跨语言notebook自动数据可视化:nteract数据探索器
编者按:Netflix数据可视化工程师、《D3.js in Action》作者Elijah Meeks介绍了nteract数据探索器的设计理念和主要功能。
我职业生涯的大部分时间花在设计和创建数据产品上——数据面板之类的分析应用,便于理解算法、数据集的数据可视化原型。相当一部分(但仍然不算多)时间花在开发一个名为Semionic的React数据可视化框架上,我的许多其他数据产品的图形部分使用了这个框架。
如果你只对nteract数据探索器的特性感兴趣,可以跳过下面几节,直接从如何使用数据探索器开始阅读。
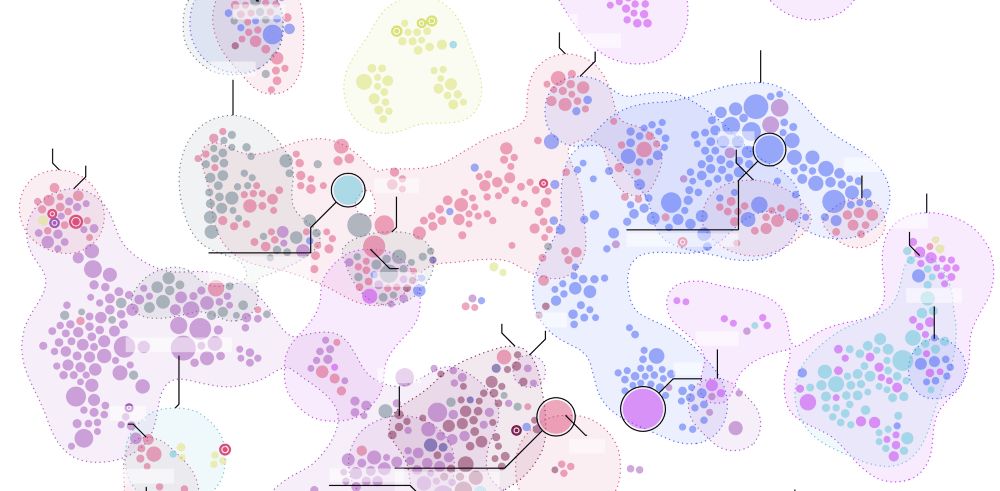
基于Semiotic可视化TSNE数据集 by Susie Lu
数据可视化主要有两个领域:应用和工具。在数据可视化的语境下,工具是指诸如D3这样的软件库,或者Tableau这样的平台,这些可视化工具让你可以创建数据产品,比如面板或报告。然而,数据可视化还有一个我直到最近以前都没怎么接触过的领域:自动数据可视化。所以当我为nteract平台开发一个数据探索器的时候,我很兴奋,想看看自己能够给这一数据可视化的重要领域贡献点什么。
问题空间
插入一张表格或其他结构化的数据集,然后循环不同视图,这就是自动可视化。例如,插入一张表格,然后你可以查看它的柱形图或饼图,希望不同的视图可以揭示数据中隐藏的东西。
某种意义上,所有用于探索性数据分析的数据可视化都具备自动模式。Tableau之类的商业智能(BI)工具让你通过试验不同的视图设计面板和报告。ggplot2接受期望的数据结构,然后返回美观的默认图形,让你可以相对简单地循环视图。
