赛尔原创 | 基于时间序列网络的谣言检测研究
作者: 哈工大SCIR硕士生 任文静
1. 引言
新浪微博是中国活跃人数最多的社交网络平台及讯息传播基地,信息繁多,传播自由便捷,影响力巨大,成为舆情爆发和升温的重要传播媒介。
目前,国内研究者基于新浪微博平台中的谣言信息已经展开了丰富的研究工作,从不同的角度着手构建谣言检测模型。大多数的研究都是将其看作分类任务,利用带标签的数据集进行有监督的学习,人工抽取文本特征、用户特征、传播特征及其他潜在特征,构造分类器。但构造特征工程费时费力,并且需要一定的专业背景知识。
相比于传统的机器学习方法,深度学习模型可以自动学习数据集中蕴含的特征,摒弃了繁琐的特征构造过程。在本次研究中,主要利用GRU、LSTM模型对微博文本进行建模,考虑到评论信息对谣言检测具有重要的影响,评论文本中包含着否定、怀疑、肯定等态度,所以,利用注意力模型对评论进行建模。由于评论数众多,因此采用分块的方式对评论进行划分,作为时间序列模型每个时刻的输入,并引入attention机制,衡量每个时间块对最终语义表示的影响程度。
2. 注意力模型
注意力模型起初用于编码解码模型中。编码解码模型的基本思想为:编码的过程是将输入序列x转化为固定长度的向量,解码的过程根据固定长度的向量以及之前预测出的词语生成输出序列,是一种端到端的学习过程。编码器、解码器选择自由,可以利用RNN, LSTM,GRU,CNN等深度学习模型自由组合。
编码解码[1][2]模型虽然在多种任务上已取得了很不错的研究效果,但依然存在一定的局限性。在模型编码的过程中,将输入信息压缩到固定长度的实数向量中,可能无法获得完整的文本表示语义。而且,在解码某个词时,只利用到了编码过程的最终表示——即固定长度的向量表示,未考虑到特定输入对当前解码的影响。这种局限性对于机器翻译,序列标注等任务来说,将大大的降低模型效果。
注意力模型[3]可以解决上述局限。通过引入注意力,在解码时,不单单利用固定长度的向量表示,还将关注到每一个输入对当前预测值的影响。每一步预测时计算输入的影响程度,可以充分利用到输入序列携带的信息,进而在解码过程中,输入序列的每个词都对待预测词的选择有影响。
将注意力模型应用到分类任务中对输入序列学习语义表示时,不再使用最后一个隐含层的输出作为特征表示,而是将每个词的重要程度融入整个输入序列的语义表示中,更加直观清楚的解释了输入序列中的每个词对分类任务的影响程度,及对该任务的重要程度[4]。
3. 基于注意力模型的谣言检测
在进行谣言检测时,只靠微博文本是远远不够的,语义信息太过单薄,单凭一条文本,人类也很难看出真假。 通常,微博的评论者会对信息的真实度进行肯定或否定,对于谣言检测任务来说,评论内容也具有至关重要的作用。在微博文本的传播周期中,不同的评论者会产生不同的意见或看法,这些信息可以帮助我们甄别内容的真假。针对一条微博文本的所有评论,我们也可以将其看作是与时间序列相关的,在该条微博的传播周期中,每一时刻对应不同的用户,每个用户产生了不同的评论。将所有的评论平铺到一条线上时,每条评论就对应于每个时间结点的输入信息,所有评论构成了整个输入空间。因此,可以利用时间序列模型对所有评论进行建模,将每条评论当作LSTM每一时刻的输入,学习评论间的相互影响及整个评论的语义表示,此时,模型待处理的时间序列长度是评论数量大小。
通过观察语料发现,针对一条微博文本,最大评论数可达5万条。虽然LSTM具有长依赖关系,但也不能学习到如此远的知识,而且在后期的学习过程中会逐渐忘记先前的东西。因此,考虑对评论进行划分。划分后得到的块作为LSTM、GRU模型每一时刻的输入,减少时间序列的长度,降低模型复杂度。块与块之间依然有时间上的顺序关系,前后互相影响,依然可以利用时间序列模型对其建模。
考虑到评论也具有爆发期,即在不同的时间段,评论的增加或衰减程度是不同的,在对评论进行划分时希望能够捕捉到这种评论的爆发期及衰减期,使划分更加充分,这样划分后每个块内的内容表述可能更加相近,持有相同的观点,对爆发期的评论也能进行更细致的划分。Ma[5]等人提出一种动态划分方式,与均等划分不同的是,在动态划分过程中,时间间隔随着样本密度不断变化的,样本划分后的块数并不固定。
在本次研究中,将微博文本作为第一个块的内容,即时间序列模型1时刻的输入。考虑到每个块对谣言检测的影响程度都不同,在模型中引入注意力机制,获取那些对文本分类有重要影响的块,并且增大这些块的权重,从而改善样本的表示。基于GRU的注意力模型如下图1示。
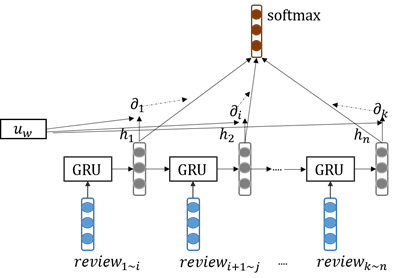
图 1 基于注意力模型的谣言检测
输入是划分成块的评论样本,每个时间结点对应一个评论块,利用GRU模型,结合当前输入及前一个时刻隐含层的输出学习当前时刻隐含层的输出。输入序列的样本表示不再是最后一个隐含层的输出表示,而是利用下述计算公式(1),计算每个隐含层的输出权重,整个评论样本的语义表示为所有隐含层输出值的加权和。是网络中的一个参数,可以被视为问句“输入序列中哪部分是最重要的”的语义表示,随机初始化,然后在不断的训练过程中学习得到。
