作者|魔王、小舟、杜伟
来源|机器之心
将自然语言处理领域主流模型 Transformer 应用在视觉领域似乎正在成为趋势。最近,Facebook 研究人员提出一项新技术——数据高效图像 Transformer (DeiT),该方法所需的数据量和计算资源更少,且能产生高性能的图像分类模型。
Transformer 是自然语言处理领域的主流方法,在多项任务中实现了 SOTA 结果。近期越来越多的研究开始把 Transformer 引入计算机视觉领域,例如 OpenAI 的 iGPT、Facebook 提出的 DETR 等。
最近,Facebook 提出了一项新技术 Data-efficient image Transformers(DeiT),需要更少的数据和更少的计算资源就能生成高性能的图像分类模型。研究人员仅用一台 8-GPU 的服务器对 DeiT 模型进行 3 天训练,该方法就在 ImageNet 基准测试中达到了 84.2% 的 top-1 准确率,并且训练阶段未使用任何外部数据,该结果可以与顶尖的卷积神经网络(CNN)媲美。
![]()
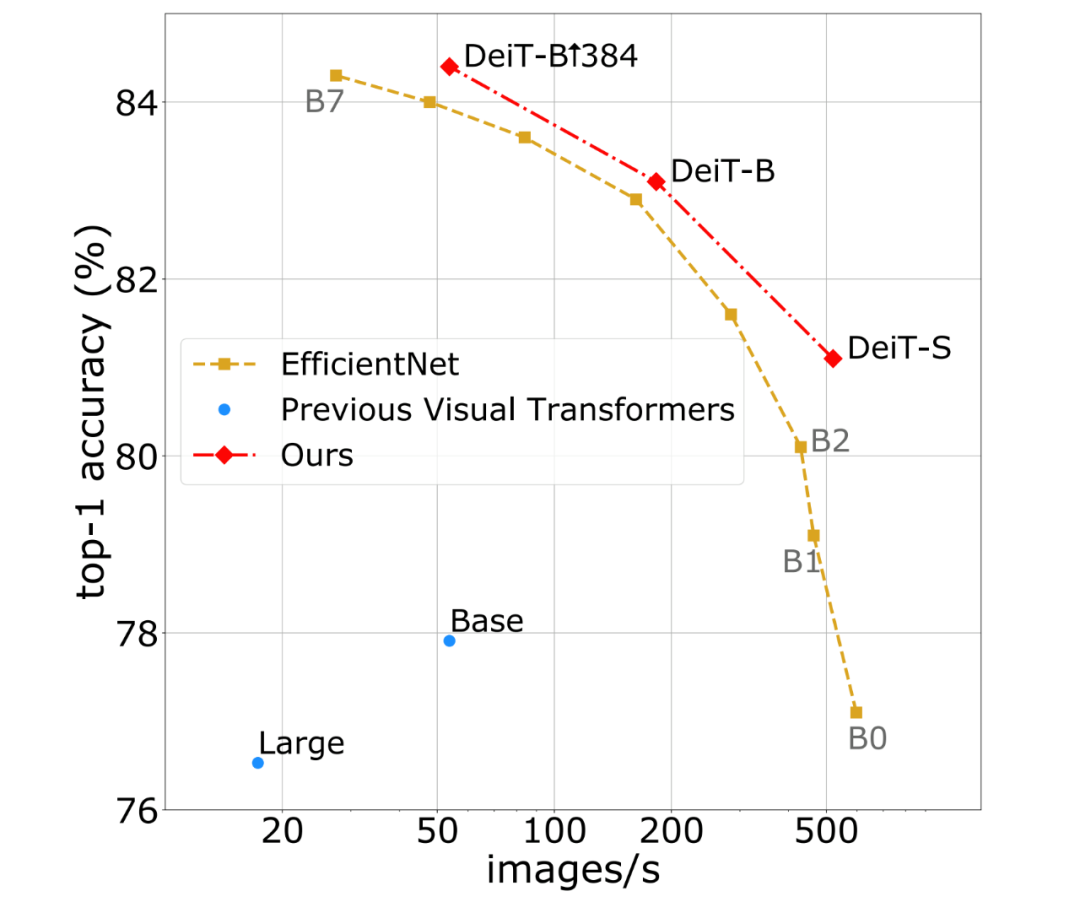
该研究提出的方法(DeiT 和带蒸馏的 DeiT)与以前的视觉 Transformer 模型以及 SOTA CNN 的性能曲线对比,这些模型均在 ImageNet 上训练而成。