以上工具和nteract数据探索器的区别在于,数据探索器并不是为最终生成报告或面板而设计的。相反,它仅仅提供一组图形,让你可以概览notebook中的数据。notebook用户有各种创建数据可视化最终产品的方法,他们知道想要呈现和强调什么。数据探索器无意在这方面参与竞争。
目标
以恰当的方式总结数据。 不仅可以比较单独的行,还可以比较分组后的行,以突出分布和层级。
支持多样性的数据视图。 例如,折线图和柱状图用来描绘不同行的数值测度很不错,但在可视化边列表时完全用不上。类似地,如果你需要查看大量数据点,你会希望能看到两个测度的相关性密度,而不是单个数据点的分布。
封装组件以便其他查询界面复用。 比如,同样的可视化组件可以用于Netflix的内部SQL查询应用。
数据探索器使用了pandas实现的表格式数据资源表示法。这是一种简单的数据格式,其中包括:
列名和列类型(字符串、数字)
dataframe键
多种测度
表格式数据结构
另外,数据探索器设计时面向的数据规模是数百数据点,而不是数千乃至更多数据点。
为何基于Semiotic
碰巧我当时正开发这个基于数据模型的结构化视图和数据可视化方法的图表框架。和其他图标库不同,Semiotic没有<BarChat>(柱状图)或<PieChart>(饼图)这样的组件。相反,Semiotic使用frame表示不同数据结构共享的数据可视化方法。Semiotic包括三种frame:
<ordinalFrame>,用于柱状图、总结图、平行坐标图
<XYFrame>,用于散点图、折线图、hexbin图
<NetworkFrame>,用于力导向网络,桑基图、层次结构图