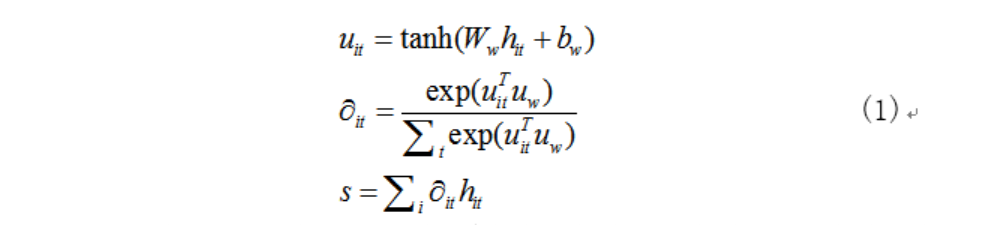
式(1)这种计算形式,充分的利用了每个输入的信息,衡量了每个时间节点的贡献,最终整个评论的语义表示将更倾向于评论中蕴含的大多数的重要信息。
4. 实验结果及分析
4.1 数据集
新浪微博社区管理中心是新浪微博官方成立的,用来协助管理微博的委员会。如若发布淫秽、违法、谣言、辱骂、骚扰等违反社区规定的言论,遭他人举报时,信息就会出现在社区管理中心,等待中心人员的手工审核。利用新浪微博官方发布的API,可以获取新浪微博社区管理中心的“不实消息”版块中的谣言信息。同样的,也可以随机选取一些用户,获取他们发布的微博,过滤后作为真实信息集。Ma等人[5]已经公布了微博平台上的数据集,采样方法如上所述,因此,在本次研究中我们在公开的微博数据集进行实验。
对任务相关的语料库按照层次采样的方式对数据集进行划分,10%为开发集,用作模型调参,剩余的数据按照3:1进行划分,分别用作模型的训练集及测试集,数据集分布如下表1所示。
数据集 |
非谣言 |
谣言 |
总数 |
开发集 |
235 |
231 |
466 |
测试集 |
529 |
520 |
1049 |
训练集 |
1587 |
1562 |
3149 |
表 1 谣言检测数据集分布
4.2 实验结果
GRU_R模型对评论内容进行建模,将评论划分成块,每块作为GRU每个时刻的输入,时间序列的长度为块的个数。GRU_RAtt模型将注意力机制与GRU模型结合起来,并将其应用到微博文本及评论内容的表示学习上,衡量每块评论对微博文本的影响。实验结果如下表2所示。
方法 |
类别 |
精确率 |
准确率 |
召回率 |
F1 |
GRU_R |
R |
90.95% |
89.35% |
92.79% |
91.04% |
N |
92.63% |
89.13% |
90.85% |
||
GRU_RAtt |
R |
92.66% |
91.71% |
93.65% |
92.67% |
N |
93.63% |
91.68% |
92.64% |
表 2 基于注意力模型的评论表示
通过对评论划分成块,利用时间序列模型学习语义表示,并引入Attention机制,衡量不同时间结点影响程度,最终可达F1平均值为92.66%。实验结果证明,Attention机制及评论内容的引入,可以大幅度的提升模型的准确率。注意力模型在建模的过程中,着重考虑每个块内评论对谣言检测的影响程度,利用这种不同的影响度,刻画整体评论的语义表示,使得语义表示更加丰富,更加贴合评论中重要信息,例如怀疑、肯定等态度。
参考文献
[1] Cho K, Merrienboer B V, Gulcehre C, Bahdanau D, Bougares F, Schwenk H, and Bengio Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. EMNLP 2014, pages 1724-1734.
[2] Oriol Vinyals, Łukasz Kaiser, Terry Koo, Slav Petrov, Ilya Sutskever, and Geoffrey Hinton. Grammar as a Foreign Language. NIPS 2015, pages 2755–2763.
[3] Bahdanau D, Cho K, and Bengio Y. Neural Machine Translation by Jointly Learning to Align and Translate. ICLR 2015.
[4] Z Yang, D Yang, C Dyer, X He, A Smola, and E Hovy. A SmolaHierarchical Attention Networks for Document Classification. NAACL 2016, pages 1480-1489.
[5] J Ma, W Gao, P Mitra, S Kwon, BJ Jansen, K Wong, and M Cha. Detecting Rumors from Microblogs with Recurrent Neural Networks. IJCAI 2016, pages 3818-3824.
本期责任编辑: 赵森栋
本期编辑: 张文博
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,郭江,赵森栋
编辑: 李家琦,施晓明,张文博,赵得志
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。





