SIGIR2022 | 基于领域交互的点击率预估模型
来源:机器之心

论文标题:
Neighbour Interaction based Click-Through Rate Prediction via Graph-masked Transformer
https://dl.acm.org/doi/abs/10.1145/3477495.3532031
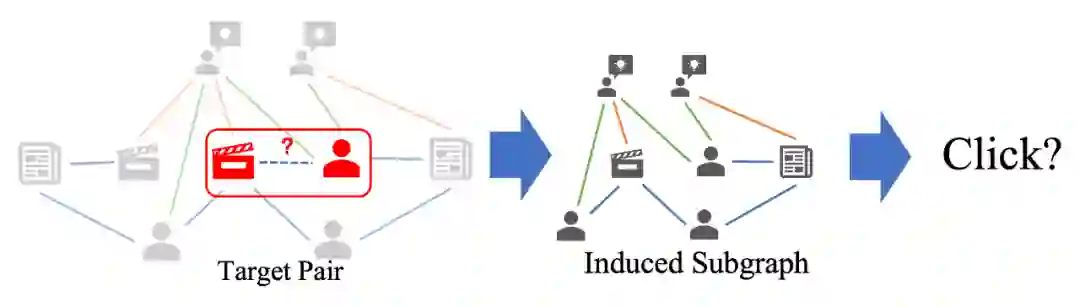
在线广告和产品搜索中,点击率(CTR)是商业评估的一个关键指标,它衡量用户点击或与候选项目互动的概率。对于拥有庞大用户群的应用来说,即使是对 CTR 的微小改进,也有可能促进整体收入的大幅增长。虽然现有的 CTR 预测方法已经取得了重大进展,但上述方法只注重挖掘候选物品与用户历史行为之间的互动关系,存在两个局限性。一方面,对于不活跃的用户来说,用户行为可能是稀疏的,这就产生了一个冷启动问题,降低了表示的质量。另一方面,由于推荐系统曝光率的限制,一个用户的直接相关物品不足以反映其所有的潜在兴趣。

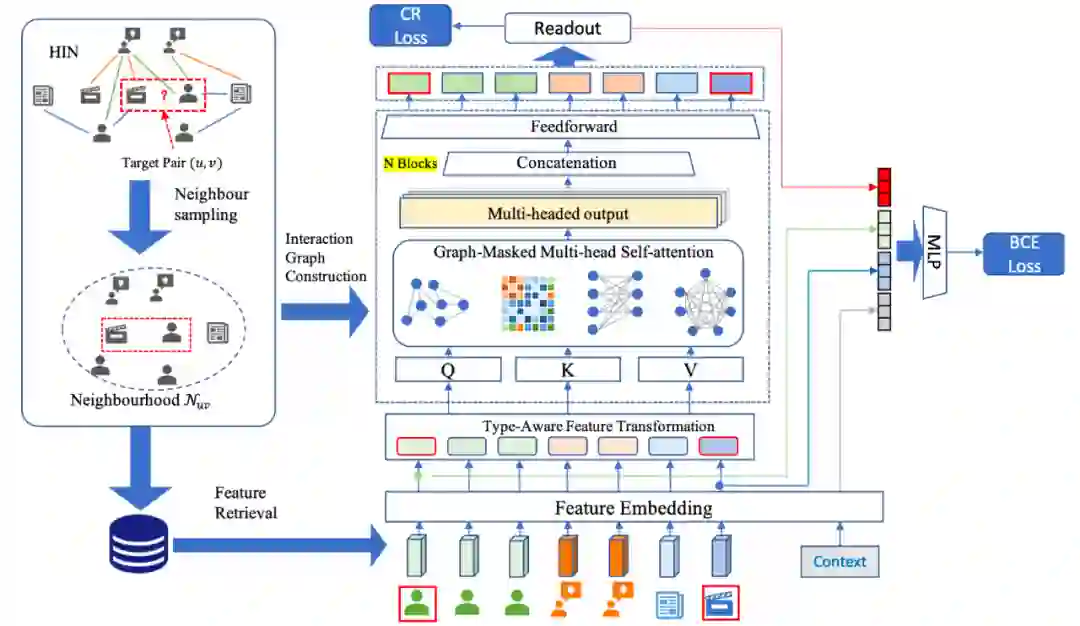
问题建模
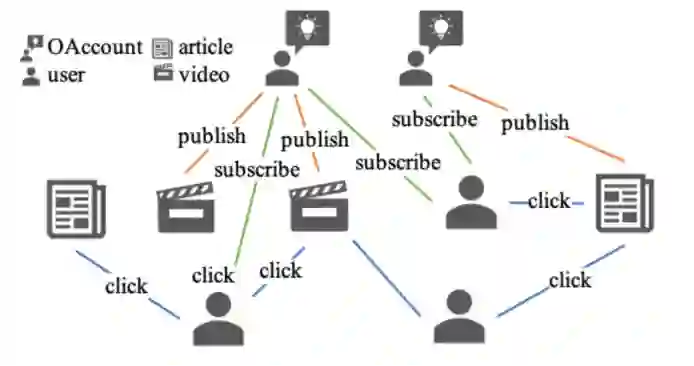
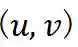 ,为了能够扩展对用户点击偏好的描述,我们在这一异构图上采样一个和
相关的一个邻域节点集合
,为了能够扩展对用户点击偏好的描述,我们在这一异构图上采样一个和
相关的一个邻域节点集合
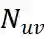 以及对应的子图
以及对应的子图
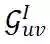 ,并且将点击率预测这一问题转化为对这一邻域分类问题。
,并且将点击率预测这一问题转化为对这一邻域分类问题。
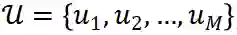 , 一组 N 物品
, 一组 N 物品
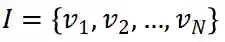 。用户与项目的相互作用被表示为一个矩阵
。用户与项目的相互作用被表示为一个矩阵
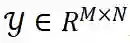 , 其中
, 其中
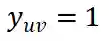 表示用户 u 之前点击了项目 v , 否则
表示用户 u 之前点击了项目 v , 否则
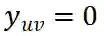 。给出任务相关的
。给出任务相关的
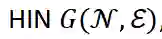 , 如第 2.3.2 节所述, 我们可以为每个候选用户 u 和 项目 v 对抽取一批邻近节点
, 如第 2.3.2 节所述, 我们可以为每个候选用户 u 和 项目 v 对抽取一批邻近节点
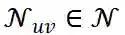 。每个节点
。每个节点
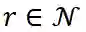 都与一个特征向量相关联, 如第 2.3.1 章节所述, 因此我们将采样的
都与一个特征向量相关联, 如第 2.3.1 章节所述, 因此我们将采样的
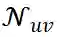 的特征向量集表示为
的特征向量集表示为
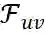 。此外, 我们将背景特征(如时间、匹配方法、匹配得分)表示为 C 。因此, 一个
。此外, 我们将背景特征(如时间、匹配方法、匹配得分)表示为 C 。因此, 一个
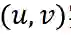 实例可以表示为:
实例可以表示为:
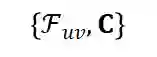
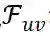 和背景特征 C 预测用户 u 点击物品 v 的概率。
和背景特征 C 预测用户 u 点击物品 v 的概率。

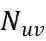 采样;
采样;
以下对各个模块分别进行介绍。
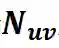 集合采样
集合采样
1. 尽可能多地对目标最接近的节点进行采样。
2. 通过限制对每种类型节点采样的个数来限制复杂度。
3. 采样到的节点和目标节点 r 有尽可能多的边。
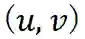 采样得到其邻域集合
采样得到其邻域集合
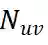 。
。

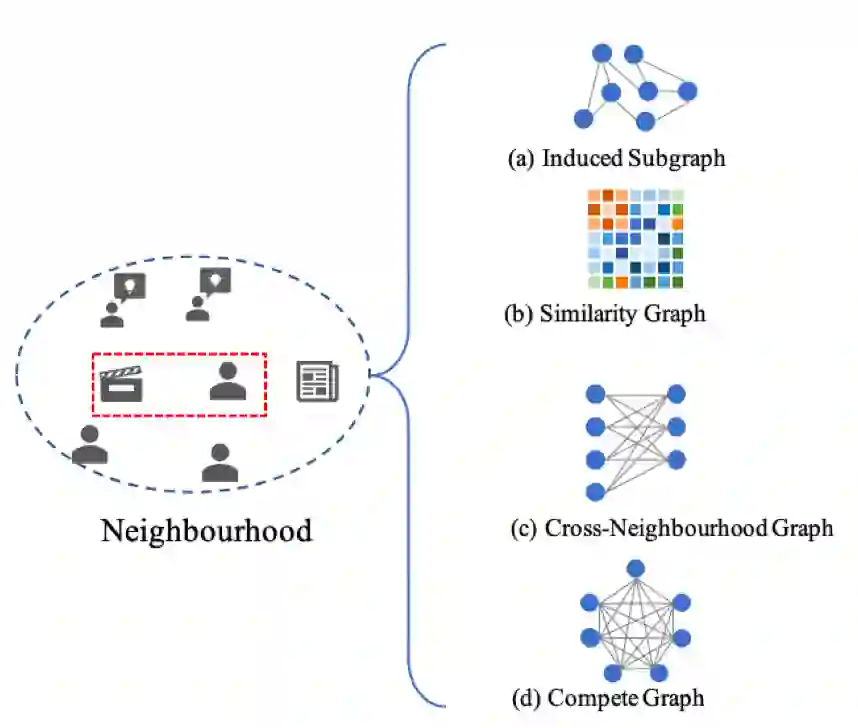
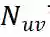 节点交互的可能性。具体的,我们构建了四种不同交互图:
节点交互的可能性。具体的,我们构建了四种不同交互图:
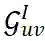 :用于建模自然交互的导出子图,代表了原始异构图上的交互信息。
:用于建模自然交互的导出子图,代表了原始异构图上的交互信息。
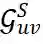 :用于建模节点特征相似性图,代表了节点特征层面的交互信息,通过特性相似性, 可以捕捉到节点特征层面的语义信息。
:用于建模节点特征相似性图,代表了节点特征层面的交互信息,通过特性相似性, 可以捕捉到节点特征层面的语义信息。
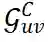 :用于捕捉用户邻域和物品邻域间交互的交叉邻域二分图,代表了用户和物品的邻域的节点之间可能的交互信息。
:用于捕捉用户邻域和物品邻域间交互的交叉邻域二分图,代表了用户和物品的邻域的节点之间可能的交互信息。
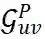 :用于建模邻域中任何节点间交互的完全图。代表了任何两个节点之间可能的交互信息。
:用于建模邻域中任何节点间交互的完全图。代表了任何两个节点之间可能的交互信息。
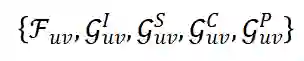
 中的节点 i, 由于不同类型的节点具有不同的特征维度, 因此具有不同的特征空间,这里,为了能够统一处理异质节点的情况,我们使用类型感知的特征转换层将它们嵌入到一个统一的空间:
中的节点 i, 由于不同类型的节点具有不同的特征维度, 因此具有不同的特征空间,这里,为了能够统一处理异质节点的情况,我们使用类型感知的特征转换层将它们嵌入到一个统一的空间:
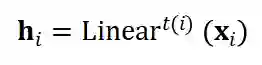
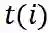 是第 i 个节点的类型, 而
是第 i 个节点的类型, 而
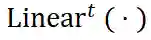 是第 t 类节点类型的线性层, 不同类型的节点具有不同的可学习参数。
是第 t 类节点类型的线性层, 不同类型的节点具有不同的可学习参数。
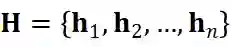 ,和的交互图邻接矩阵 M,我们定义了 Masked Attention:
,和的交互图邻接矩阵 M,我们定义了 Masked Attention:
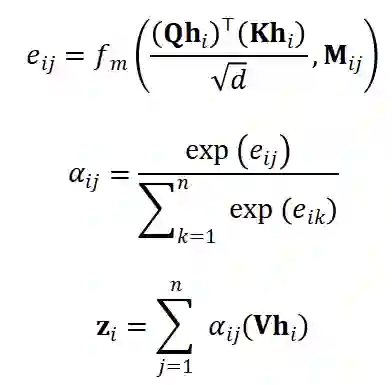
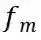 为掩码函数:
为掩码函数:
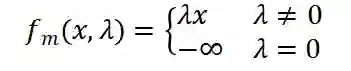
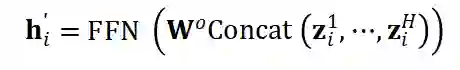
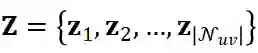 。
。
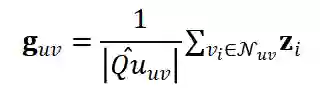
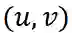 的邻域表示
的邻域表示
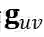 后。为了突出两个目标节点的本身特征, 我们将它们的初始稠密嵌入
后。为了突出两个目标节点的本身特征, 我们将它们的初始稠密嵌入
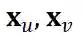 与邻域表示
与邻域表示
 和上下文特征 C 串联起来。因此, 数据实例的最终嵌入是:
和上下文特征 C 串联起来。因此, 数据实例的最终嵌入是:
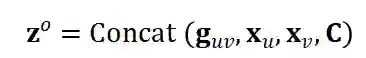
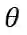 的 MLP 层
的 MLP 层
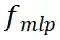 和一个 Sigmoid 函数
和一个 Sigmoid 函数
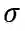 来预测用户 u 会点击目标物品 v 的概率:
来预测用户 u 会点击目标物品 v 的概率:
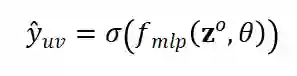
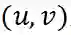 对,因为每次从 HIN 采样得到的邻域信息
对,因为每次从 HIN 采样得到的邻域信息
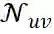 都不相同,为了使得训练未定,在对
都不相同,为了使得训练未定,在对
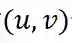 进行 S 次采样得到
进行 S 次采样得到
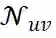 的预测平均作来作交叉熵损失:
的预测平均作来作交叉熵损失:
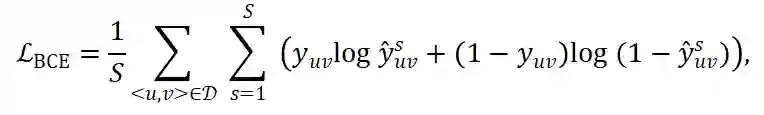
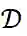 是训练集,
是训练集,
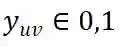 是点击的真实标签。同时为了提升模型训练稳定性,我们采用了一个一致性正则化项的变体来强制使得对同一
是点击的真实标签。同时为了提升模型训练稳定性,我们采用了一个一致性正则化项的变体来强制使得对同一
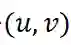 对采样学到的表示尽可能一致:
对采样学到的表示尽可能一致:
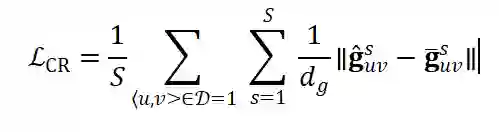
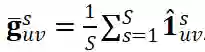 , 而
, 而
 的维度。最终训练的损失函数为:
的维度。最终训练的损失函数为:
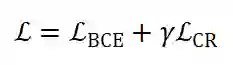

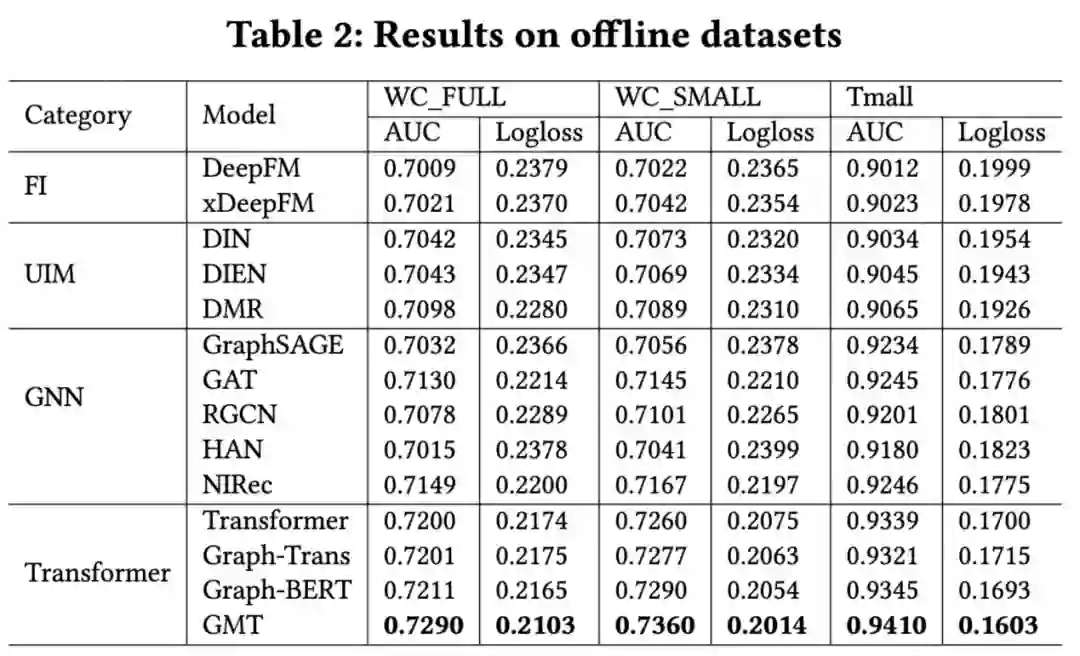
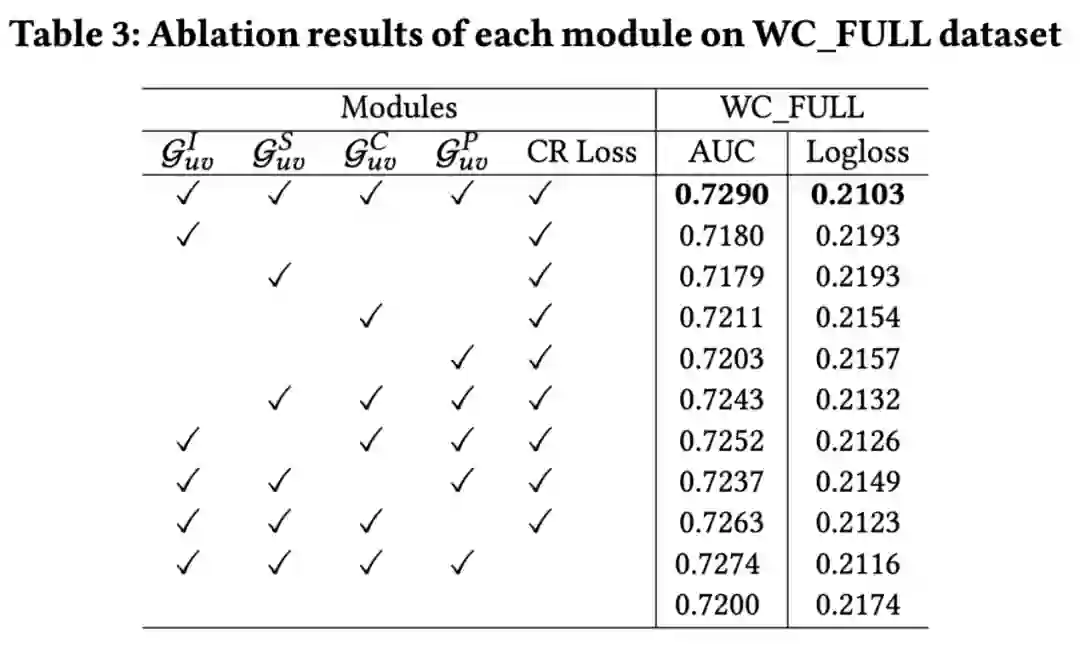
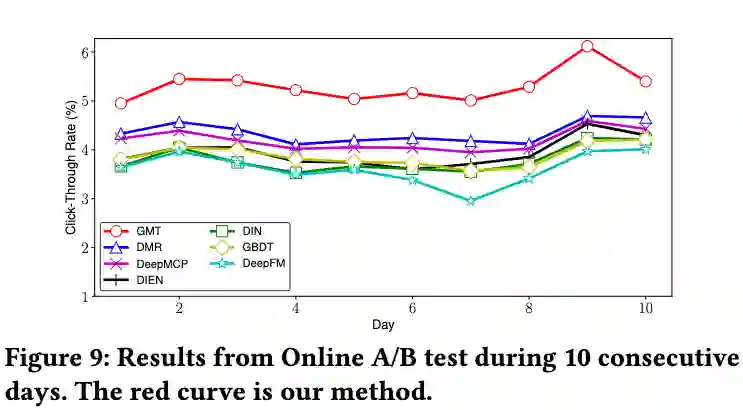
为了更好地建模子图中存在的显式和隐式关系,我们探索了多种邻域节点的交互表示,并且设计了一种简洁的 Masked-Graph Transformer 结构来加入对多种交互表示的先验信息的建模。同时我们还引入了一致性正则化来增强模型的稳健性。我们通过离线和在线的实验验证了基于邻域交互图建模的模型的有效性,并证明了所提出的图掩码转换器的优越性和灵活性。我们还成功地将整个框架部署到一个拥有数十亿用户和物品的工业场景中,并在实际应用中获得了显著的 CTR 提升。
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。