该研究表明仅使用常规的学术数据集就能训练 Transformer,使之高效处理图像分类任务。研究者希望借此推动计算机视觉领域发展,将 Transformer 扩展到新的用例上,并让无法使用大规模系统来训练大型 AI 模型的研究者和工程师能够利用该研究。DeiT 方法由 Facebook AI 与索邦大学的 Matthieu Cord 教授合作开发,目前代码已开源。
Training data-efficient image transformers & distillation through attention
https://arxiv.org/pdf/2012.12877.pdf
https://github.com/facebookresearch/deit
![]()
图像分类是理解一张图像主要内容的任务,对于人类而言很简单,但对机器来说却很困难。图像分类对 DeiT 这类无卷积 Transformer 模型来说尤其具有挑战性,因为这些系统没有很多关于图像的统计先验。所以,它们通常必须「观察」大量的示例图像之后才能学习对不同对象进行分类。然而,Facebook AI 研究者提出的 DeiT 仅使用 120 万张图像就可实现高效训练,而不需要数亿张图像。
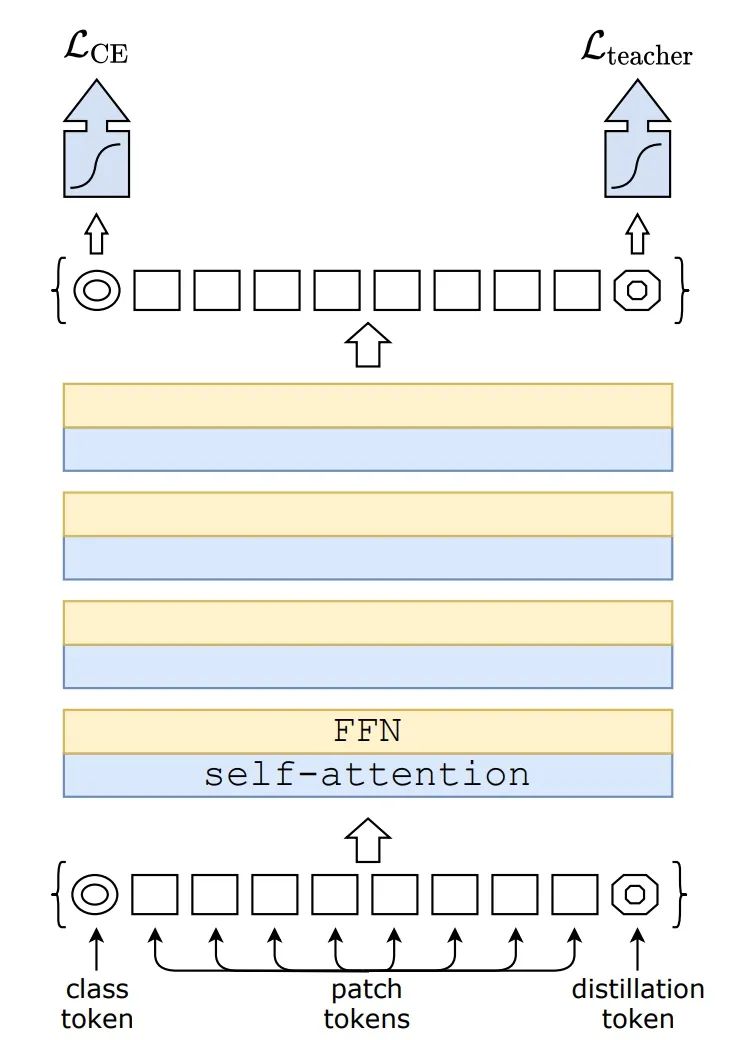
DeiT 首个重要的组件是其训练策略。研究者在最初用于卷积神经网络的现有研究基础上进行了调整与改进,并提出了一种基于蒸馏 token 的新型蒸馏流程,它的作用与 class token 相同,不过其目的在于复制教师网络估计的标签。实验结果表明,这种特定 transformer 策略大幅度优于 vanilla 蒸馏方法。
