深入机器学习系列之:4-KMeans


导读
本文会介绍一般的k-means算法、k-means++算法以及基于k-means++算法的k-means||算法。在spark ml,已经实现了k-means算法以及k-means||算法。 本文首先会介绍这三个算法的原理,然后在了解原理的基础上分析spark中的实现代码。

来源: 星环科技丨作者:智子AI
数据猿官网 | www.datayuan.cn

今日头条丨一点资讯丨腾讯丨搜狐丨网易丨凤凰丨阿里UC大鱼丨新浪微博丨新浪看点丨百度百家丨博客中国丨趣头条丨腾讯云·云+社区

1 k-means算法原理分析
k-means算法是聚类分析中使用最广泛的算法之一。它把n个对象根据它们的属性分为k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。
k-means算法的基本过程如下所示:

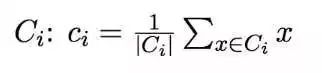
(4)计算标准测度函数,当满足一定条件,如函数收敛时,则算法终止;如果条件不满足则重复步骤
1.1 k-means算法的缺点
k-means算法虽然简单快速,但是存在下面的缺点:
聚类中心的个数K需要事先给定,但在实际中K值的选定是非常困难的,很多时候我们并不知道给定的数据集应该分成多少个类别才最合适。
k-means算法需要随机地确定初始聚类中心,不同的初始聚类中心可能导致完全不同的聚类结果。
第一个缺陷我们很难在k-means算法以及其改进算法中解决,但是我们可以通过k-means++算法来解决第二个缺陷。
2 k-means++算法原理分析
k-means++算法选择初始聚类中心的基本原则是:初始的聚类中心之间的相互距离要尽可能的远。它选择初始聚类中心的步骤是:

第(2)步中,依次计算每个数据点与最近的种子点(聚类中心)的距离,依次得到D(1)、D(2)、...、D(n)构成的集合D,其中n表示数据集的大小。在D中,为了避免噪声,不能直接选取值最大的元素,应该选择值较大的元素,然后将其对应的数据点作为种子点。 如何选择值较大的元素呢,下面是spark中实现的思路。
求所有的距离和Sum(D(x))
取一个随机值,用权重的方式来取计算下一个“种子点”。这个算法的实现是,先用Sum(D(x))乘以随机值Random得到值r,然后用currSum += D(x),直到其currSum > r,此时的点就是下一个“种子点”。
为什么用这样的方式呢?我们换一种比较好理解的方式来说明。把集合D中的每个元素D(x)想象为一根线L(x),线的长度就是元素的值。将这些线依次按照L(1)、L(2)、...、L(n)的顺序连接起来,组成长线L。L(1)、L(2)、…、L(n)称为L的子线。 根据概率的相关知识,如果我们在L上随机选择一个点,那么这个点所在的子线很有可能是比较长的子线,而这个子线对应的数据点就可以作为种子点。
2.1 k-means++算法的缺点
虽然k-means++算法可以确定地初始化聚类中心,但是从可扩展性来看,它存在一个缺点,那就是它内在的有序性特性:下一个中心点的选择依赖于已经选择的中心点。 针对这种缺陷,k-means||算法提供了解决方法。
3 k-means||算法原理分析


第1步随机初始化一个中心点,第2-6步计算出满足概率条件的多个候选中心点C,候选中心点的个数可能大于k个,所以通过第7-8步来处理。第7步给C中所有点赋予一个权重值 Wx ,这个权重值表示距离x点最近的点的个数。 第8步使用本地k-means++算法聚类出这些候选点的k个聚类中心。在spark的源码中,迭代次数是人为设定的,默认是5。
该算法与k-means++算法不同的地方是它每次迭代都会抽样出多个中心点而不是一个中心点,且每次迭代不互相依赖,这样我们可以并行的处理这个迭代过程。由于该过程产生出来的中心点的数量远远小于输入数据点的数量, 所以第8步可以通过本地k-means++算法很快的找出k个初始化中心点。何为本地k-means++算法?就是运行在单个机器节点上的k-means++。
下面我们详细分析上述三个算法的代码实现。
4 源代码分析
在spark中,org.apache.spark.mllib.clustering.KMeans文件实现了k-means算法以及k-means||算法,org.apache.spark.mllib.clustering.LocalKMeans文件实现了k-means++算法。 在分步骤分析spark中的源码之前我们先来了解KMeans类中参数的含义。

