构建 GNN 的「统一场」:从与 WL 算法、组合优化算法的联系看 GNN 的表达能力

编辑 | 丛 末

原文地址:https://arxiv.org/pdf/2003.04078v1.pdf
本文是一篇来自京都大学的图神经网络表达能力综述,从 GNN、WL 算法、组合优化问题之间的联系入手,进行了深入的归纳和分析。内容涉及计算机网络通信、网络算法,组合数学、可计算性分析等方面,内容非常丰富,其融会贯通的能力令人叹为观止!
1、数学符号
表一为本文中使用到的数学符号:
表一:数学符号

{...} 表示一个集合,{{...}} 表示一个多重集。 在多重集之中,同一个元素可以出现多次。例如,{3,3,4} = {3,4},但是{{3,3,4}} ≠ {3,4}。有时,我们将一个集合看做一个多重集,反之亦然。
对于每个正数 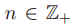
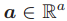
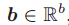
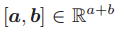
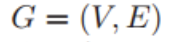
对于每个节点 v 来说,N(v) 代表 v 的邻居节点的集合,deg(v) 代表 v 的邻居节点的个数。如果一张图包含节点特征向量 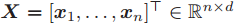
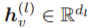
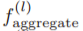
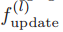

为输入图中度的最大值;b(k) 代表第 k 个贝尔数;H(k) 为第 k 个调和数
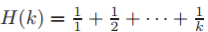
2、 问题设定
本文重点关注以下的节点分类问题和图分类问题。
1)节点分类问题
输入:一张图 G=(V,E,X),其中每个节点 v∈V
输出:v 的标签 y_v
2)图分类问题
输入:一张图 G=(V,E,X)
输出:图 G 的标签 y_G
具体来说,我们考虑的是 GNN 可以计算的函数 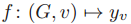
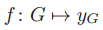
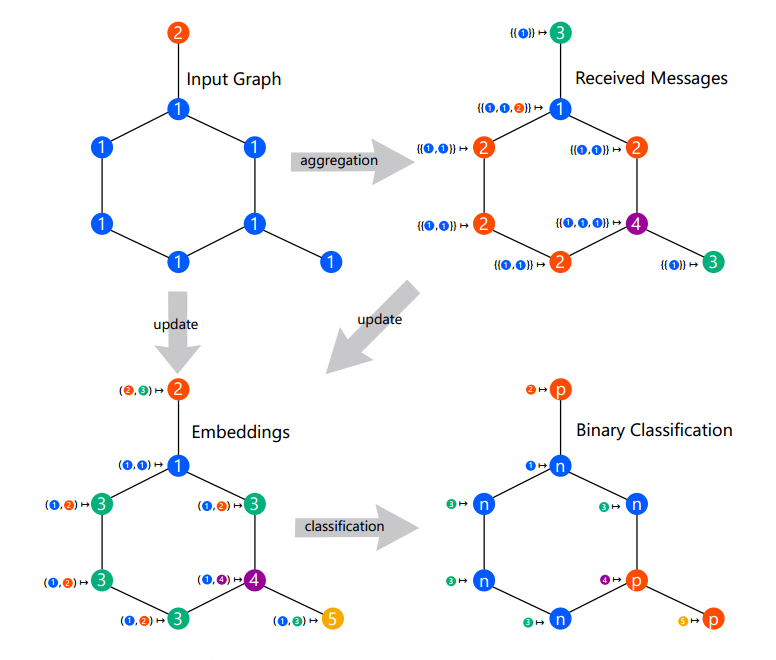
图 1:单层消息传递图神经网络
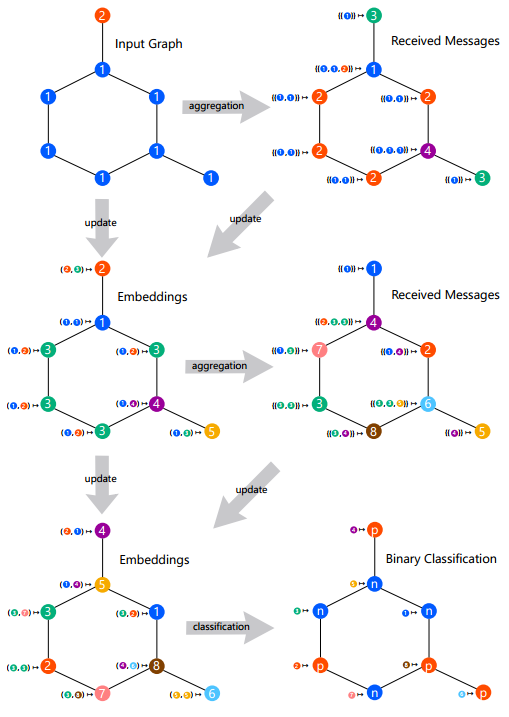
图 2:双层消息传递图神经网络
2)消息传递机制
 和
和
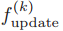 都是参数化函数。在这里,
都是参数化函数。在这里,
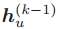 可以被看做节点 u 在第 k 个消息传递阶段中的「消息」。每个节点将聚合它们邻居节点的消息,从而计算出下一个消息或嵌入。GNN 基于最终的嵌入