蒸馏流程如下图所示。研究者仅添加了一个新的蒸馏 token,它通过自注意力层与 class token 和 patch token 交互作用。蒸馏 token 的作用与 class token 类似,不过前者的目的是复制教师网络预测的(硬)标签,而不是正确标签。Transformer 的 class token 和蒸馏 token 输入均通过反向传播学得。
![]()
有趣的是,研究者观察到,学得的 class token 和蒸馏 token 收敛到不同的向量:token 之间的余弦相似度等于 0.06。由于类和蒸馏嵌入是在每一层上进行计算的,因此它们在网络中变得越来越相似,一直到最后一层时相似度达到非常高(cos=0.93),但仍低于 1。这种情况在预期之中,因为它们的目的是生成相似但不同的目标。
在测试时,Transformer 生成的类或蒸馏嵌入与线性分类器相联系,并能够推断出图像标签。
![]()
实验
研究者实施了多项分析实验,首先探讨了蒸馏策略,然后对比分析了卷积神经网络和视觉 transformer 模型的效率与准确率权衡。
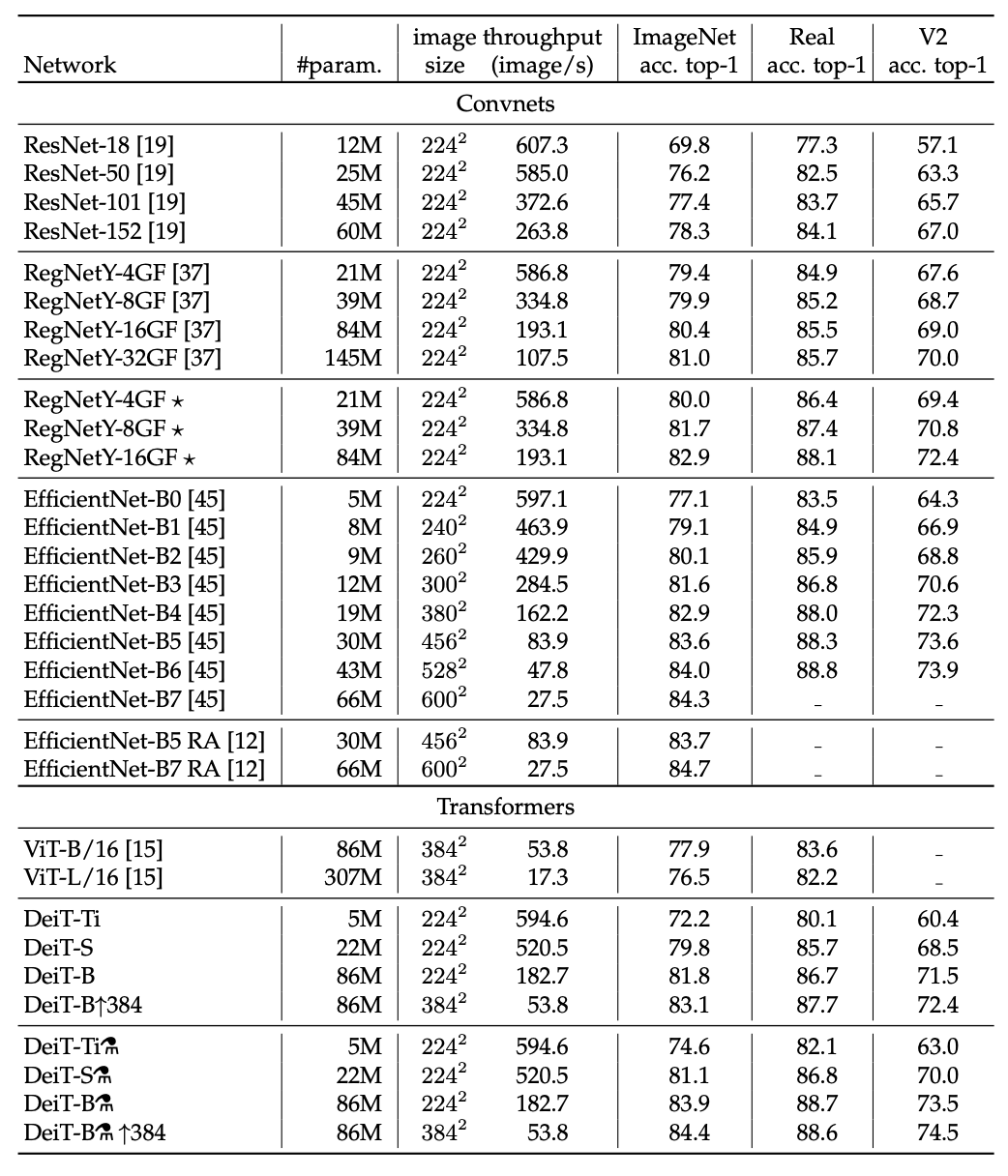
下表 1 展示了该研究考虑的多种模型变体,如无特殊说明,则 DeiT 指代的是 DeiT-B 模型。
![]()
表 1:DeiT 架构变体。DeiT-B 是其中较大的模型,架构与 ViT-B 相同,但是训练策略和蒸馏 token 不同;DeiT-S 和 DeiT-Ti 是两个较小的模型。