Semiotic的设计方式意味着实现多样性的图表相当容易。例如,<NetworkFrame>不仅可以用来显示力导向网络,还可以用来显示许多不同的面向拓扑的图标,包括dendrogram、矩形树图、桑基图、circle packing。
如何使用数据探索器
我们将使用世界幸福感报告作为样本数据集。你可以在nteract亲自尝试,或者通过mybinder在线浏览(可能需要30秒加载notebook):
https://hub.mybinder.org/user/nteract-examples-6lbp5cij/nteract/edit/python/happiness.ipynb
在notebook中进行以下配置以便使用数据探索器:
import pandas as pd
pd.options.display.html.table_schema = True
加载数据然后查看dataframe:
df = pd.read_csv(
"https://gist.githubusercontent.com/rgbkrk/a7984a8788a73e2afb8fd4b89c8ec6de/raw/db8d1db9f878ed448c3cac3eb3c9c0dc5e80891e/2015.csv"
)
df
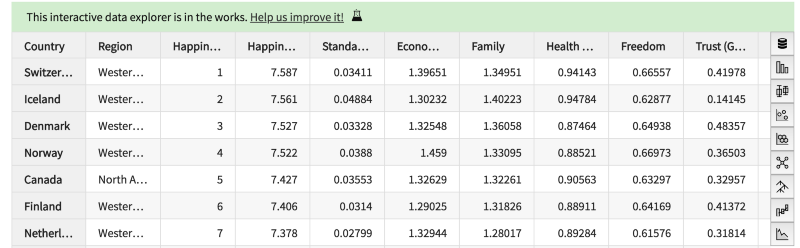
如上图所示,dataframe右侧出现了一些图标,点击这些图标可以切换不同的数据可视化模式。

柱状图、总结图、散点图、hexbin、网络图、层次结构图、平行坐标图、折线图
柱状图
第一个模式是柱状图。每个柱形都可以交互。不过出于清晰考虑,只有数值最高的那些柱形是彩色的。通过Metric(测度)下拉菜单可以指定不同的测度作为纵轴。
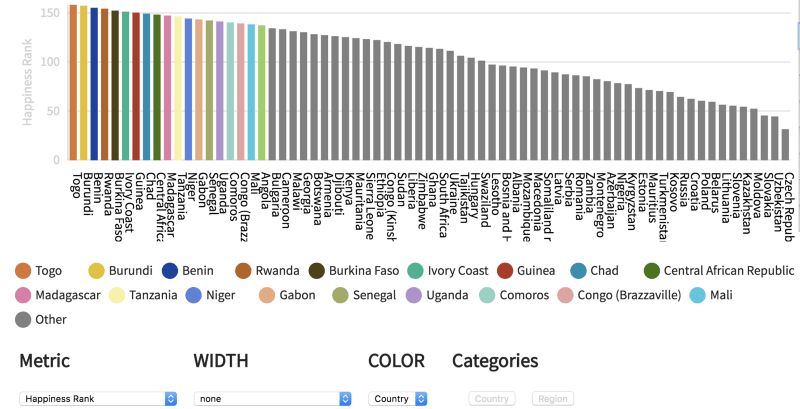