可以被看做节点 u 在第 k 个消息传递阶段中的「消息」。每个节点将聚合它们邻居节点的消息,从而计算出下一个消息或嵌入。GNN 基于最终的嵌入
除了结构上的限制,一般而言, 
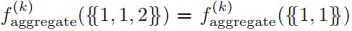
在图分类问题中,GNN 使用读出函数计算图嵌入 :
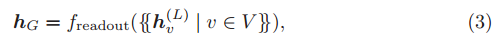
其中, 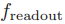
对图 G 进行分类。典型的 GNN 模型可以通过如下所示的消息传递框架形式化定义。
GraphSAGE-mean(详见 Hamilton 等人于 2017 年发表的论文「Inductive representation learning on large graphs」):
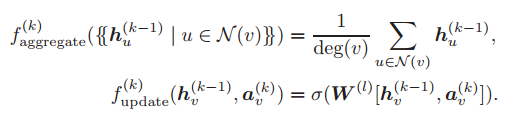
其中 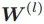
图卷积网络(GCN,详见 Kipf 和 Welling 等人于 2017 年发表的论文「Deep models of interactions across sets」):
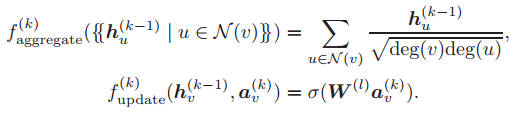
图注意力网络(GAT,详见 Velickovic 等人于 2018 年发表的论文「Weak models of distributed computing, with connections to modal logic」):
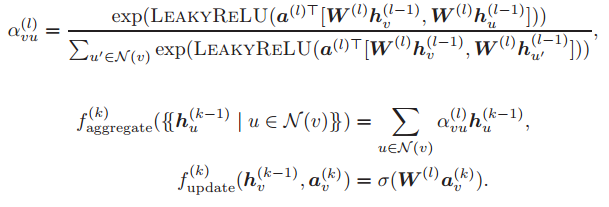
严格来说,在这些模型中, 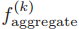
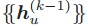
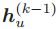
Gilmer 等人于 2017 年发表的论文「Neural message passing for quantum chemistry」介绍了许多其它的消息传递 GNN 的示例。
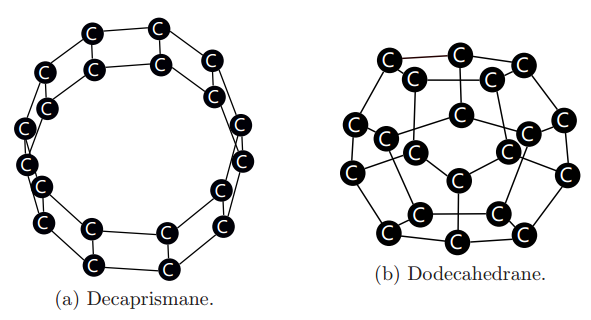
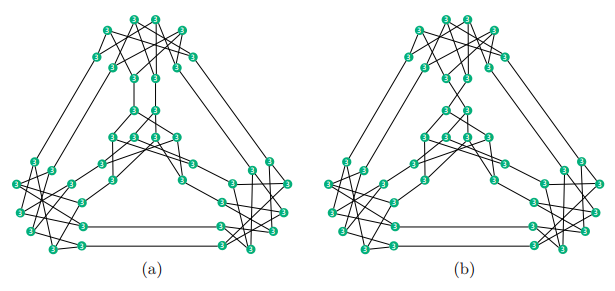
图 3:GNN 不能区分上面两种分子,因为它们都是包含 20 个节点的 3-正则图。
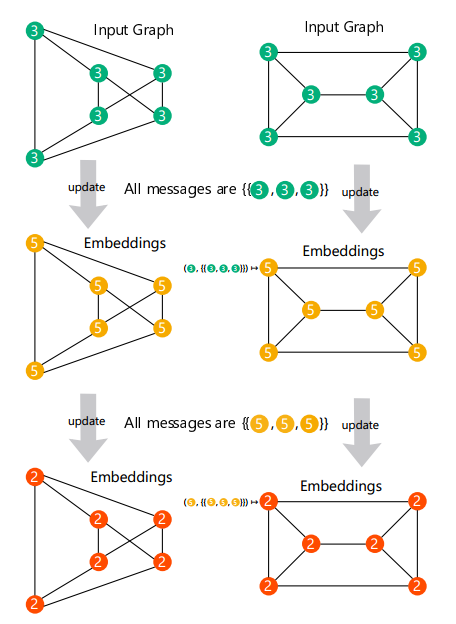
图 4:消息传递 GNN 并不能将任何一对具有相同的度和尺寸的正则图区分开来(即使他们并不是同构的)
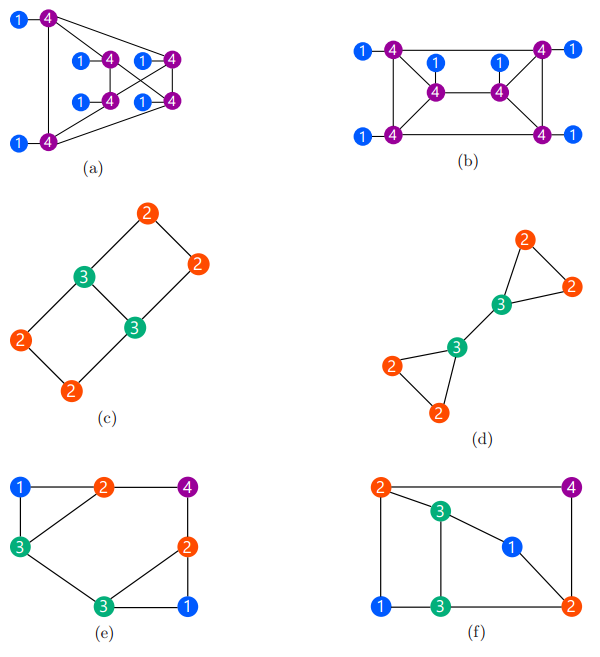
图 5:尽管这些图并不是同构的,但是 GNN 也无法将 a 和 b、c 和 d、e 和 f 区分开来
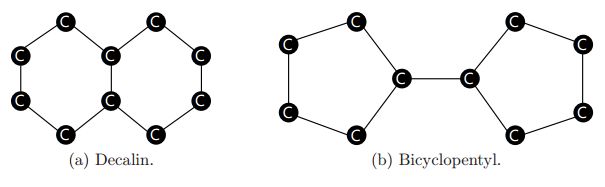
图 6:GNN 无法将这两种分子区分开来,即使这些图不是同构或正则的
-
输入:一对图 G=(V,E,X)和 H=(U,F,Y) -
输出:确定是否存在一种双射 使得
且
当且仅当
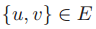