实验发现,使用 Convnet 做教师网络的性能要优于使用 transformer。下表 2 对比了使用不同教师架构的蒸馏结果:
![]()
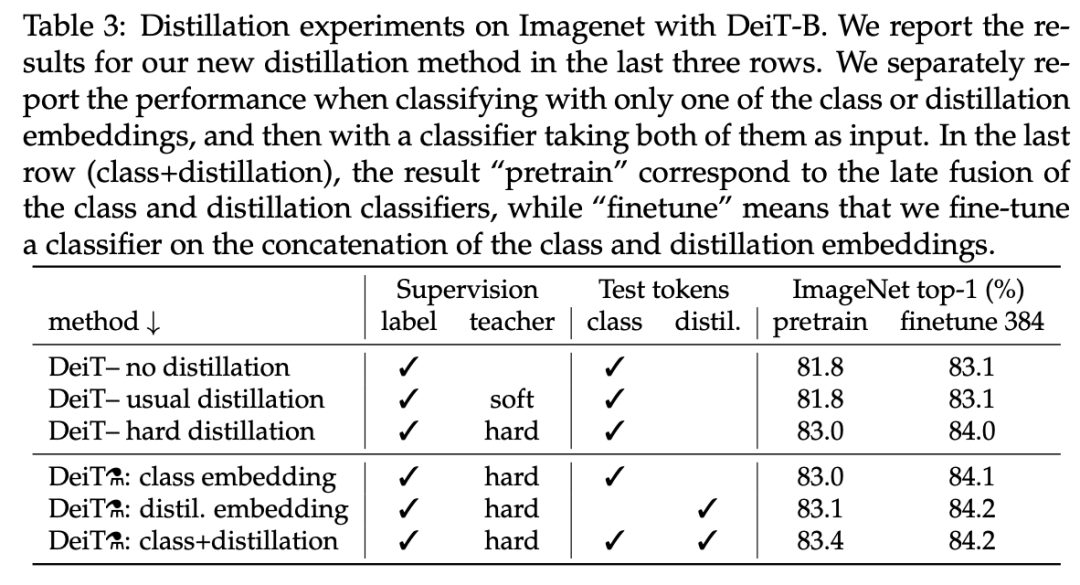
接下来,我们来看蒸馏方法的对比,不同蒸馏策略的性能对比结果参见下表 3。
从中可以看出,对于 transformer 而言,硬蒸馏显著优于软蒸馏,即使在只使用一个 class token 的情况下也是如此:硬蒸馏达到了 83.0% 的准确率,软蒸馏为 81.8%。
该研究提出的蒸馏策略进一步提升了性能,表明 class token 和蒸馏 token 能够提供对分类任务有用的补充信息:基于这两个 token 的分类器性能显著优于单独的 class 分类器和蒸馏分类器,不过单独的分类器依然超过了蒸馏基线方法。
![]()
教师架构对性能有很大影响,那么它会继承已有的归纳偏置吗?Facebook AI 研究者分析了 convnet 教师网络、仅基于标签学得的 DeiT 和 transformer
![]() ,结果参见下表 4:
,结果参见下表 4:
![]()
从中可以看出,该研究提出的蒸馏模型与 convnet 的相关性强于从头开始学习的 transformer。使用蒸馏嵌入的分类器与 convnet 的差距比使用类别嵌入的分类器更小,使用类别嵌入的分类器更类似未经蒸馏的 DeiT。class+distil 分类器处于中间地带。