通过Categories(类别)可以聚合行。WIDTH(柱宽)也可以用来编码第二测度,生成不等宽柱状图。
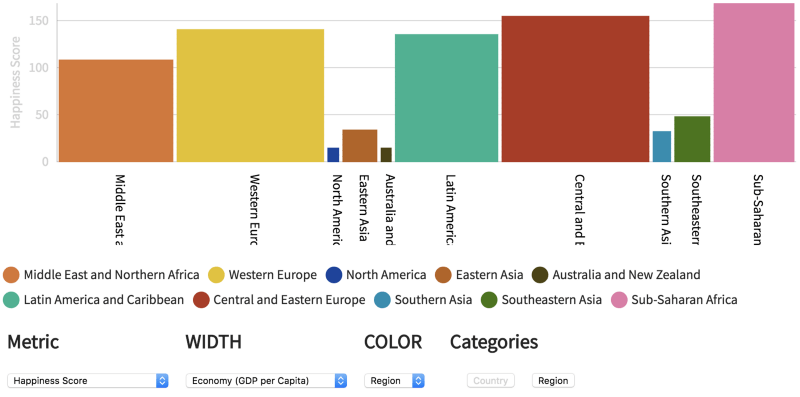
需要注意的是聚合只是简单的相加,因此选中Region(区域)时,得到的是该区域的幸福度总值,也就是说,该区域内的国家越多,这一区域的幸福度越高。如果想要准确地比较不同区域的幸福度,我们应该使用总结图。
总结图
柱状图下面的图标对应总结图。默认使用提琴形图,鼠标悬浮数据点,可以查看数据点的具体数值。
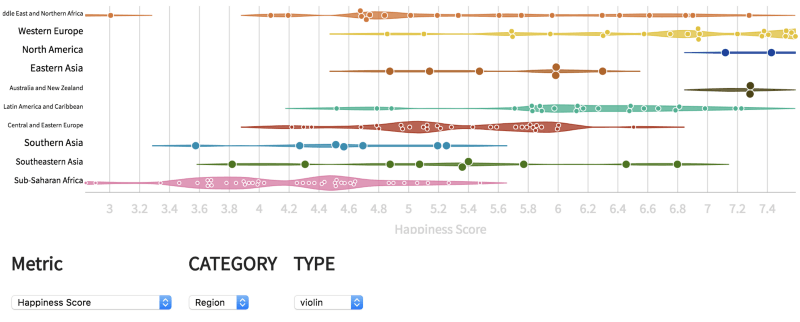
除了Metric(测度)和CATEGORY(类别)外,还可以改变TYPE(可视化类型):joy plot、箱形图、热力图、直方图。

左:joy plot;右:箱形图
散点图
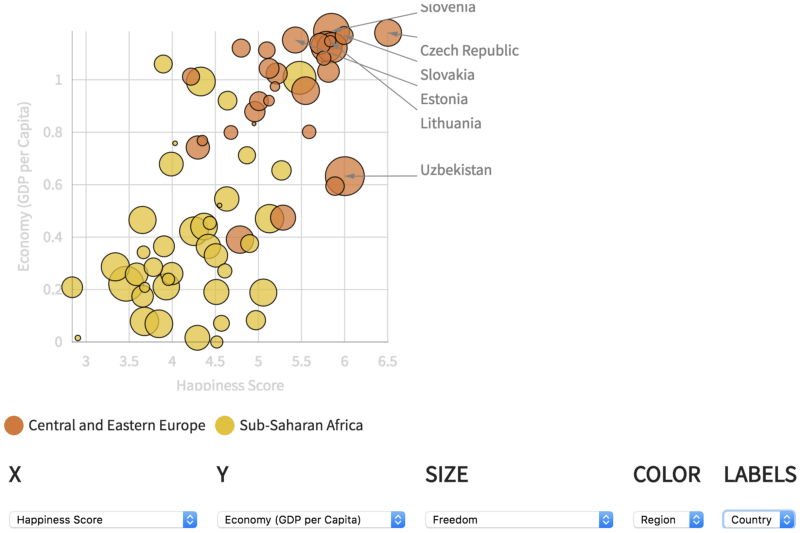
第三个模式是散点图,其中提供了尺寸编码的选项(如果你觉得需要创建气泡图的话)。另外,鼠标悬浮同样可以查看单个数据点的数值。散点图还为排名靠前的数据点提供了初步的注释。
hexbin
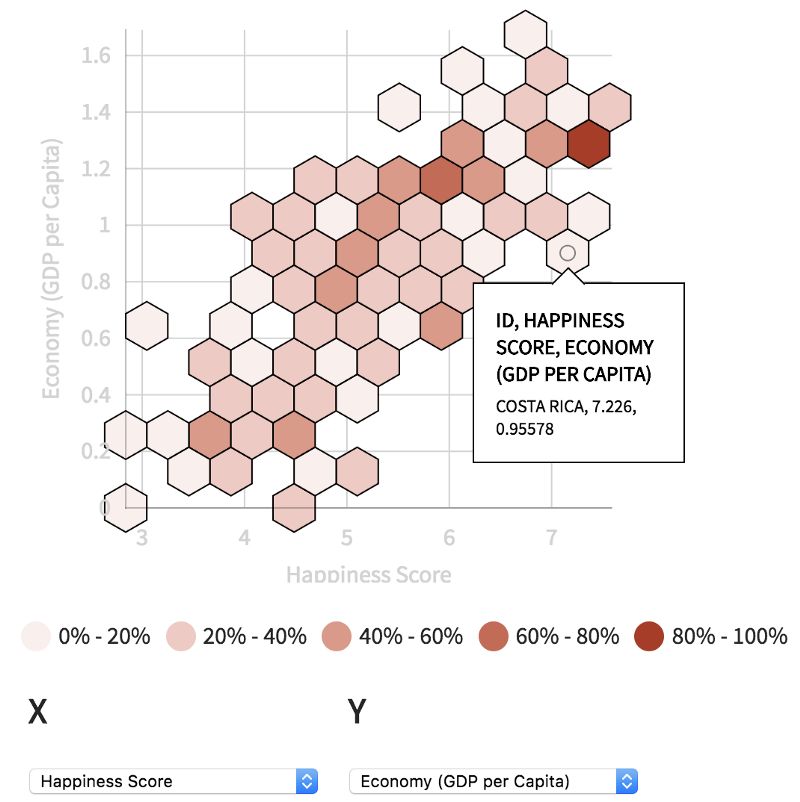
散点图下面是hexbin图标。hexbin有助于探索较大数据集的密度。鼠标悬浮可以查看聚合的数据点。
网络图
nteract数据探索器支持两种网络图:桑基图(显示流向)和力导向网络(传统的类SNA方法)。很不幸,在非网络样本数据上,这两种图的效果都很糟糕。

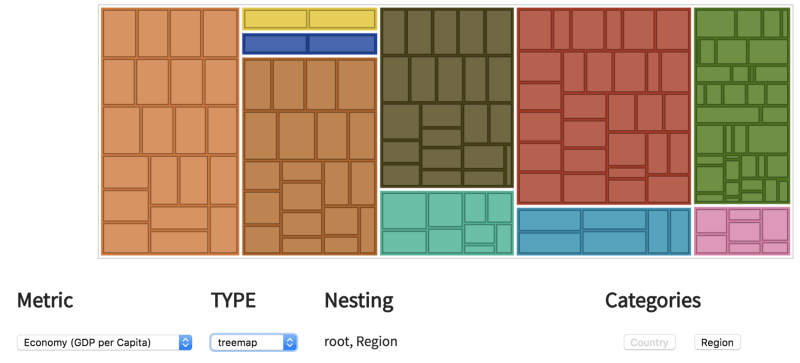
层次结构图
