBreast数据集的结果(%)
为了进一步验证算法的有效性,本文建立了一个私有数据集,由439个病例,1799张图像组成,由两位10年资以上的放射科医生,共同标记了7588个钙化点。本文随机选择了339个病例1386张图像共计5479个钙化点作为训练样本,50个病例208张图像1129个钙化点作为验证集,50个病例205张图像980个钙化点作为测试集。表2展示了私有数据集的对比结果,可以看到本文的方法远远超越了主流的检测算法。
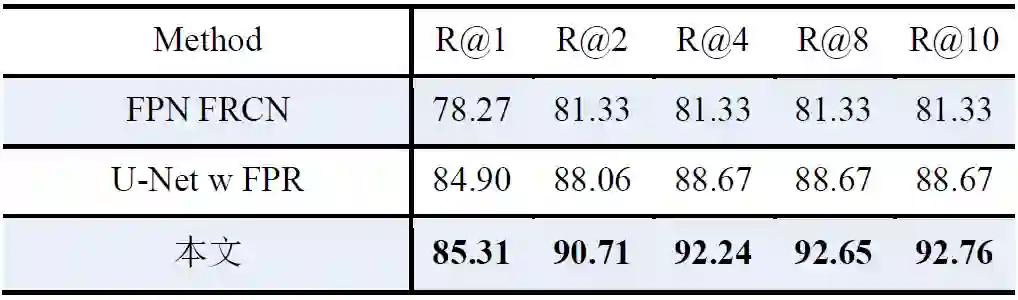
表2 在私有数据集的结果(%)
为了说明我们的相比较U-Net,我们模型的优势不是FPR导致的,我们比较了U-Net和ASN的结果。
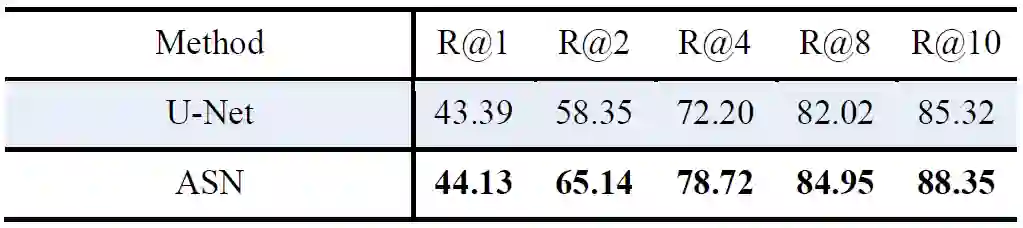
表3 在InBreast数据集的结果(%)(无假阳性消除)
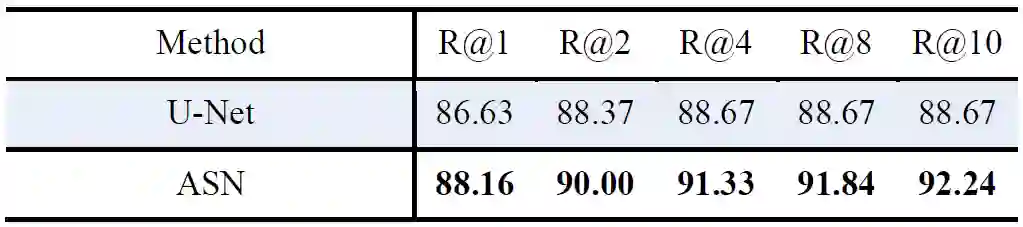
表4 在私有数据集的结果(%)(无假阳性消除)
我们可以比较我们的模型和其它方法在检出率随着假阳性变化的曲线,如下图所示。可以看到,在相同的假阳性下,ASN要比U-Net具有更高的检出率。加上假阳性控制这一步后,检出率会得到进一步的提升。
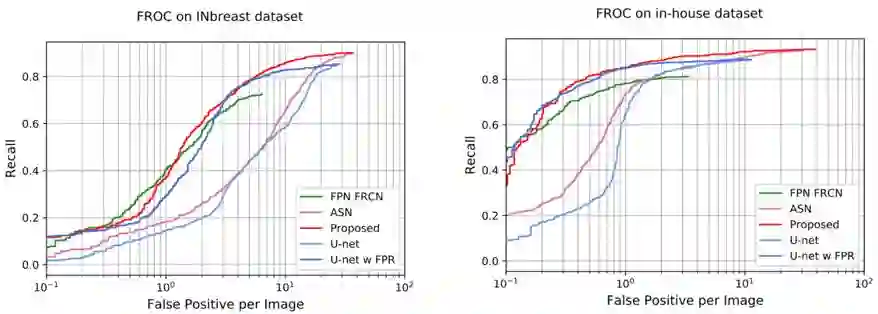
各种方法检出率曲线比较
左图:INBreast上的结果;右图:私有数据集的结果
此外,我们展示了一些用各种方法检出的钙化点的例子,如下图所示。由于一些钙化点不超过5个像素点,FPN中只能做到在处理后的图像清晰度为原始图像的1/4时才能检出,但这样图像过大以至于超过内存容量。因此我们从下图中看出,前三个例子FPN都未能检出钙化点。而下图的最后一行显示了血管钙化,通过假阳性消除这一步,我们的方法能够成功将其排除。
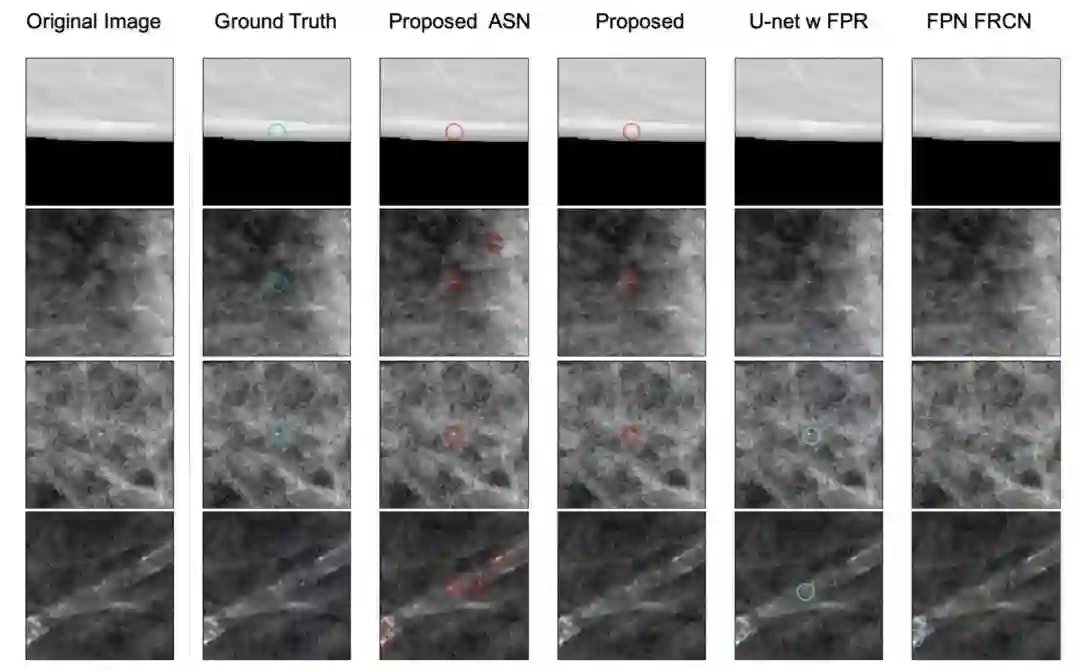
各个方法在一些例子上的比价
第二列为真实情况,第三、四列分别为ASN模型和我们提出的ASN+FPR,第五列为U-net w FPR,第六列为FPN FRCN
参考文献:
[1] Viola, P., Jones, M.: Rapid object detection using a boosted cascade of simple features. In: IEEE Computer Society Conference on Computer Vision and Pattern Recognition. (2001) 511.
[2] Bria, A., Karssemeijer, N., Tortorella, F.: Learning from unbalanced data: A cascade-based approach for detecting clustered micro-calcifications. Medical Image Analysis 18 (2014) 241-252.
[3] Lu, Z., Carneiro, G., Dhungel, N., Bradley, A.P.: Automated detection of individual.
[4] Ren, S., He, K., Girshick, R., Sun, J.: Faster r-cnn: towards real-time object detection with region proposal networks. In: International Conference on Neural Information Processing Systems. (2015) 91-99.
[5] Inbreast: toward a full field digital mammographic database. Academic Radiology
19(2) (2012) 236-248.
[6] Ronneberger, Olaf, Philipp Fischer, and Thomas Brox. "U-net: Convolutional networks for biomedical image segmentation." International Conference on Medical image computing and computer-assisted intervention. Springer, Cham, 2015.
[7] Huber, Peter J. "Robust statistics." International Encyclopedia of Statistical Science. Springer, Berlin, Heidelberg, 2011. 1248-1251.
[8] He, Kaiming, et al. "Deep residual learning for image recognition." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
[9] Otsu, N. (1979). A threshold selection method from gray-level histograms. IEEE transactions on systems, man, and cybernetics, 9(1), 62-66.
*本文部分内容摘自公众号“深睿deepwise”文章:深睿研究院8篇论文入选人工智能顶级会议2019,图像识别与医学影像分析等技术实现了创新性突破
IEEE Conference on Computer Vision and Pattern Recognition(IEEE CVPR)是计算机视觉领域国际顶级会议(CCF A类),每年举办一次。CVPR 2019将于6月16日在美国长滩市举行。

图文 | 孙鑫伟
Computer Vision and Digital Arts (CVDA)
About CVDA
The Computer Vision and Digital Art (CVDA) research group was founded in 2007 within the Institute of Digital Media at Peking University led be Prof. Yizhou Wang. The group focuses on developing computational theories and models to solve challenging computer vision problems in light of biologically plausible evidences of visual perception and cognition. The primary goal of CVDA is to establish a mathematical foundation of understanding the computational aspect of the robust and efficient mechanisms of human visual perception, cognition, learning and even more. We also believe that the marriage of science and art will stimulate exciting inspirations on producing creative expressions of visual patterns.
近 期 热 点


— 版权声明 —
本微信公众号所有内容,由北京大学前沿计算研究中心微信自身创作、收集的文字、图片和音视频资料,版权属北京大学前沿计算研究中心微信所有;从公开渠道收集、整理及授权转载的文字、图片和音视频资料,版权属原作者。本公众号内容原作者如不愿意在本号刊登内容,请及时通知本号,予以删除。