【EMNLP2019教程】端到端学习对话人工智能,附237页PPT下载
导读
AI对话系统的一个基本的长期目标是将两个主要的对话系统合并成一个独立的多用途系统。诸如此类的系统应该能够涵盖多个主题领域(范例1:开放领域的对话系统),同时能够使用定义良好的语义帮助人们完成广泛的任务,如餐馆搜索和预订、客户服务或机票预订等。
教程介绍
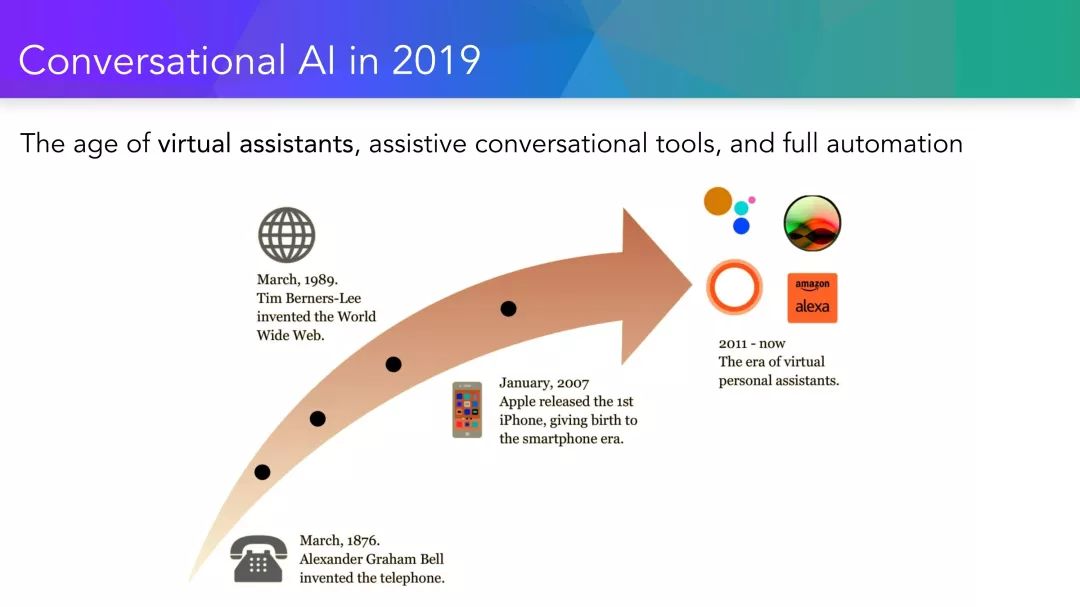
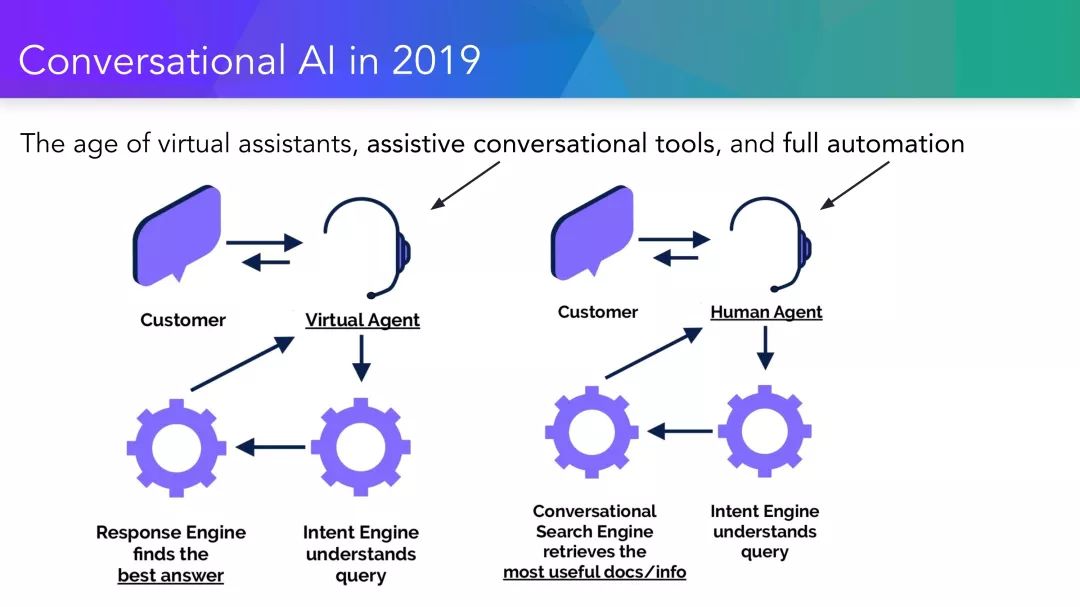
最近AI对话技术的飞跃式发展,无疑与越来越复杂的深度学习算法有关,而深度学习算法所捕捉到的模式是由各种数据收集机制生成的。因此,本教程的目标是双重的。首先,它旨在让学术界熟悉基于统计学的对话系统算法设计的最新进展,其中包括开放性领域和基于任务的对话范例。本教程的重点是介绍对话系统端到端的学习机制,以及它们与更加常见的模块系统之间的关联。从理论上讲,从数据中学习端到端可以为对话系统提供无缝的、空前的可移植性,有着非常广阔的应用前景。从实践的角度来看,该领域仍然存在大量的研究挑战和机会:在本教程中,我们会分析理论和实践之间的差异,并介绍当前端到端对话学习的主要优势和实践中的局限性。

介绍
理解数据(带注释和不带注释的)收集对AI对话系统的重要性。
介绍最新的关于AI对话系统的数据收集范式。
阐述大规模无结构的对话数据在对话系统预训练方面的可用性。
提供端到端数据驱动在AI对话学习模型的概述。
讨论数据和算法选择之间的重要性。
关于当前(任务导向)AI对话在实际操作中的一个行业视角。

完整PPT下载:
请关注专知公众号(点击上方蓝色专知关注)
后台回复“EMNLP2019LCA” 就可以获取本文完整PPT下载链接~








登录查看更多
相关内容
Arxiv
5+阅读 · 2020年6月10日



相关VIP内容
相关资讯
相关论文
Arxiv
5+阅读 · 2020年6月10日