CV大神谢赛宁离职Meta加入纽约大学,与何恺明共著ResNeXt

新智元报道
新智元报道
【新智元导读】近日,ResNeXt一作谢赛宁宣布将从Meta离职加入纽约大学。
CV大佬谢赛宁将要从Meta离职加入纽约大学。
他表示,自己将要结束4年在FAIR的研究生活,2023年1月将在纽约大学担任助理教授。

他即将于图灵奖得主Yann LeCun成为新同事。LeCun发文表示,「欢迎赛宁」。

据个人主页介绍,谢赛宁本科毕业于上海交通大学,18年获加州大学圣迭戈分校CS博士学位。
毕业后,便在Facebook AI Research (FAIR)担任研究科学家。
他曾有过丰富的实习经历,包括在NEC Labs、Adobe、Facebook、Google、DeepMind。
他的主要研究方向包括深度学习和计算机视觉,并致力于改进表示学习技术,以帮助机器理解和利用大量的结构化信息,并通过学习更好的表示来推动视觉识别的边界。

为什么说谢赛宁是CV级大佬,还得从他的学术研究成果说起。
一作谢赛宁与何恺明大神共同提出了用于图像分类的简单、高度模块化的网络结构ResNeXt,这篇论文发表在了2017CVPR上。
ResNeXt提出了一种介于普通卷积核深度可分离卷积的这种策略:分组卷积,它通过控制分组的数量(基数)来达到两种策略的平衡。
分组卷积的思想是源自Inception,不同于Inception的需要人工设计每个分支,ResNeXt的每个分支的拓扑结构是相同的。最后再结合残差网络,得到的便是最终的ResNeXt。

还有今年1月,由谢赛宁带领的团队发表了一篇「A ConvNet for the 2020s」论文,掀起CV圈模型架构之争。
要知道,过去一年,Transformer频频跨界视觉领域,同时投身这一方向的研究学者越来越多。
而这篇论文的提出,带来了全新的纯卷积模型ConvNeXt。

此外,在2021年,他还与何恺明合作一篇「Masked Autoencoders Are Scalable Vision Learners」。
论文中,提出了一种用于计算机视觉的Masked AutoEncoders 掩蔽自编码器,简称MAE,一种类似于NLP技术的自我监督方法。

操作很简单:对输入图像的随机区块进行掩蔽,然后重建缺失的像素。
主要有两个核心设计:一个是非对称的编码-解码架构,一个高比例遮蔽输入图像。

目前,谷歌学者主页中,谢赛宁所有著作的引用量已超过2万。其中被引数最多的一篇论文便是他以一作身份提出的ResNeXt。
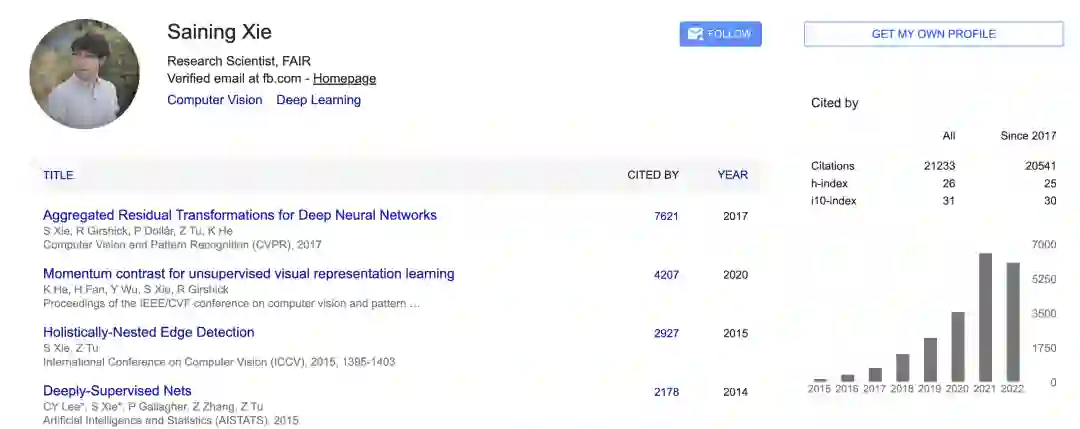
接下来,他将要离开FAIR,加入纽约大学,并阐述了未来自己的研究方向。

许多学界学者为其送上了祝福。

https://twitter.com/sainingxie/status/1565002386879328257