在上面的定义中,k表示聚类的个数,maxIterations表示最大的迭代次数,runs表示运行KMeans算法的次数,在spark 2.0。0开始,该参数已经不起作用了。为了更清楚的理解算法我们可以认为它为1。 initializationMode表示初始化模式,有两种选择:随机初始化和通过k-means||初始化,默认是通过k-means||初始化。initializationSteps表示通过k-means||初始化时的迭代步骤,默认是5,这是spark实现与第三章的算法步骤不一样的地方,这里迭代次数人为指定, 而第三章的算法是根据距离得到的迭代次数,为log(phi)。epsilon是判断算法是否已经收敛的阈值。
下面将分步骤分析k-means算法、k-means||算法的实现过程。
4.1 处理数据,转换为VectorWithNorm集

4.2 初始化中心点
初始化中心点根据initializationMode的值来判断,如果initializationMode等于KMeans.RANDOM,那么随机初始化k个中心点,否则使用k-means||初始化k个中心点。
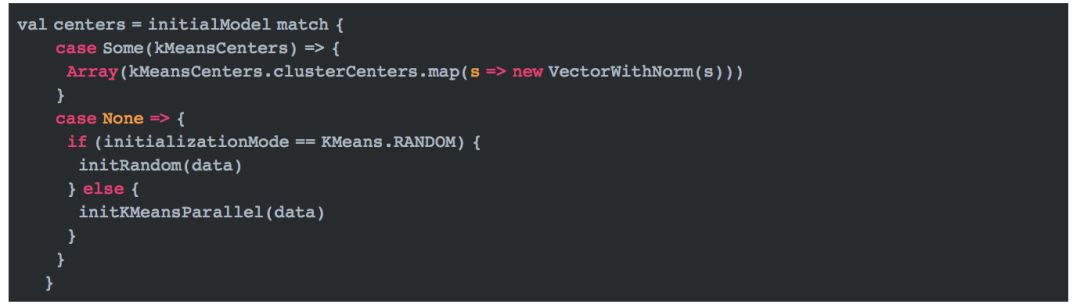
(1)随机初始化中心点
随机初始化k个中心点很简单,具体代码如下:

(2)通过k-means||初始化中心点
相比于随机初始化中心点,通过k-means||初始化k个中心点会麻烦很多,它需要依赖第三章的原理来实现。它的实现方法是initKMeansParallel。 下面按照第三章的实现步骤来分析。
第一步,我们要随机初始化第一个中心点。

