KDD2022 | 基于自监督超图Transformer的推荐算法研究
标题:Self-Supervised Hypergraph Transformer for Recommender Systems
链接:https://arxiv.org/pdf/2207.14338.pdf
代码:https://github.com/akaxlh/SHT
会议:KDD 2022
学校:港大
1. 导读
现有基于 GNN 的推荐系统的思想是递归地执行沿用户-商品交互边传递消息,从而得到相应的embedding。尽管它们很有效,但大多数当前的推荐模型都依赖于充足且高质量的训练数据,因此学习的表征可以很好地捕捉用户偏好。许多实际推荐场景中的用户行为数据通常是嘈杂的并且呈现出偏态分布,这可能导致基于 GNN 的模型中的表征性能欠佳。本文提出了 SHT,自监督超图Transformer框架 (SHT),它通过以显式方式探索全局协作关系来增强用户表征。具体来说,利用图协同过滤范式使用超图Transformer来维持用户和商品之间的全局协作效果。利用提炼的全局上下文,提出了一种跨视图生成自监督学习组件,用于在用户-商品交互图上进行数据增强,以增强推荐系统的鲁棒性。
2. 方法

2.1 局部图结构学习
首先,将用户和商品嵌入到 d 维潜在空间中,以编码他们的交互模式。对于用户 和商品 ,分别生成embedding向量 。聚合所有用户和商品embedding构成相应的矩阵 , 。
局部结构的学习采用常见的图神经网络方式,将每个节点的相邻子图结构编码为图拓扑感知embedding,以将拓扑位置信息注入图Transformer。SHT 采用了一个两层的轻量级图卷积网络,如下所示,其中 表示标准化后的图邻接矩阵,计算方式为,D分别为用户和商品的度矩阵。
2.2 超图Transformer学习全局关系
SHT 采用了超图Transformer框架,
-
i) 通过使用自适应超图关系学习增强用户协作关系建模来缓解噪声问题; -
ii) 将知识从密集的用户/商品节点迁移到稀疏节点。
具体来说,SHT 使用了类似于 Transformer 的注意力机制,用于结构学习。编码的图拓扑感知embedding被注入到节点表征中以保留图局部性和拓扑位置。同时,多通道注意力进一步促进在 SHT 中的结构学习。
SHT 通过将对应于id的embedding( )与拓扑感知embedding结合生成输入的用户和商品embedding,表示如下,然后,SHT 使用 作为输入进行基于超图的信息传播和超图结构学习。利用K个超边从全局角度提炼协作关系。
2.2.1 节点到超边的信息传播
商品和用户的表示是类似的,这里以用户节点为例。从用户节点到用户侧超边的传播可以表示如下,其中 表示第k条超边的embedding,通过拼接H个头的超边embedding得到,通过注意力机制计算得到H个头的embedding。
q,k,v的计算方式如下,Z为K条超边的embedding矩阵,K,V为相应的权重
为了进一步挖掘超边之间复杂的非线性特征交互,SHT 在用户侧和商品侧都增加了两层分层超图神经网络。最终的超边embedding通过以下方式计算,H为可学习参数,
2.2.2 超边到节点的信息传播