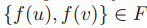
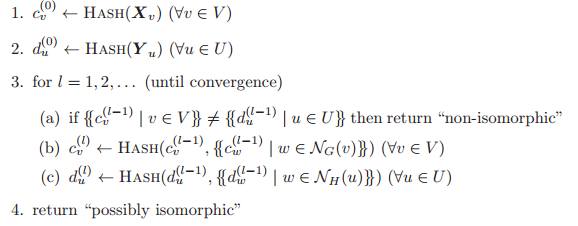
 的迭代过程之内完成。
的迭代过程之内完成。

 是第 i 个邻居节点,它使用 G 中的每个节点替换 k 元组中的第 i 个元素。「HASH」是一种单射的哈希函数,它为相同的同构型赋予相同的颜色。
是第 i 个邻居节点,它使用 G 中的每个节点替换 k 元组中的第 i 个元素。「HASH」是一种单射的哈希函数,它为相同的同构型赋予相同的颜色。
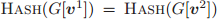 当且仅当
当且仅当
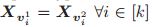 ;
;
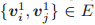 当且仅当
当且仅当
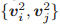 ∈
∈
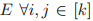 。这种限制对于
。这种限制对于
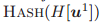 和
和
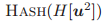 ,以及
,以及
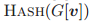 和
和
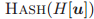 同样成立。
同样成立。
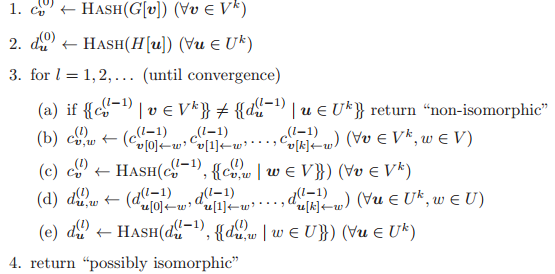
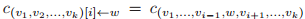 。K-WL 和 K-FWL 仍然存在不足。如果 K-WL 和 K-FWL 输出「非同构」,那么 G 和 H 则不是同构图,但即使 K-WL 和 K-FWL 输出「可能同构」,G 和 H 仍然可能不是同构图。
。K-WL 和 K-FWL 仍然存在不足。如果 K-WL 和 K-FWL 输出「非同构」,那么 G 和 H 则不是同构图,但即使 K-WL 和 K-FWL 输出「可能同构」,G 和 H 仍然可能不是同构图。
-
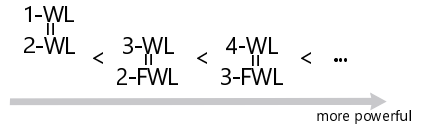
1-WL 与 2-WL 能力相当。换句话说,对于任意一对图,这两种算法的输出相同。 -
对于任意的 k≥2,k-FWL 的能力与 (k+1)-WL 相当。 -
对于任意的 k≥2,(k+1)-WL 一定比 k-WL 能力更强。换句话说,存在一对非同构图(G,H),使得 k-WL 输出「可能同构」,但 (k+1)-WL 输出「非同构」。
-
如果两图都是随机抽取的,那么随着图的尺寸趋向与无限大,1-WL 算法失效的概率趋近于 1。 -
当 k≥2 时,存在一对尺寸为 O(k) 的非同构图(G,H),使得 k-WL 的输出为「可能同构」。 -
对任意一对非同构树 S 和 T,1-WL 算法输出 S 和 T 都是「非同构的」。 -
对于任意的正整数 以及一对有 n 个顶点的 k 正则图 G 和 H,1-WL 算法输出的 G 和 H 是「可能同构」 。
-