-
第二步,通过已知的中心点,循环迭代求得其它的中心点。
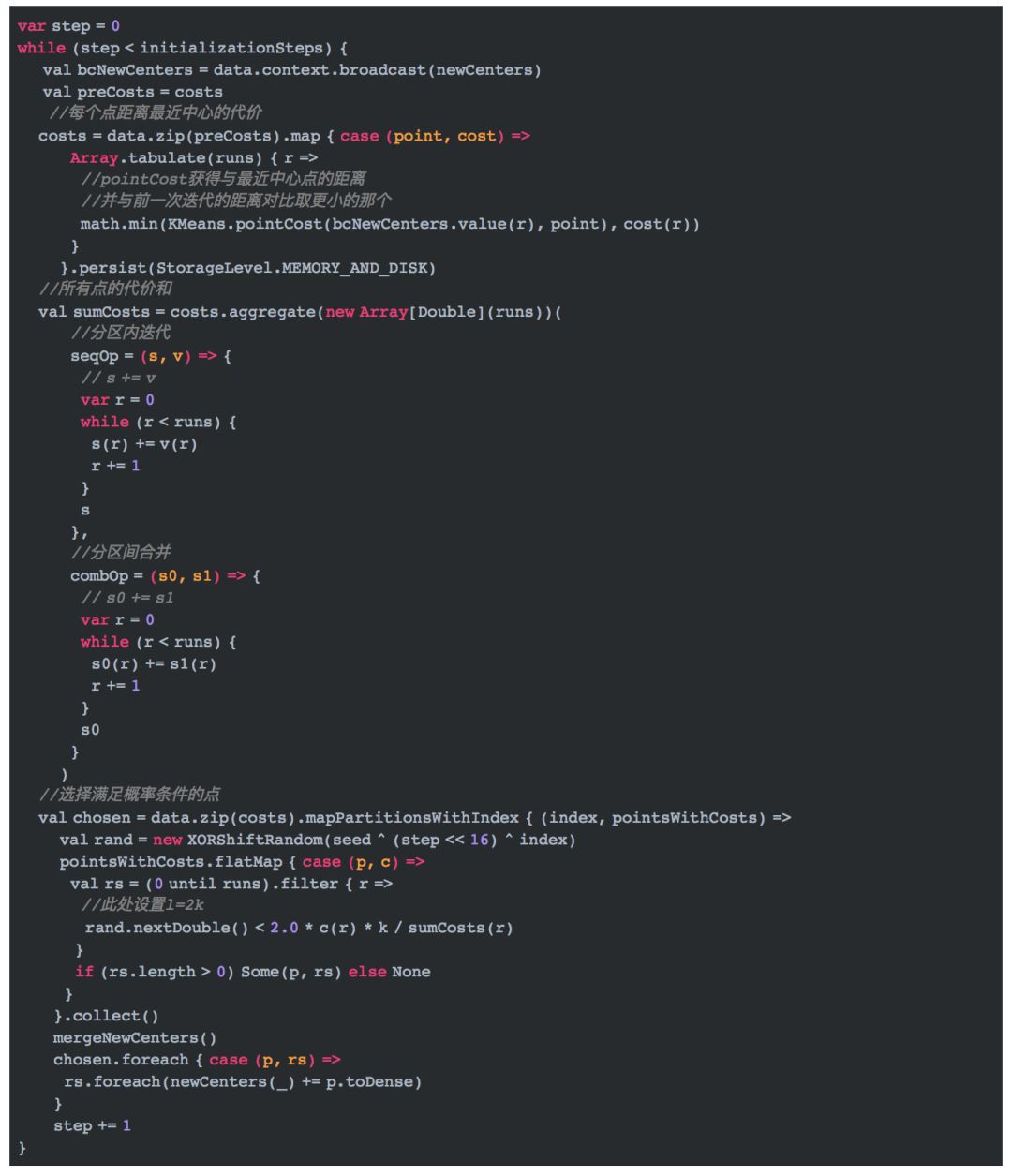
在这段代码中,我们并没有选择使用log(pha)的大小作为迭代的次数,而是直接使用了人为确定的initializationSteps,这是与论文中不一致的地方。 在迭代内部我们使用概率公式
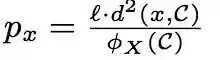
来计算满足要求的点,其中,l=2k。公式的实现如代码rand.nextDouble() < 2.0 * c(r) * k / sumCosts(r)。sumCosts表示所有点距离它所属类别的中心点的欧式距离之和。 上述代码通过aggregate方法并行计算获得该值。
第三步,求最终的k个点。
通过以上步骤求得的候选中心点的个数可能会多于k个,这样怎么办呢?我们给每个中心点赋一个权重,权重值是数据集中属于该中心点所在类别的数据点的个数。 然后我们使用本地k-means++来得到这k个初始化点。具体的实现代码如下:

上述代码的关键点时通过本地k-means++算法求最终的初始化点。它是通过LocalKMeans.kMeansPlusPlus来实现的。它使用k-means++来处理。
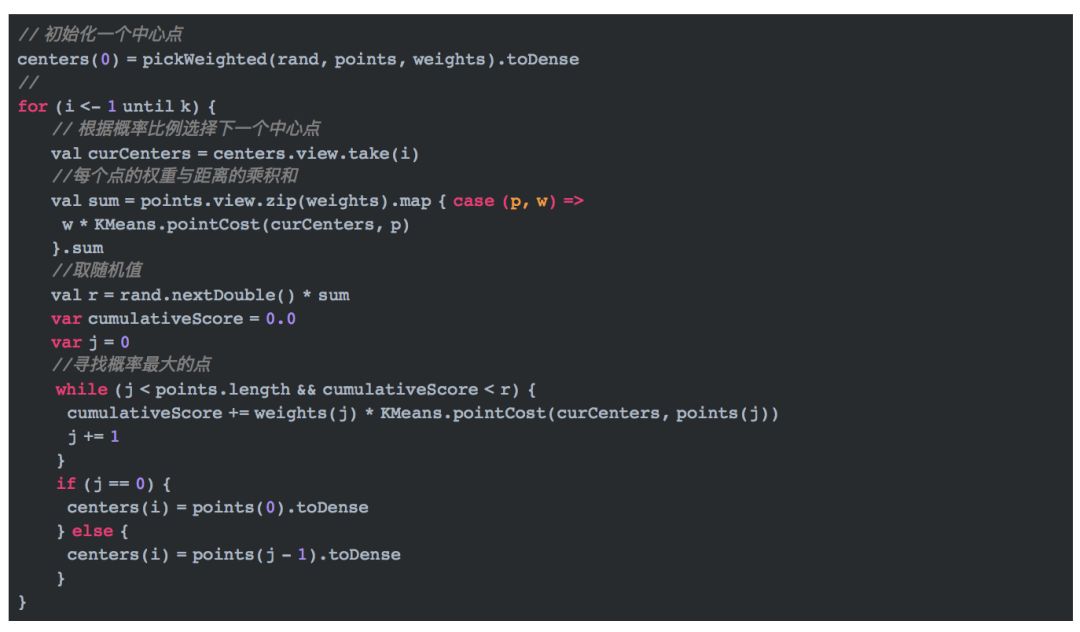
上述代码中,points指的是候选的中心点,weights指这些点相应地权重。寻找概率最大的点的方式就是第二章提到的方式。初始化k个中心点后, 就可以通过一般的k-means流程来求最终的k个中心点了。具体的过程4.3会讲到。
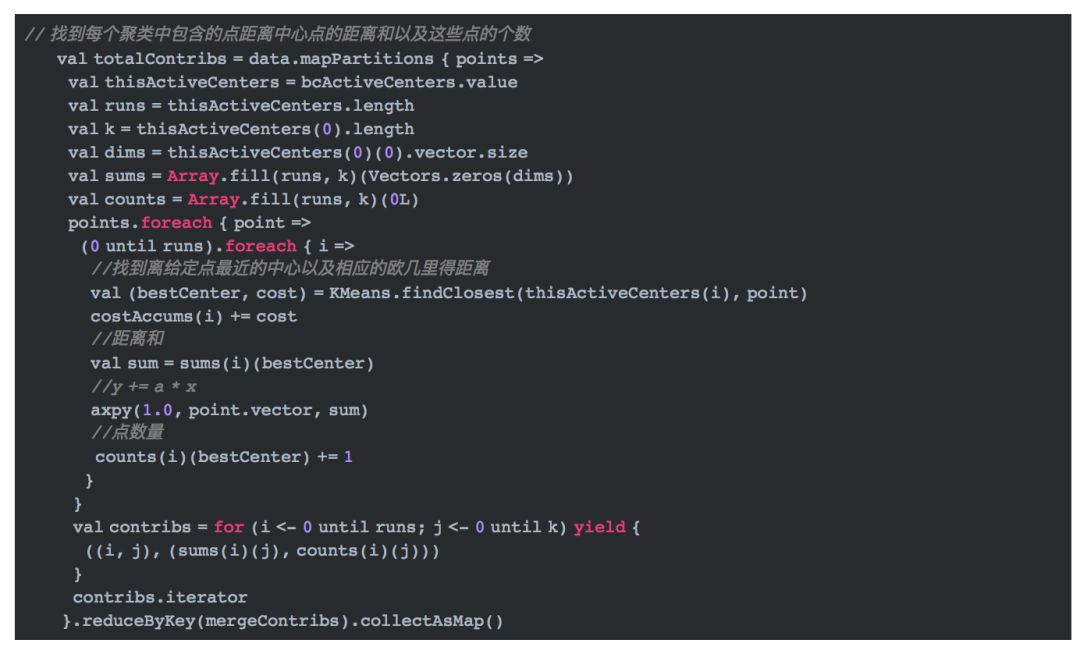
4.3 确定数据点所属类别
找到中心点后,我们就需要根据距离确定数据点的聚类,即数据点和哪个中心点最近。具体代码如下:
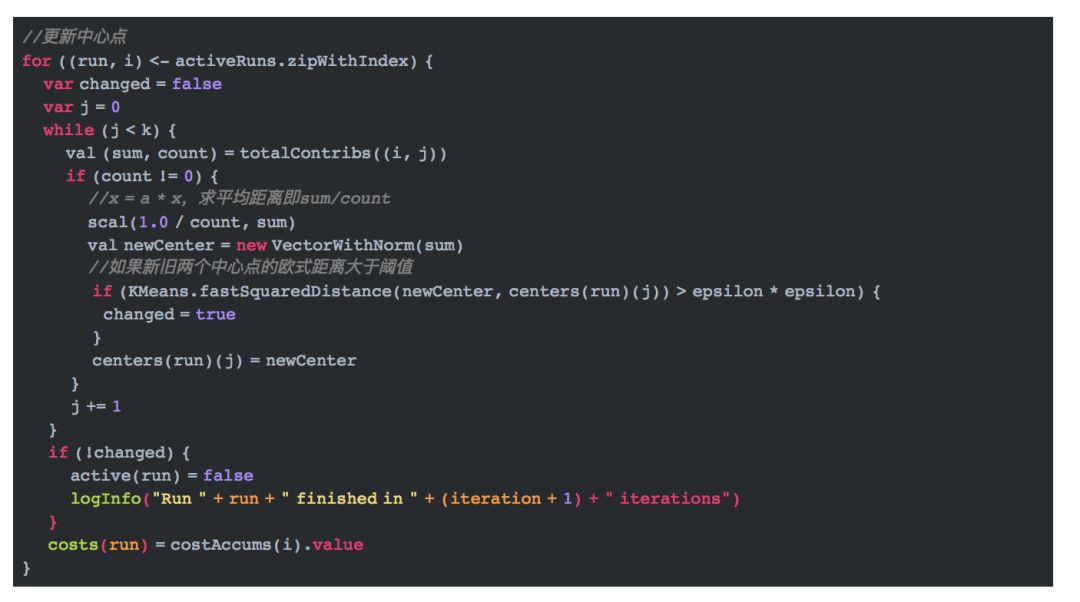
4.4 重新确定中心点
找到类别中包含的数据点以及它们距离中心点的距离,我们可以重新计算中心点。代码如下:
5 参考文献
【1】Bahman Bahmani,Benjamin Moseley,Andrea Vattani.Scalable K-Means++
【2】David Arthur and Sergei Vassilvitskii.k-means++: The Advantages of Careful Seeding