机器学习常见算法简介及其优缺点总结
机器学习常见算法的一种合理分类:生成/识别,参数/非参数,监督/无监督等。例如,Scikit-Learn文档页面通过学习机制对算法进行分组,产生类别如:1,广义线性模型,2,支持向量机,3,最近邻居法,4,决策树,5,神经网络,等等…但这样的分类并不实用。应用机器学习时通常不会直接想,“今天训练一个支持向量机”,而是通常有一个最终目标,例如利用某算法来预测结果或分类观察。

图1机器学习技术的机器人大脑
机器学习中,有一种叫做“没有免费的午餐”的定理,意思是说没有任何一种算法可以完美地解决每个问题,这对于监督式学习(即预测性建模)尤其重要。例如,你不能说神经网络总是比决策树好,反之亦然。有很多因素在起作用,比如数据集的大小和结构。因此,应该为您的问题尝试许多不同算法,同时使用数据的“测试集”来评估性能并选择优胜者。
尝试的算法必须适合该问题,这是选择正确的机器学习算法的重要性之所在。打个比方,如果你需要清理你的房子,你可以使用真空吸尘器,扫帚或拖把,但是你不会拿出一把铲子然后开始挖掘。因此,本文介绍另一种算法分类的方法,即通过机器学习所负责的任务来分类。
机器学习的适应场景任务主要有:回归、分类、聚类,推荐、图像识别、启发式学习方式。
1.回归
回归是一种用于建模和预测连续数值变量的监督学习任务。例如预测房地产价格,股价变动或学生考试分数。
回归任务的特征是具有数字目标变量的标记数据集。换句话说,对于每个可用于监督算法的观察结果,您都有一些“基于事实”的数值。
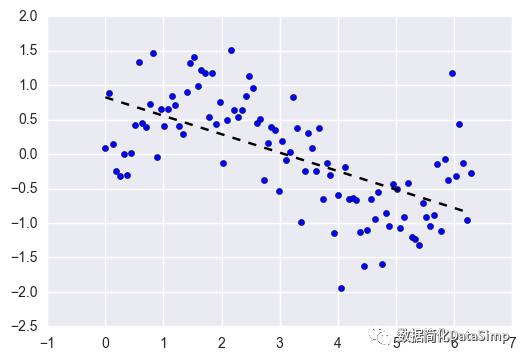
1.1 (正则化)线性回归
线性回归是回归任务中最常用的算法之一。它最简单的形式是试图将一个直的超平面整合到你的数据集中(即当你只有两个变量的时候,你只能得到一条直线)。正如您可能猜到的那样,当数据集的变量之间存在线性关系时,它的效果是非常好的。
实际上,简单的线性回归经常被正则化的同类算法(LASSO,Ridge和Elastic-Net)所忽略。正则化是一种惩罚大系数的技术,以避免过度拟合,它应该调整其惩罚的力度。
优点:线性回归可以直观地理解和解释,并且可以正则化以避免过度拟合。另外,使用随机梯度下降的新数据可以很容易地更新线性模型。
缺点:当存在非线性关系时,线性回归表现不佳。它们本身并不具有足够的灵活性来捕捉更为复杂的模式,对于添加正确的交互作用项或者多项式来说可能会非常棘手和耗时。
实现:Python/R
1.2 回归树(集成)
回归树(决策树的一种)是通过将数据集反复分割成单独的分支来实现分层化学习,从而最大化每个分割信息的增益效果。这种分支结构允许回归树自然地学习非线性关系。
随机森林(RF)和梯度增强树(GBM)等集成方法结合了许多单独树的特性。我们不会在这里介绍他们的基本机制,但是在实践中,随机森林通常表现地非常好,而梯度增强树则很难调整,但是后者往往会有更高的性能上限。
优点:回归树可以学习非线性关系,并且对异常值相当敏锐。在实践中,回归树也表现地非常出色,赢得了许多经典(即非深度学习)的机器学习比赛。
缺点:无约束的单个树很容易过拟合,因为它们可以保持分支直到它们记住了所有的训练数据。但是,这个问题可以通过使用集成的方式来缓解。
实现:随机森林-Python/R,梯度增强树-Python/R
1.3 深度学习
深度学习是指能学习极其复杂模式的多层神经网络。他们使用输入和输出之间的“隐藏层”来模拟其他算法难以学习的数据中介码。
他们有几个重要的机制,如卷积和丢弃,使他们能够有效地从高维数据中学习。然而,与其他算法相比,深度学习仍然需要更多的数据来训练,因为这些模型需要更多的参数来实现其更准确的推测。
优点:深度学习是在诸如计算机视觉和语音识别等领域内,目前可以被利用的最先进的方法。深度神经网络在图像,音频和文本数据上表现地非常出色,可以轻松地使用成批量的传播方法来更新数据。它的体系结构(即层的数量和结构)可以适应许多类型的问题,并且它们的隐藏层减少了对特征工程的需要。
缺点:深度学习算法不适合作为通用算法,因为它们需要大量的数据。事实上,对于传统的机器学习问题,它们的表现通常逊色于决策树。另外,它们需要密集型的计算训练,而且需要更多的专业知识来做调试(即设置架构和超参数)。
实现:Python/R
1.4 特别提及:最近邻居法
最近邻居算法是“基于实例的”,这意味着它会保存每个训练观察的结果。然后,通过搜索最相似的训练观察值并汇集结果,来预测新的观测值。
这些算法是内存密集型的,对于高维度数据的表现不佳,并且需要有意义的距离函数来计算相似度。在实践中,训练正则化回归或决策树可能会更节省你的时间。
转自:数据简化DataSimp
完整内容请点击“阅读原文”





