BAT机器学习面试题1000题(346~350题)

点击上方蓝字关注


BAT机器学习面试题1000题(346~350题)
346题
kmeans的复杂度?
解析:

时间复杂度:O(tKmn),其中,t为迭代次数,K为簇的数目,m为记录数,n为维数
空间复杂度:O((m+K)n),其中,K为簇的数目,m为记录数,n为维数
347题
请说说随机梯度下降法的问题和挑战?
解析:




348题
说说共轭梯度法?
解析:
共轭梯度法是介于梯度下降法(最速下降法)与牛顿法之间的一个方法,它仅需利用一阶导数信息,但克服了梯度下降法收敛慢的缺点,又避免了牛顿法需要存储和计算Hessian矩阵并求逆的缺点,共轭梯度法不仅是解决大型线性方程组最有用的方法之一,也是解大型非线性最优化最有效的算法之一。在各种优化算法中,共轭梯度法是非常重要的一种。其优点是所需存储量小,具有逐步收敛性,稳定性高,而且不需要任何外来参数。
下图为共轭梯度法和梯度下降法搜索最优解的路径对比示意图:
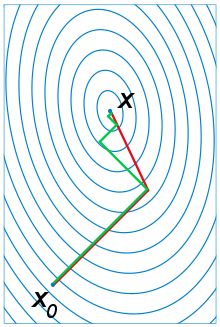
注:绿色为梯度下降法,红色代表共轭梯度法
本题解析来源: @wtq1993,链接:http://blog.csdn.net/wtq1993/article/details/51607040
349题
对所有优化问题来说, 有没有可能找到比現在已知算法更好的算法?
解析:
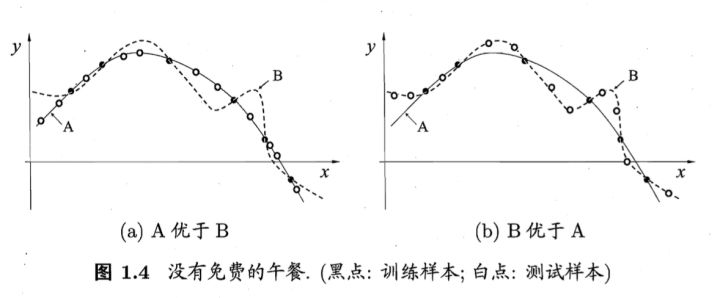
没有免费的午餐定理:
对于训练样本(黑点),不同的算法A/B在不同的测试样本(白点)中有不同的表现,这表示:对于一个学习算法A,若它在某些问题上比学习算法 B更好,则必然存在一些问题,在那里B比A好。
也就是说:对于所有问题,无论学习算法A多聪明,学习算法 B多笨拙,它们的期望性能相同。
但是:没有免费午餐定力假设所有问题出现几率相同,实际应用中,不同的场景,会有不同的问题分布,所以,在优化算法时,针对具体问题进行分析,是算法优化的核心所在。
本题解析来源:@抽象猴,链接:https://www.zhihu.com/question/41233373/answer/145404190
350题
什么是最大熵
解析:
熵是随机变量不确定性的度量,不确定性越大,熵值越大;若随机变量退化成定值,熵为0。如果没有外界干扰,随机变量总是趋向于无序,在经过足够时间的稳定演化,它应该能够达到的最大程度的熵。
为了准确的估计随机变量的状态,我们一般习惯性最大化熵,认为在所有可能的概率模型(分布)的集合中,熵最大的模型是最好的模型。换言之,在已知部分知识的前提下,关于未知分布最合理的推断就是符合已知知识最不确定或最随机的推断,其原则是承认已知事物(知识),且对未知事物不做任何假设,没有任何偏见。
例如,投掷一个骰子,如果问"每个面朝上的概率分别是多少",你会说是等概率,即各点出现的概率均为1/6。因为对这个"一无所知"的色子,什么都不确定,而假定它每一个朝上概率均等则是最合理的做法。从投资的角度来看,这是风险最小的做法,而从信息论的角度讲,就是保留了最大的不确定性,也就是说让熵达到最大。
3.1 无偏原则
下面再举个大多数有关最大熵模型的文章中都喜欢举的一个例子。
