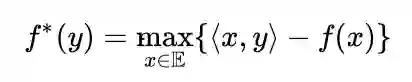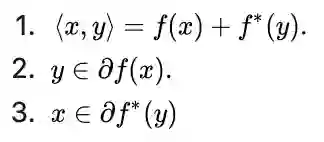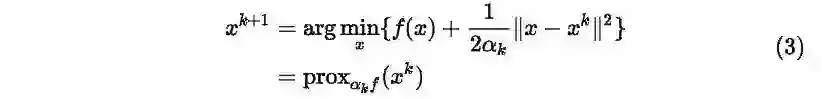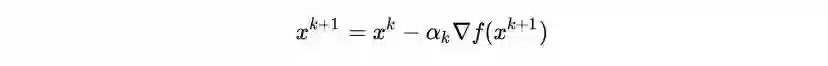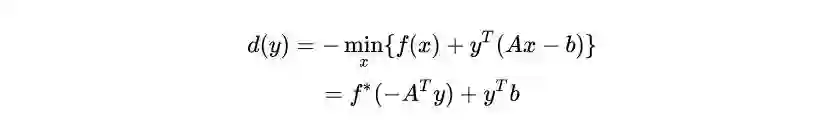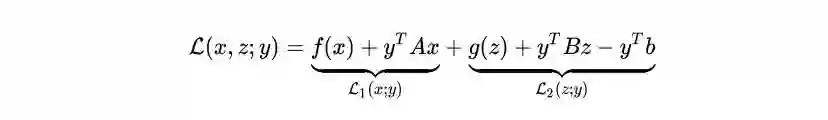加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
来源:最优化理论和一阶方法知乎专栏
链接:https://zhuanlan.zhihu.com/p/92230537
本文已由作者授权转载,未经允许,不得二次转载
这篇文章介绍三个方法在原始角度和对偶角度下的形式,分别为:梯度方法(gradient descent method),临近点方法(proximal point method)以及临近梯度方法(proximal gradient method),感受下对偶的魅力。主要参考的是wotao yin的slide,有兴趣的可以看他的主页(
链接:
https://www.math.ucla.edu/~wotaoyin/index.html
)。
一、共轭函数(conjugate function)
接下来我们分析下共轭函数的一些性质,这将会在对偶方法中的推导起到关键的作用。因为对偶问题中目标函数就是原问题目标函数的共轭形式。所以我们要研究一下共轭函数的次梯度,以及什么情况下光滑。
定理1(conjugate subgradient theorem)
:令函数 f 是convex proper and closed. 那么下面三条对任意 x,y 等价
proof. (为了完整性,我给出证明,不想看的可以跳过,记住结论就行。)
二、Primal Perspective
2.1 Gradient descent method
2.2 Proximal point method
当问题(1)中的函数可能不光滑的时候,我们可以用临近点方法 ,具体地,该方法有如下形式:
2.3 Proximal Gradient Method
三、Dual Perspective
下面我将首先得到原问题的对偶问题,然后利用上面提到的三个方法去求解,最后通过formulation,观察他们在转化到原始角度下是什么样的形式。
3.1 Dual (sub)gradient descent method
如果d是光滑的,那么上式就为梯度下降。就这样结束了吗?并没有,虽然这样看起来很简洁,但问题是我们不知道d(y)这个函数的显式表达形式是什么,甚至连是不是可微的也不知道,也就没有办法去求解它的梯度了。下面我来回答三个问题:
其次,我们知道当f是强凸的时候,它的共轭才会是光滑的,进一步d(y)才光滑。
3.2 Dual proximal point method
考虑上述的线性约束问题(6),这次我将PPA应用到对偶问题中,即
这也等价于增广拉格朗日方法(ALM)。所以我们有结论:
3.3 Dual proximal gradient method
可以看到这个方法很像ADMM,差别就在于对于x子问题,ADMM用的是增广拉格朗日函数,而这个方法用的是拉格朗日函数。
四、总结
这里我只介绍了三种方法在对偶角度下的形式,事实上,任意的方法都可以用到对偶问题上,比如:
-
对偶问题下的Douglas-Rachford splitting方法等价于原始问题的ADMM方法
-
对偶问题下的Peaceman-Rachford splitting方法等价于原始问题的对称ADMM方法
有时候还会有意想不到的结果。比如我的另一篇文章(
链接:
https://zhuanlan.zhihu.com/p/92230537
),就是将ALM(增广拉格朗日方法)应用到对偶问题上,再结合稀疏结构,加速了计算。
[1] A.Beck. First-order methods in optimization[M]. SIAM, 2017.
[2] Splitting methods in communication, imaging, science, and engineering[M]. Springer, 2017.
[3] Y.Chen. Large-Scale Optimization for Data Science,ELE522,lecture notes,Princeton University
[4] L. Vandenberghe. Optimization methods for large-scale systems, EE236C lecture notes,UCLA.
[5] Ryu E K, Boyd S. Primer on monotone operator methods[J]. Appl. Comput. Math, 2016, 15(1): 3-43.
[6]
https://www.math.ucla.edu/~wotaoyin/index.html
-End-
CV细分方向交流群
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割、OCR、姿态估计等极市技术交流群(已经添加小助手的好友直接私信),更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~
![]()
△长按添加极市小助手
![]()
△长按关注极市平台
打了这么多的公式,不给个在看啦~ ![]()