下表总结了不同方法在 ImageNet V2 和 ImageNet Real 数据集上的性能结果。相比于具备同等参数量的 EfficientNet,convnet 变体速度更慢,原因在于大型矩阵乘法要比小型卷积提供更多硬件优化机会。在这两个数据集上,EfficientNet-B4 的速度与
![]() 相同,准确率也处于相同水平。
相同,准确率也处于相同水平。
![]()
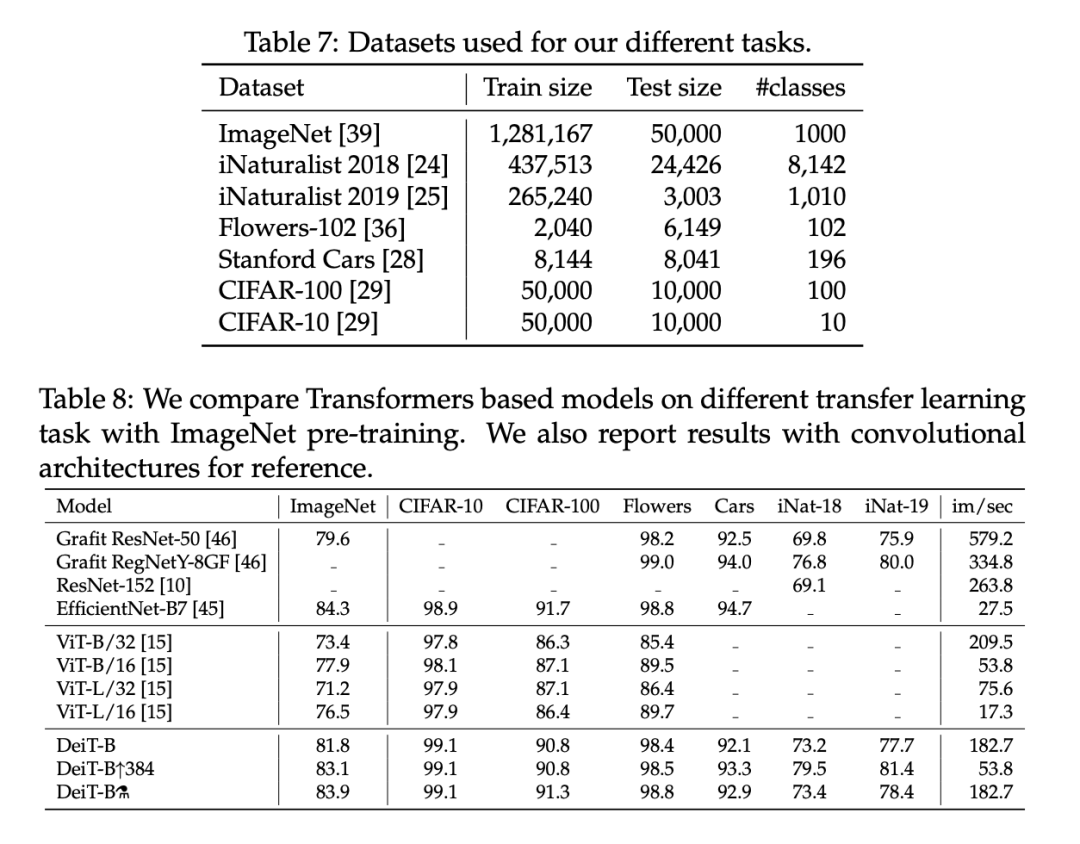
尽管 DeiT 在 ImageNet 数据集上表现良好,但通过迁移学习评估 DeiT 在其他数据集上的性能也很重要,这样可以度量 DeiT 的泛化性能。
研究者通过对下表 7 中的数据集进行微调,在迁移学习任务上对此进行了评估。下表 8 则将 DeiT 迁移学习结果与 ViT 和 SOTA 卷积架构的结果进行了比较。该研究发现 DeiT 的结果和最佳卷积的结果相当,这和此前在 ImageNet 数据集上的结论是一致的。
![]()
参考链接:https://ai.facebook.com/blog/data-efficient-image-transformers-a-promising-new-technique-for-image-classification/
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
![]()
![]()





 ,结果参见下表 4:
,结果参见下表 4: