通过基于情感方面的分析来理解用户生成的内容

本文为 AI 研习社编译的技术博客,原标题 :
Using Aspect-Based Sentiment Analysis to Understand User-Generated Content
作者 | Steve Mutuvi
翻译 | 清都江水郎、ybNero 编辑 | 王立鱼
原文链接:
https://heartbeat.fritz.ai/using-aspect-based-sentiment-analysis-to-understand-user-generated-content-2cfd5d3e25bb
注:本文的相关链接请访问文末【阅读原文】

简介
用户生成的内容(UGC)在近年来有了明显地增长。这些内容大多是文本的,主要通过在线论坛和社交媒体平台产生,同时也包含着用户对公司/组织或者热点事件的观点评论。
商业通过提供商品交易或者服务而存在,也就是说要想获得成功,与顾客的交流和关系维护便是关键因素了。分析顾客的反馈——不管是顾客的评论或是抱怨——这些分享在网上或社交媒体平台的反馈会给予商家优化顾客服务的重要观点。事实上,有大量的统计表明这类通过用户生成的内容的分析是品牌战略的重要部分。
尽管有这些公认的好处,商家要去把这些大量的无结构数据解析和重组成更易于理解和行动的见解仍是一项巨大的挑战。这些离散的无结构的自然语言文本数据尤其难以人工分析。然而,基于机器学习的观点挖掘技术拥有自动抽取观点和它们对应情感极性的巨大潜能。这种方法被称为方面级别的情感分析(ABSA)
规范地说,情感分析或观点挖掘是通过计算来研究人们的观点、情感、评价、态度、心情和情绪。方面级别的情感分析包含了2个子任务:第一,从给定的文本数据中检测出观点或方面的术语;第二,找出检测出的方面的术语所匹配的情感。
在这篇文章里,我们将展示搭建一个自然语言处理路线,从大量的顾客评论中抽取有意义的见解。这是一次从给定主题的用户生成文本中,理解观点,并将这个过程自动化的尝试。
数据集
我们在这里使用 2016年SemEval年度大赛提供的关于餐厅评论的数据集。这项大赛致力于从顾客评论中提取特定的词组和计算相关的情感值来建立他们的模型。
我们首先导入一些依赖库:
# NLTKimport nltkfrom nltk.corpus import stopwordsfrom nltk.stem import SnowballStemmernltk.download('stopwords')#Spacyimport spacynlp = spacy.load('en')# Otherimport reimport jsonimport stringimport numpy as npimport pandas as pdimport warningswarnings.filterwarnings('ignore')#Kerasfrom keras.models import load_modelfrom keras.models import Sequentialfrom keras.layers import Dense, Activation
这个训练集使用 pandas 的 read_csv() 函数来载入数据,我们可以使用 head() 函数来查看训练集的前五条数据:
#load dataimport pandas as pdreviews_train = pd.read_csv("Training_Set_Restaurant_Cleaned.csv").astype(str)#show first 5 recordsreviews_train.head()
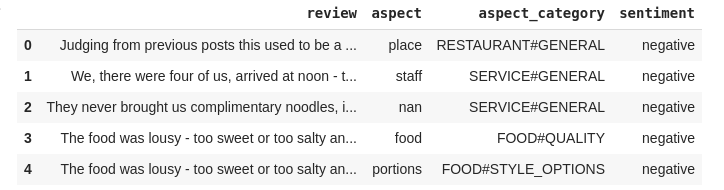
数据集中的前五条数据
表格中的 aspect_category 和 sentiment 属性分别代表了该评论的类别以及其情感倾向。我们可以使用下面的代码来计算全部的评论类别:
# reviews_train.columnsprint(reviews_train.groupby('aspect_category').size().sort_values(ascending=False))#how many categoriesprint("number of categories",reviews_train.aspect_category.nunique())
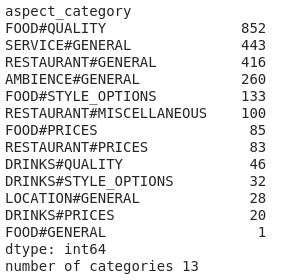
评论总类别
在我们的数据中,我们共有13种评论类别。
模型训练
通过Keras Library,我们将为方面类别和情感分类搭建并训练神经网络。Keras是一个能迅速部署实验的高阶、对用户友好、模块化并且易于拓展的神经网络接口。Keras是由Francois Chollet开发并维护的,可以运行在CPU或GPU上。
定义神经网络架构
让我们开始定义方面分类器的架构:
absa_model = Sequential()absa_model.add(Dense(512, input_shape=(6000,), activation='relu'))absa_model.add((Dense(256, activation='relu')))absa_model.add((Dense(128, activation='relu')))absa_model.add(Dense(13, activation='softmax'))#compile modelabsa_model.compile(loss='categorical_crossentropy', optimizer='Adam', metrics=['accuracy'])
我们将使用一个三层的全连接网络结构。我们首先创建一个Sequencial的对象然后使用add方法来添加模型的层。Dense类是用来定义一个全连接层,其中,网络中的每个神经元都会接收从前一层的神经元传来的全部输入。
输入的大小被设定为6000,这也就是使用词嵌入所创建的词汇量的最大值,同时还将relu设定为该模型的非线性的激活函数。非线性函数将数据转变成可以被高效分类的节点。输出层包含了13个神经元,每个对应着一个类别。softmax激活函数在我们的模型中被用于返回每个类别的概率值——目标类别会有最高的概率。
一旦我们的架构被确定,我们需要对学习过程的参数进行设置:确定优化器,损失函数和评估指标。“学习”简单地解释为找出一组模型参数的组合,最后针对给定的训练数据样本和它们对应的目标,把损失函数最小化。由于手中的问题是多分类问题,损失函数就被确定了是分类交叉熵损失。
词向量表示
为了将评论进行编码,我们使用一种叫词袋模型(BoW)的词嵌入技巧。在这种方法中,我们对一条评论使用分词(tokenized),然后得出每一个分词(token)的频率:
vocab_size = 6000 # We set a maximum size for the vocabularytokenizer = Tokenizer(num_words=vocab_size)tokenizer.fit_on_texts(reviews_train.review)reviews_tokenized = pd.DataFrame(tokenizer.texts_to_matrix(reviews_train.review))
同时我们也需要把方面目录的列名也做编码:
label_encoder = LabelEncoder()integer_category = label_encoder.fit_transform(reviews_train.aspect_category)encoded_y = to_categorical(integer_category)
以上的三个步骤会在情感分类器中不断重复。然而,分类器的输出层被初始化为数值3,由于这其中有3中情感——正面的(positive)、中性的(neutral)和负面的(negative)。
#model architecturesentiment_model = Sequential()sentiment_model.add(Dense(512, input_shape=(6000,), activation='relu'))sentiment_model.add((Dense(256, activation='relu')))sentiment_model.add((Dense(128, activation='relu')))sentiment_model.add(Dense(3, activation='softmax'))#compile modelsentiment_model.compile(loss='categorical_crossentropy', optimizer='Adam', metrics=['accuracy'])#create a word embedding of reviews datavocab_size = 6000 # We set a maximum size for the vocabularytokenizer = Tokenizer(num_words=vocab_size)tokenizer.fit_on_texts(reviews_train.review)reviews_tokenized = pd.DataFrame(tokenizer.texts_to_matrix(reviews_train.review))#encode the label variablelabel_encoder = LabelEncoder()integer_sentiment = label_encoder.fit_transform(reviews_train.sentiment)encoded_y = to_categorical(integer_sentiment)
训练过程
以上搭建好的模型将开始进行训练。首先,我们会在模型上使用`fit()`方法,其中的参数设置为训练数据(reviews_tokenized)、目标数据(encoded_y)、epochs数量和verbose参数。Verbose能帮助我们观察每个epoch下的训练过程。
#fit aspect classifierabsa_model.fit(reviews_tokenized, dummy_category, epochs=100, verbose=1)#fit sentiment classifiersentiment_model.fit(reviews_tokenized, dummy_category, epochs=100, verbose=1)
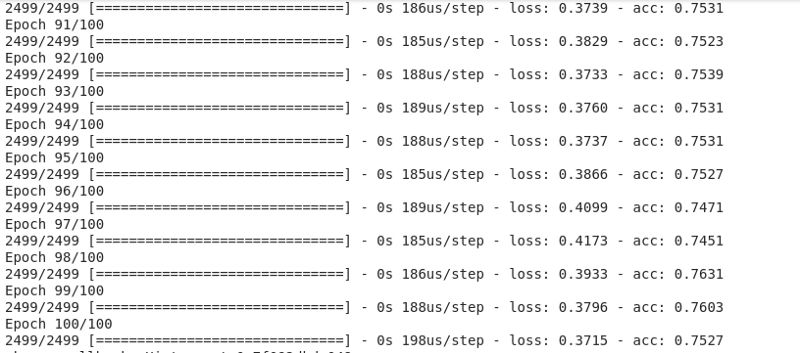
训练过程
模型的精确度可以通过超参数的调优来进行提高。
最后,如下图所示,我们用几条评论来测试我们的模型。这些评论还做了一些微小的预处理,比如把它们全部都小写化:
test_reviews = ["Good, fast service.","The hostess was very pleasant.","The bread was stale, the salad was overpriced and empty.","The food we ordered was excellent, although I wouldn't say the margaritas were anything to write home about.","This place has totally weird decor, stairs going up with mirrored walls - I am surprised how no one yet broke their head or fall off the stairs"]# Aspect preprocessingtest_reviews = [review.lower() for review in test_reviews]test_aspect_terms = []for review in nlp.pipe(test_reviews):chunks = [(chunk.root.text) for chunk in review.noun_chunks if chunk.root.pos_ == 'NOUN']test_aspect_terms.append(' '.join(chunks))test_aspect_terms = pd.DataFrame(tokenizer.texts_to_matrix(test_aspect_terms))# Sentiment preprocessingtest_sentiment_terms = []for review in nlp.pipe(test_reviews):if review.is_parsed:test_sentiment_terms.append(' '.join([token.lemma_ for token in review if (not token.is_stop and not token.is_punct and (token.pos_ == "ADJ" or token.pos_ == "VERB"))]))else:test_sentiment_terms.append('')test_sentiment_terms = pd.DataFrame(tokenizer.texts_to_matrix(test_sentiment_terms))# Models outputtest_aspect_categories = label_encoder.inverse_transform(absa_model.predict_classes(test_aspect_terms))test_sentiment = label_encoder_2.inverse_transform(sentiment_model.predict_classes(test_sentiment_terms))for i in range(5):print("Review " + str(i+1) + " is expressing a " + test_sentiment[i] + " opinion about " + test_aspect_categories[i])

测试结果
这个模型在对我们的测试评论中表现还不错。
结论
方面级别的情感分析(ABSA)可以帮助商业变得以顾客为重心并把他们的顾客时时牵挂在心上。这即是倾听顾客,了解顾客的发声,分析顾客的反馈然后研究更多的顾客经历和他们对产品或服务的期望。
当计算方法的使用在顾客意见挖掘上被证明是有前景的同时,更该做的便是提高这些模型的表现了。一个可信的提高模型表现的方法是使用更先进词表示技巧,尤其是与上下文语境有关的词嵌入。
与上下文语境有关的词嵌入表示起源于预训练的双向语言模型(biLMs)在近期的一系列NLP任务中取得的当前最高水平的显著进步。在这些上下文词嵌入技巧中最受关注的便是谷歌的BERT模型了。
上下文语境表示是以每个单词来表示句子中其他单词作为特征。因此,这个分类模型在从用户生成内容学习的丰富语境表达后,表现将会有显著的进步。
想要继续查看该篇文章相关链接和参考文献?
点击底部【阅读原文】即可访问:
https://ai.yanxishe.com/page/TextTranslation/1742
滑动查看更多内容



<< 滑动查看更多栏目 >>