使用最终的超边embedding ,通过类似但相反的过程将信息从超边传播到用户/商品节点, 为用户 的新embedding,q,k,v的计算方式与前面类似,具体公式如下,
2.2.3 交替超图传播
通过堆叠多个超图Transformer层来进一步传播编码的全局协作关系。通过这种方式,SHT 框架可以通过迭代超图传播来表征远距离用户/商品依赖关系。以第 次迭代中的embedding表 作为输入,SHT 递归地应用超图编码(由 HyperTrans(·) 表示)并获得最终节点embedding ,公式如下,
预测用户 和商品 的分数为
2.3 局部全局自增强学习
超图Transformer可以解决数据稀疏的问题,但是,用于局部协作关系建模的图拓扑感知embedding可能仍会受到交互数据噪声的影响。为了应对这一挑战,作者通过局部拓扑感知embedding和全局超图学习之间的自增强学习来增强模型训练。具体来说,用于局部信息提取的拓扑感知embedding增加了一项额外的任务,以区分观察到的用户-商品交互图中采样边的稳固性。这里,solidity 是指边没有噪声的概率,它在增强任务中的标签是根据学习到的超图依赖关系和表征来计算的。通过这种方式,SHT 将知识从超图Transformer中的高级和去噪特征迁移到低级和嘈杂的拓扑感知embedding,这有助于重新校准局部图结构并提高模型的鲁棒性。流程如图 2 所示。
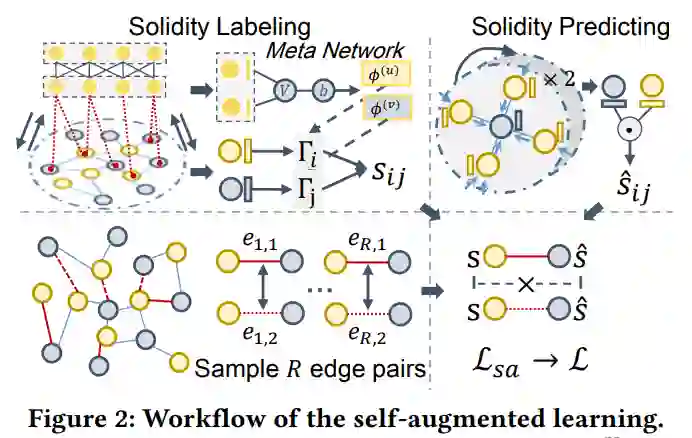
2.3.1 元网络的 Solidity 标签
在SHT 模型中,学习的超图依赖表征可以作为有用的知识,通过将每条边与学习的可靠性分数相关联来对观察到的用户-商品交互进行降噪。具体来说,在估计边 的可靠性分数时重用key embedding 来表示用户 和商品 。这是因为key向量是为关系建模而生成的,可以被认为是交互可靠性估计的有用信息源。此外,将超边embedding Z,将全局特征引入到可靠性标记中。具体来说,首先连接多头key向量并应用一个简单的感知机来消除用户/商品超边关系学习和用户-商品关系学习之间的差距。更新的用户/商品embedding计算方式如下,其中 为感知机,
使用更新的用户/商品embedding ,SHT 通过两层神经网络计算边 的可靠性标签,如下所示,
其中 表示超图Transformer给出的可靠性分数。sigm(·) 表示限制 𝑠𝑖,𝑗 取值范围的 sigmoid 函数。d, c为可学习参数。
2.3.2 成对的 Solidity 排名
为了增强拓扑embedding的优化,SHT 采用了一个额外的目标函数,以使用上述 作为训练标签来更好地估计边的Solidity 。对 G 中观察到的边的R对边进行采样,然后SHT 使用拓扑感知embedding预测solidity。损失函数如下,其中 为预测的solidity分数,s为上述通过Transformer得到的标签。
2.4 模型学习
采样得到R'条正样本边和负样本边,构建为, 分别表示正负样本。构建损失函数如下,
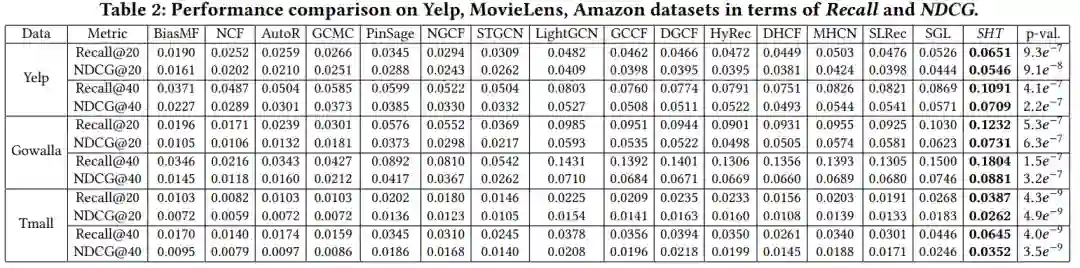
3. 结果
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。


