CVPR 2020 | 港中文提出3D目标检测新框架DSGN

©PaperWeekly 原创 · 作者|张承灏
学校|中科院自动化所硕士生
研究方向|双目深度估计
本文介绍的是香港中文大学贾佳亚团队在 CVPR 2020 上提出的 3D 目标检测新框架——深度立体几何网络(Deep Stereo Geometry Network,DSGN)。

论文标题:DSGN: Deep Stereo Geometry Network for 3D Object Detection
论文地址:https://arxiv.org/abs/2001.03398
开源代码:https://github.com/chenyilun95/DSGN


背景
根据特征的表示方法不同,3D 目标检测器主要分为基于图像的 3D 检测器和基于 LiDAR 的 3D 检测器。
基于 LiRAD 的 3D 检测器:主要分为基于体素的方法和基于点云的方法;
-
基于图像的 3D 检测器:主要分为基于深度估计的方法和基于 3D 特征的方法;
基于深度估计的方法将 3D 目标检测分为两步:深度估计和目标检测,这其中最大的挑战在于 2D 网络并不能提取到稳定的 3D 信息。
另一种方案是先利用深度估计产生中间伪点云,再利用基于 LiDAR 的 3D 目标检测方法。但是这种方法中的变换是不可导的,并且需要多个独立的网络,还容易出现失真现象。
DSGN 是一种基于双目深度估计的,端到端的 3D 目标检测框架,其核心在于通过空间变换将 2D 特征转换成有效的 3D 结构。论文的主要贡献如下:
-
为了弥补 2D 图像和 3D 空间的鸿沟,作者利用立体匹配构建平面扫描体(plane-sweep volume,PSV),并将其转换成 3D 几何体(3D geometric volume,3DGV),以便能够编码 3D 几何形状和语义信息。 -
作者设计了一个端到端的框架,以提取用于立体匹配的像素级特征和用于目标识别的高级特征。所提出的 DSGN 能同时估计场景深度并检测 3D 目标,从而实现多种实际应用。 作者提出的简单且完全可导的网络在 KITTI 排行榜上超越所有其他基于双目深度估计的 3D 目标检测器(AP 高出 10 个点)。

方法
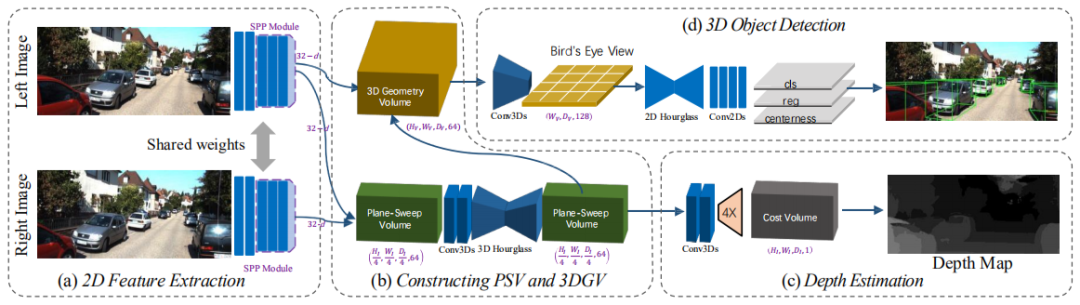
2.1 特征提取
将更多的计算从 conv_3 转到 conv_4 和 conv_5,比如从 conv_2 到 conv_5 的基本模块的通道数从 {3,16,3,3} 变成 {3,6,12,4}。
PSMNet 中的 SPP 模块增加了 conv_4 和 conv_5。
-
conv_1 的输出通道数和残差模块的输出通道数有所改变。
详细的网络结构可参考论文中的附录部分。
2.2 构建3DGV
2.3 Plane-Sweep Volume
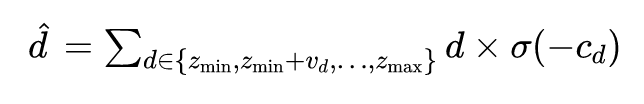
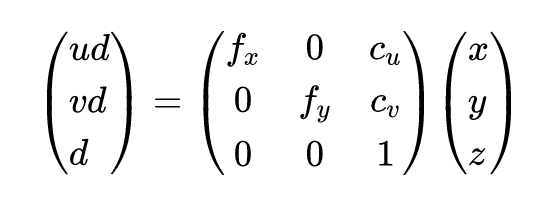
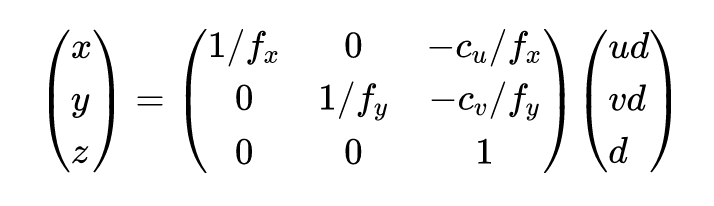
对于 3D 目标检测网络部分,作者借鉴 anchor-free 的方法 FCOS [2] 中的centerness思想,设计了一种基于距离的策略来分配目标,同时也继续保持anchor。
-
Anchors: -
GT: -
预测值:
沿用 FCOS 中的 centerness 思想,作者利用 anchor 和 GT 在 8 个角上的坐标距离作为目标分配的策略:
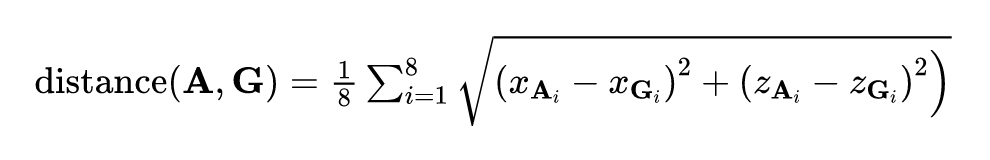
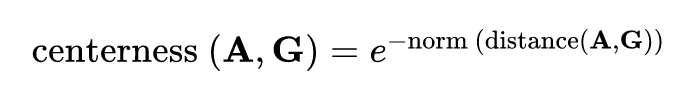
DSGN 的整个网络同时进行双目深度估计和 3D 目标检测,因此是一个多任务训练过程,整体 loss 如下:
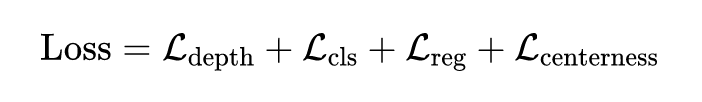
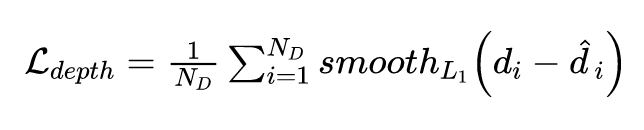
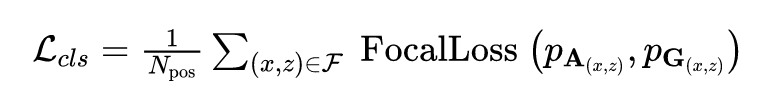
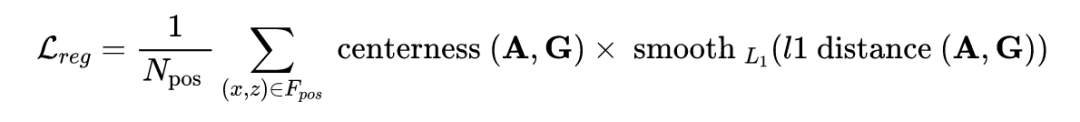

作者在 KITTI 3D 目标检测数据集上进行实验评测,该数据集包含 7481 张训练图像对和 7518 张测试图像对,分为 Car, Pedestrian 和 Cyclist 三种类型。下面是在测试集上的主要结果:
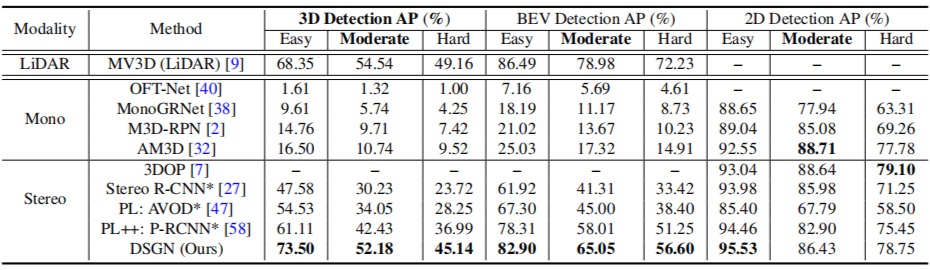
从表中可以看出,对于 3D 和 BEV(Bird's Eye View)目标检测,DSGN 超越了所有基于图像的 3D 目标检测器;在 2D 检测上,也仅仅比 3DOP 要差一点。
值得一提的是,DSGN 首次得到了与基于 LiDAR 的目标检测器 MV3D 相当的准确率,该结果证明至少在低速自动驾驶条件下是有应用前景的。这些都验证了 3DGV 的有效性,表明 3DGV 构建了 2D 图像和 3D 空间的桥梁。
作者将训练集分成一半训练集,一半验证集进行消融分析,下面是消融实验的结果:
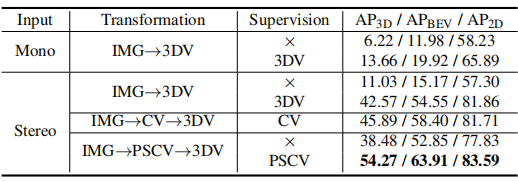
从上表中可以得到以下几个结论:
-
点云的监督是很重要的。有点云监督的结果要大大优于没有监督的情况。 -
在有点云监督的情况下,基于双目的方法要远远优于基于单目的方法。再次证明仅仅有 3D 检测框的监督信息是不充分的,基于双目的深度信息对于 3D 检测相当重要。 -
PSV 对于 3D 结构是一种更合适的特征表示。PSCV 相比于 CV 的不同在于从相机坐标系到世界坐标系的转换,对于 3D 检测 AP 从 45.89 提升到 54.27。 -
PSV 作为一种中间编码方式能更有效地包含深度信息,因为它是深度估计网络的中间特征。

讨论和总结
DSGN 是 one-stage 的目标检测器,而 Stereo RCNN 是 two-stage 的。
DSGN 利用了深度点云信息作为深度估计网络的监督,从而实现深度估计和3D目标检测的多任务学习,而 Stereo RCNN 仅有 3D 检测框的监督信息。这种点云监督信息使得DSGN中的 PSV 成为更好的特征表示,这可能是 DSGN 性能大大提升的根本所在。
从目标检测的角度看,二者都采用了 anchor,不过 DSGN 借鉴了 anchor-free 的 centerness 思想,使得检测性能更优。
参考文献

点击以下标题查看更多往期内容:

#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。