在准线性时间内,1-WL 算法可以将图与和它非同构图的区分开来。

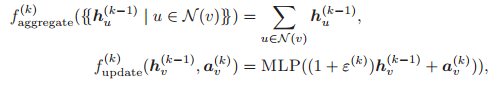
 ,存在 L 层 GIN 的参数使得:若节点的度以一个常数为上界,且节点特征的支撑集的大小有限,那么对于任意的 G 和 H,如果 1-WL 算法在 L 次迭代内输出 G 和 H 是「非同构」的,则由 GIN 计算出的嵌入 h_G 和 h_H 是不同的。
,存在 L 层 GIN 的参数使得:若节点的度以一个常数为上界,且节点特征的支撑集的大小有限,那么对于任意的 G 和 H,如果 1-WL 算法在 L 次迭代内输出 G 和 H 是「非同构」的,则由 GIN 计算出的嵌入 h_G 和 h_H 是不同的。
令 

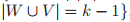
算法步骤如下:
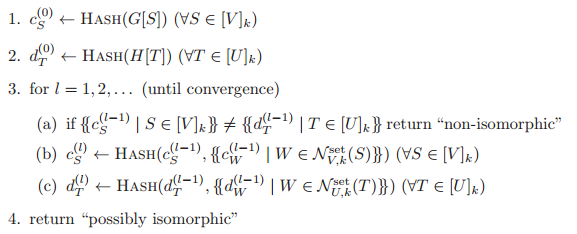
其中, 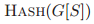
然而,集合 3-WL 算法无法区分图 8 中的 a 和 b,因为 3-WL 算法无法将其区分。需要注意的是,集合 k-WL 算法一定弱于 k-WL 算法。例如,3-WL 可以区分图 9 中的 a 和 b(因为 3-WL 可以检测出 4 联通分量的数目),而集合 3-WL 算法无法做到这一点。
Morris 等人于 2019 年基于集合 k-WL 算法提出了 k-维 GNN(k-GNN)。k-GNN 为每 k 个节点组成的集合赋予一种嵌入。
2)k-维 GNN(k-GNN)
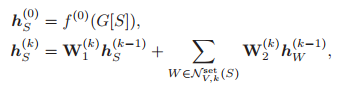
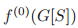 根据 S 划分的子图赋予一个特征向量。k-GNN 可以被看做在拓展图
根据 S 划分的子图赋予一个特征向量。k-GNN 可以被看做在拓展图
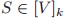 和
和
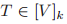 之间的一条边,当且仅当
之间的一条边,当且仅当
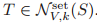 。k-GNN 与集合 k-WL 算法能力相当。
。k-GNN 与集合 k-WL 算法能力相当。
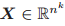 以及一种排列
以及一种排列
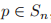 ,我们定义
,我们定义
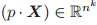 为
为
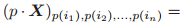
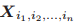 。
。
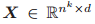 以及一种排列
以及一种排列
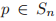 ,我们定义
,我们定义
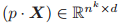 为