接下来是层次结构图,供你探索层次结构模式。使用Categories(类别)按钮可以选择如何嵌套数据。在treemap(矩形树图)或partition(分区图)模式下,选中的Metric(测度)将用来指定可视化中的尺寸。
平行坐标图
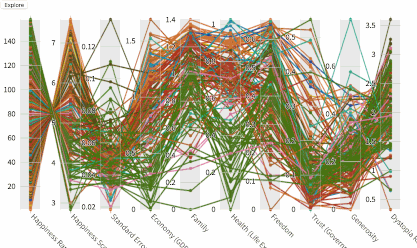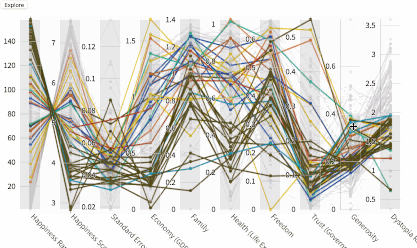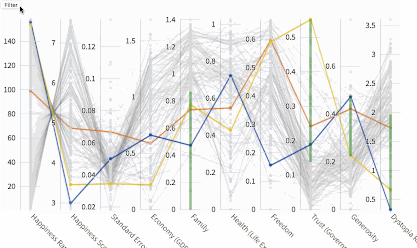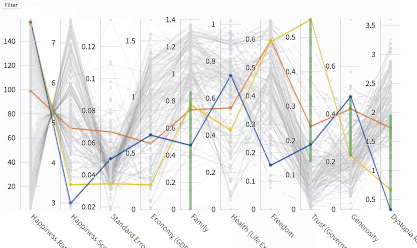
平行坐标图让你可以交互式地分析数据,通过每列上的笔刷过滤数据。点击Explore/Filter(探索/过滤)按钮可以在探索和过滤模式间切换。在过滤模式下,可以通过调节笔刷的起止(缩放尺寸和移动位置)过滤数据。在探索模式下,悬浮鼠标可以查看单独的数据点。
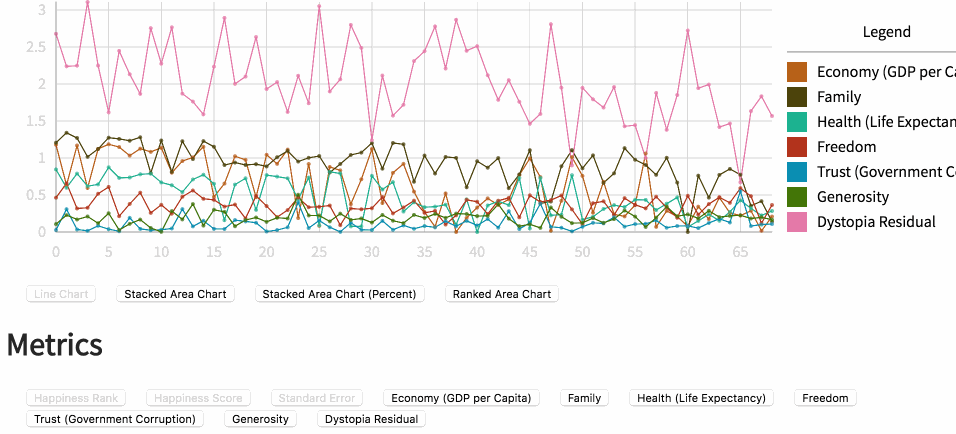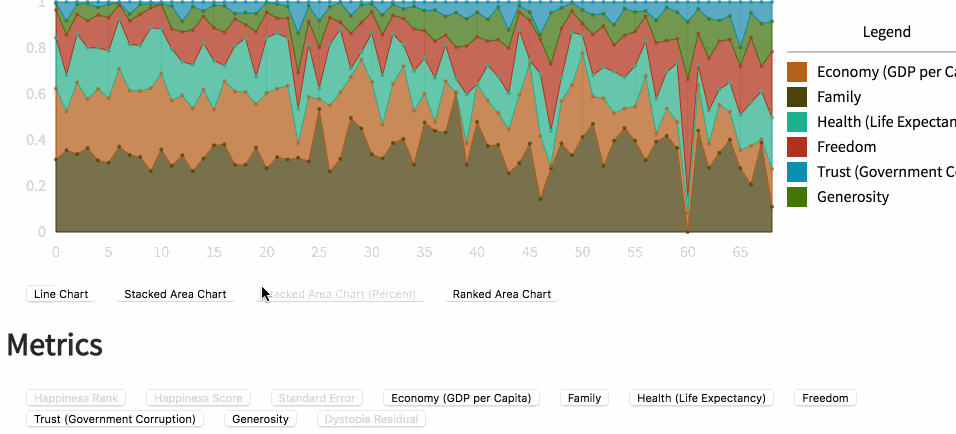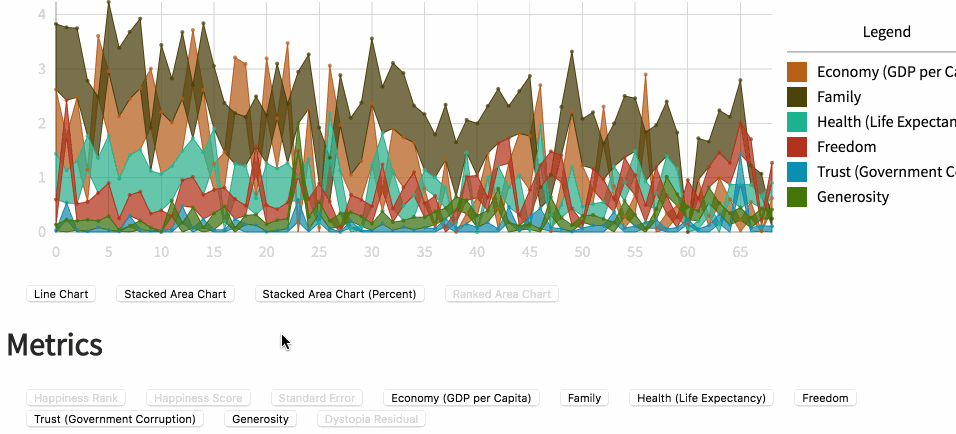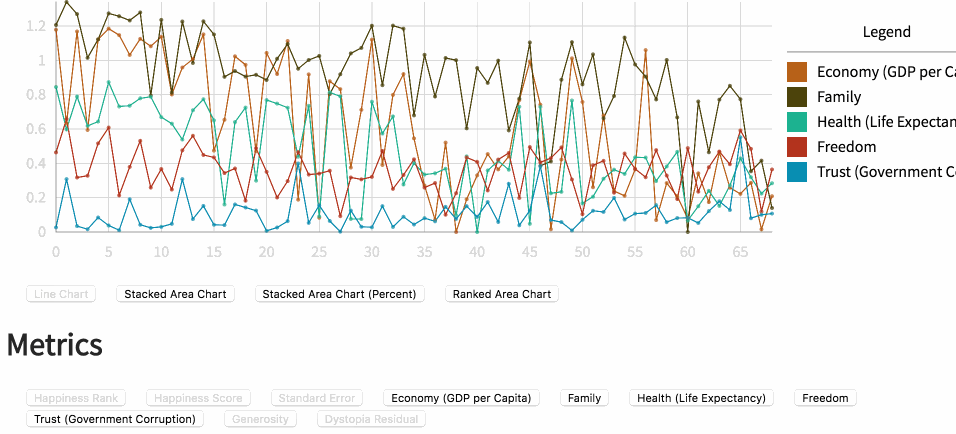
折线图
通过折线图模式可以查看测度的组合,以及它们在百分比、聚合形式下的样貌。未来我将升级这一模式,当数据包含时序信息或者序列信息时,应用相应的可视化。
后续改进
数据模型方面的改进
图表技术的灵活性仅仅是自动数据可视化的诸多制约因素之一。目前数据探索器提供了数据的许多可能视图,但丝毫没有提示你应该使用哪一种。使用鲁棒性更好的数据模型可以改善这一点:
基数: 提供基数信息有助于确定字符串是名称之类的东西(高基数)还是类别(低基数)。
预处理: 自动数据可视化处理的是表格式数据,但使用这一格式表示特定类型的数据却是一项挑战。更好地存储时序数据、数据的总结性草图、拓扑数据有助于鲁棒性更好的可视化数据方法及探索数据方法。
特征: 散点图视图中的简单注释是Semiotic的主要特性。然而,自动生成注释很困难。探索数据特征的启发式算法,例如异常检测或其他方法,可以在数据可视化中添加丰富的注释。
数据探索器方面的改进
这是我首次尝试创建某种自动数据探索工具,我确信有可以改进的地方。所以我欢迎所有使用nteract的人提交bug报告或要求开发新特性。我个人觉得以下三个方面值得改进:
UI改进: 开发数据探索器的需求之一是使用原生HTML控件。直到我尝试只使用原生元素实现美观周全的UI时,我才意识到我有多依赖那些定制的UI元素。除了美观程度上的提升外,很多控件可以设计得更好,比如按钮可以提供更多内置的指示。特别是不同视图之间的导航应该有更好的信息层次,提示用户不同的图表方法的相关程度。
多张小图: 探索数据最有用的可视化技术是并列多张小图——基于相同数据和/或相同尺度的多张图表,以供比较不同维度。
保存状态: 我之前已经提到过,数据探索器不打算和传统的notebook数据可视化竞争。数据的视图可以保存到单元,避免刷新后丢失,这个功能还是有用的。
结语
就我的经验而言,当前的自动数据可视化产品往往堆砌特性,缺乏统一的主题。我希望数据探索器能做到的一点是,不仅提供用户大量的图表,而且能够让数据可视化和数据探索更好地配合。
原文地址:https://blog.nteract.io/designing-the-nteract-data-explorer-f4476d53f897