例如,一篇文章中出现了“学习”这个词,那这个词是主语、谓语、还是宾语呢?换言之,已知“学习”可能是动词,也可能是名词,故“学习”可以被标为主语、谓语、宾语、定语等等。
令x1表示“学习”被标为名词, x2表示“学习”被标为动词。
令y1表示“学习”被标为主语, y2表示被标为谓语, y3表示宾语, y4表示定语。
且这些概率值加起来的和必为1,即
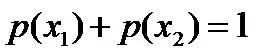
则根据无偏原则,认为这个分布中取各个值的概率是相等的,故得到:
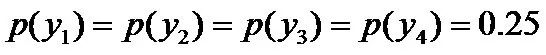
因为没有任何的先验知识,所以这种判断是合理的。如果有了一定的先验知识呢?
即进一步,若已知:“学习”被标为定语的可能性很小,只有0.05,即
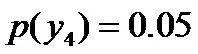
剩下的依然根据无偏原则,可得:
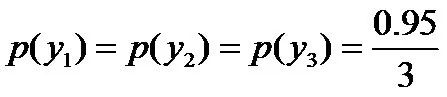
再进一步,当“学习”被标作名词x1的时候,它被标作谓语y2的概率为0.95,即
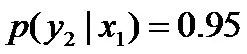
此时仍然需要坚持无偏见原则,使得概率分布尽量平均。但怎么样才能得到尽量无偏见的分布?
实践经验和理论计算都告诉我们,在完全无约束状态下,均匀分布等价于熵最大(有约束的情况下,不一定是概率相等的均匀分布。 比如,给定均值和方差,熵最大的分布就变成了正态分布 )。
于是,问题便转化为了:计算X和Y的分布,使得H(Y|X)达到最大值,并且满足下述条件:
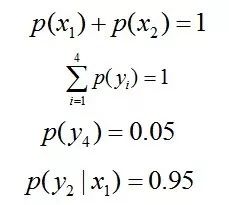
因此,也就引出了最大熵模型的本质,它要解决的问题就是已知X,计算Y的概率,且尽可能让Y的概率最大(实践中,X可能是某单词的上下文信息,Y是该单词翻译成me,I,us、we的各自概率),从而根据已有信息,尽可能最准确的推测未知信息,这就是最大熵模型所要解决的问题。
相当于已知X,计算Y的最大可能的概率,转换成公式,便是要最大化下述式子H(Y|X):
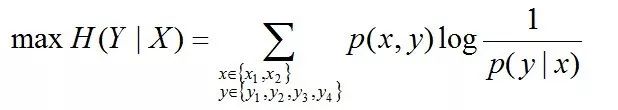
且满足以下4个约束条件:
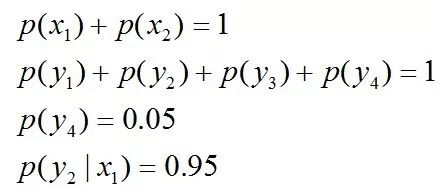
分享一哈
亲耐滴小伙伴们,8月中旬喽,每年的三四月份、和八九月份,都是各大企业狂招人的季节,也是跳槽涨薪的最佳时节喔,想跳槽转行的亲们抓好机遇啦。
之前第一期,不到一个月,30人的名额很快招满,毕业之后有的不到半个月,便拿到30万offer,甚至更多。
现在为了更好的冲刺秋季转行转岗转型的黄金季节,拿下dream offer,我们推出了【AI就业班 二期】,此期特在一期基础上,进一步改进,推出
BAT大咖一对一定向辅导+包就业,更好的课程体系和服务,报名即学,报名截止到8月底,还有半个月时间喔,想转行跳槽的小伙伴们抓紧时间喽~~
(ps:点击下方“阅读原文”可在线报名,详细可添加客服咨询:julyedukefu_02)


更多资讯
请戳一戳


往期精选
45万AI面经 | 面试offer拿不停,人称“offer收割机”
Kaggle CTO 力荐 | 从Kaggle历史数据看竞赛趋势
干货合集 | 教你如何使用Excel 9步实现卷积网络

点击“阅读原文”,可在线报名