为
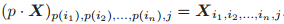 。
。
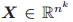 和
和
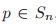 ,
,
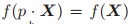 成立,则会函数
成立,则会函数
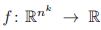 是不变的。若对于任意
是不变的。若对于任意
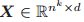 和
和
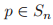 ,
,
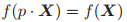 成立,则函数
成立,则函数
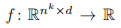 是不变的。
和
,
是不变的。
和
,
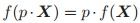 成立,则函数
成立,则函数
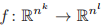 是等变的。若对于任意
和
,
成立,则
是等变的。若对于任意
和
,
成立,则
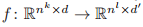 是等变的。
是等变的。
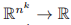 的基的大小为 b(k),
的基的大小为 b(k),
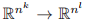 的基的大小为 b(k+l),其中 b(k) 是第 k 个贝尔数(即集合 [k] 的划分的数量)。
的基的大小为 b(k+l),其中 b(k) 是第 k 个贝尔数(即集合 [k] 的划分的数量)。
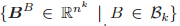 构成了线性不变性变换
构成了线性不变性变换
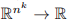 的一组正交基。
的一组正交基。
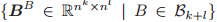 构成了线性等变性变换
构成了线性等变性变换
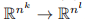 的一组正交基。
的一组正交基。
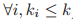 )张量的高阶 GNN ,使得由高阶 GNN 计算得到的嵌入 h_G 和 h_H 是不同的。
)张量的高阶 GNN ,使得由高阶 GNN 计算得到的嵌入 h_G 和 h_H 是不同的。
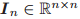 为单位矩阵,
为单位矩阵,
那如何才能设计满足要求的算法呢?该问题的示意图如图 10 所示。
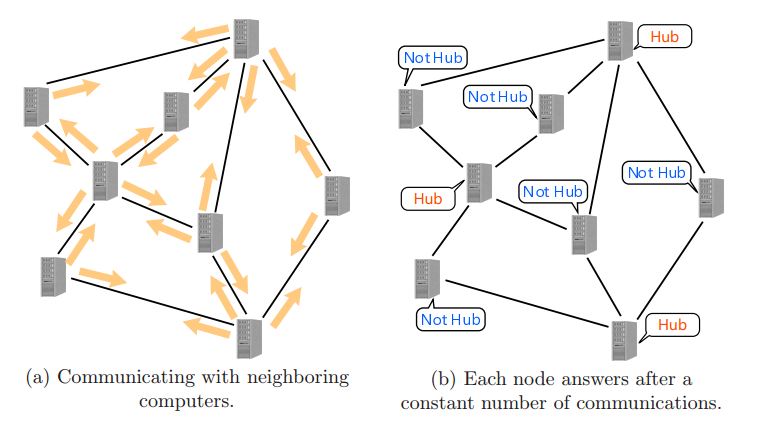
图 10:分布式局部算法示意图。左:与邻居计算机的通信。右:在一定次数的通信后,每个节点的应答。
目前,已经有多种分布式算法的计算模型。在分布式局部算法的计算模型中,标准计算模型使用端口编号策略。在该模型中,每个节点 v 都有 deg(v) 个端口,每条与 v 关联的边都与其中一个端口相连。只有一条边可以连接到一个端口。在每一轮通信中,每个节点同时向每个端口发送一条消息。
通常,不同的消息被发送到不同的端口。然后,每个节点同时接收消息。每个节点都知道相邻节点提交消息的端口号和消息传来的端口号。每个节点都会基于这些消息计算接下来的消息和状态。在一定轮数的通信之后,每个节点都会基于状态和接收到的信息输出一个应答(例如,声明成为一个中心节点)。这种模型被称为局部模型或矢量一致模型(VV_C(1)模型)。
在这里,(1)代表该模型在一定轮数的通信后会停止运行。Hella 等人研究了一些比 VV_C(1)模型能力弱的模型。多重集广播模型(MB(1))没有使用端口编号策略,但是会将消息发送给所有的邻居节点(即广播)。集合广播(SB(1))模型也没有使用端口编号策略,SB(1)模型以集合形式接受消息,而且不能对重复的消息进行计数。Hella 等人说明,VV_C(1)一定能比 MB(1)处理更广泛的问题,MB(1)一定能比 SB(1)处理更广泛的问题。
2、GNN 与局部算法的联系
本节介绍 Sata 等人在论文「Approximation ratios of graph neural networks for combinatorial problems」中指出的 GNN 和分布式局部算法之间的关系。首先,Sata 等人根据分布式局部算法的计算模型对 GNN 模型进行了分类。
1)MB-GNN
MB-GNN 是标准的消息传递 GNN。它对应于 MB(1) 模型。
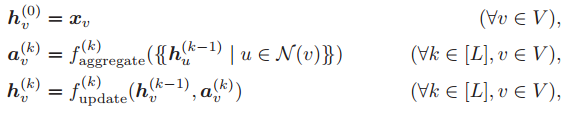
GraphSAGE-mean、GCN、GAT 都是 MB-GNN 的实例。尽管 GAT 的消息是通过注意力加权的,每个节点都会将当前的嵌入广播给所有的邻居节点,每个节点可以计算注意力权值和加权求和结果。因此,GAT 也是 MB-GNN。
2)SB-GNN
SB-GNN 是一类受限的 GNN,它们将嵌入聚合为一个集合。它对应于 SB(1) 模型。
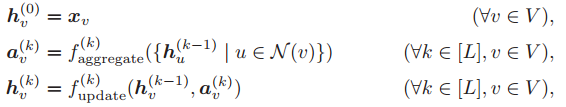
GraphSAGE-pool 是 SB-GNN 的一种实例。
3)VV_C-GNN
VV_C-GNN 使用了一种端口编码策略。VV_C-GNN 首先计算一个任意的端口编号 p,然后通过如下所示的方法计算节点的嵌入。
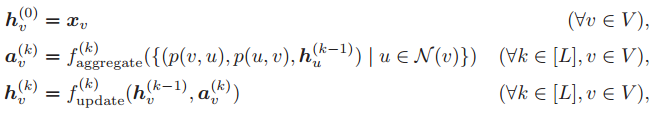
其中 p(v,u) 是 v 的端口编号,边 {v,u} 与这些端口相连。VV_C-GNN 可以向不同的邻居节点传递不同的消息,而 MB-GNN 总是向所有邻居节点传递相同的消息。VV_C-GNN 和 MB-GNN 如图 11 所示。Sato 等人指出,这些 GNN 模型与其相对应的局部算法的计算模型能力相当。
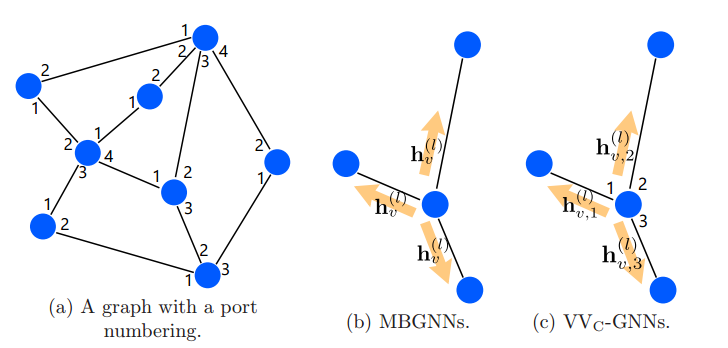
图 11:(a)端口编码的示意图(b)MBGNN 向所有邻居节点传递相同的消息。(c)VV_C-GNN 向邻居节点传递不同的消息。
4)CPN-GNN
CPN-GNN 将邻居节点的嵌入按照端口编码顺序串联起来。
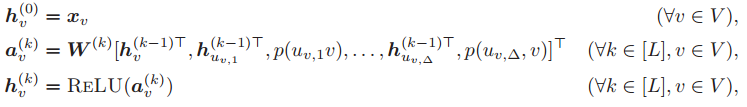
其中,△是输入图的最大度, 是与 v 的第 i 个端口相连的邻居节点,
是科学系的参数。当度数小于 △ 时,CPNGNN 适当地进行补零填充,它是最强大的 VV_C-GNN。
在组合优化问题中,若搜索出的解更接近最优解(即近似比更小),则算法性能越好。为了探究 CPNGNN 在组合优化问题中的性能,可以计算通过 CPNGNN 算法搜索到的解的近似比。在论文「Approximation ratios of graph neural networks for combinatorial problems」中,Sato 等人考虑了以下三种问题:
1)最小顶点覆盖问题
输入:图 G=(V,E)
输出:节点集合 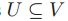
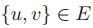
2)最小支撑集问题
输入:图 G=(V,E)
输出:节点集合 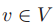
3)最大匹配问题
输入:图 G=(V,E)
输出:边的集合 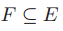
Sato 等人注意到,添加度特征以外的特征可以减小上述三个问题的近似比。
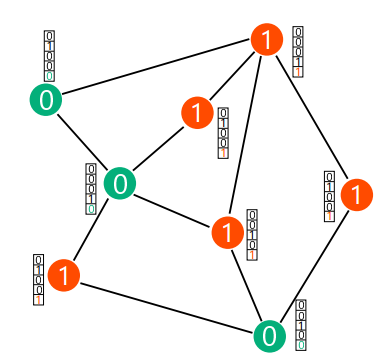
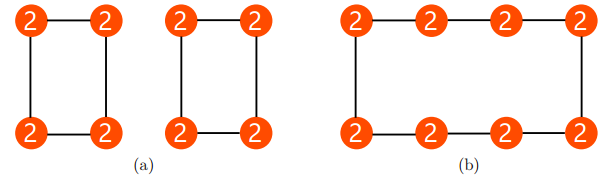
图 12:一种简单的 2-着色问题。每个绿色(0)节点与最少一个红色节点相连,每个红色(1)节点与至少一个绿色节点相连。
具体而言,他们考虑了一个简单的 2-着色问题。一个 2-着色问题是为图中的节点赋予 2 种颜色,使得图中每一个几点至少有一个颜色不同的邻居。图 12 是这种简单的 2-着色问题的示意图。2-着色问题可以在线性时间内通过广度优先搜索(BFS)算法完成计算。
Sato 等人指出,将这种简单的 2 着色问题增加到节点特征中可以使 GNN 获取更多关于输入图的信息,并且得到更好的近似比。
3、随机特征增强 GNN
本章介绍的是,将随机特征添加到每个节点中,可以使 GNN 区分更多类别的图,并且建模出更高效的算法。
Sata 等人提出了带有随机特征的 GIN(rGIN)。rGIN 在每次程序被调用时赋予一个随机特征。具体而言,rGIN 获取一个图 G=(V,E,X)作为输入,从一个离散分布 μ 中为每个节点以独立同分布的方式取样得到随机特征 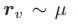
需要注意的是,尽管 rGIN 在训练和测试时赋予不同的随机特征,但是 rGIN 也可以在测试时泛化到模型没有见过的图上。
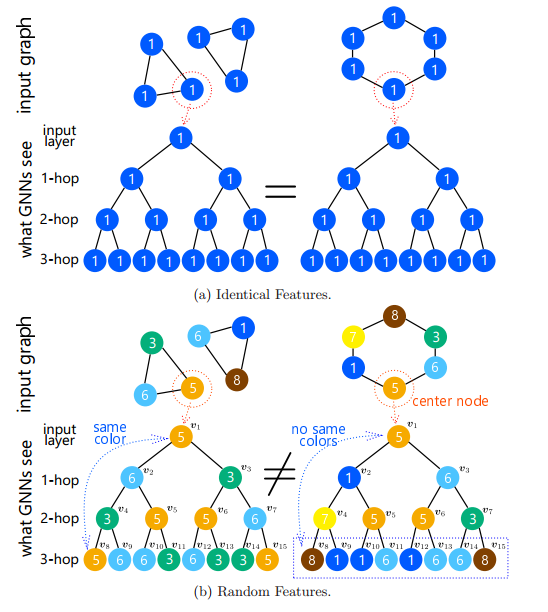
图 13:(a)当节点特征向同时,消息传递 GNN 无法区分两个三角形和六边形。(b)当具有随机节点特征时,消息传递 GNN 可以区分两个三角形和六边形。
表 二:最小支撑集问题(MDS)和最大匹配问题(MM)的近似比的总结

表二总结了最小支撑集问题(MDS)和最大匹配问题(MM)的近似比。其中 *代表这些近似比达到了下界。△代表最大度,H(k) 代表第 k 个调和数, 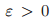
正如第三章和第四章所提到的,GNN 与 WL 算法和分布式局部算法息息相关。本章将根据 GNN、WL算法、分布式局部算法之间的关系总结 GNN 的表达能力。我们将它们的关系称作「XS 一致性」(根据 Xu 等人和 Sato 等人的名字命名)。
Xu 等人和 Sato 等人的研究结果给出了 GNN、WL 算法以及分布式局部算法的要素之间的一致性。表三总结了这种一致性。
表三:XS 一致性给出了 GNN、WL 算法,以及分布式局部算法的要素之间的具体联系。

例如,分布式算法领域也研究了求解组合优化问题所需的通信轮数。Astrand 等人指出, 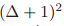
此外,WL 算法和分布式局部算法在很多领域内都有联系。例如,k-WL 算法与带有计数量词的一阶逻辑、组合数学中的跳卵石游戏、线性规划、Sherali-Adams 松弛都有联系(这些问题也可以通过组合优化方式求解)。分布式局部算法与模态逻辑、常数时间算法都有关。具体而言:
对于任意的 k≥2,存在一个带有计数量词的 k 个变量的一阶逻辑语句
,使得
且
当且仅当 k-WL 算法输出 G 和 H 是「非同构」的。
在游戏
中,玩家 2 在 G 和 H 上有一个获胜策略,当且仅当 k-WL 算法输出 G 和 H是「可能同构」的。
令 A 和 B 是 G 和 H 的邻接矩阵。存在双随机实值矩阵 X 使得 AX=XB,当且仅当 1-WL 算法输出 G 和 H 是「可能同构」的。
令 A 和 B 是 G 和 H 的邻接矩阵。如果 (k+2)-WL 算法输出 G 和 H 是「可能同构」的,则对于任意的 k≥2,存在 AX=XB 的秩-k Sherali-Adams 松弛的解,使得 X 是双随机的。
令 A 和 B 是 G 和 H 的邻接矩阵。只有 (k+1)-WL 算法输出 G 和 H 是「可能同构」的,则对于任意的 k≥2,才存在 AX=XB 的秩-k Sherali-Adams 松弛的解,使得 X 是双随机的。
在相应的Kripke模型上,VV_C(1) 模型可以识别梯度多模态逻辑的逻辑公式,而在VV_C(1)模型上,梯度多模态逻辑可以模拟任意算法。
一个分布式局部算法可以被转化为一个常量时间算法。
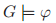
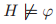
得益于 XS 一致性,我们可以使用该领域的结论推导出许多 GNN 的理论特性。例如,Barcelo 等人利用 WL 算法和一阶逻辑之间的关系构建了更加强大的 GNN。
本文中,我们介绍了图神经网络的表达能力。换而言之,我们介绍了消息传递 GNN 的能力最多与一维 WL 算法相当,以及如何将 GNN 推广到 k 维 WL 算法上。
接着,我们介绍了 GNN 和分布式算法之间的联系,指出了 GNN 在 GNN 可以计算的组合优化算法近似比方面的局限性。
不仅如此,我们还指出了将随机特征添加到每个节点中会显著提升近似比。
最后,我们将 GNN、WL 算法,以及分布式局部算法之间的关系总结为「XS 一致性」。




