肖仰华 | 基于知识图谱的用户理解
本文转载自公众号知识工场。
本文整理自肖仰华教授在三星电子中国研究院做的报告,题目为《Understanding users with knowldge graphs》。

今天,很高兴有这个机会来这里与大家交流。
前面两位老师把基于社会影响力的传播和推荐,以及跨领域的推荐讲解的深入细致,我想大家可能也会体会到,我们目前的很多方法和手段越来越接近一个所谓的“天花板”。现有的方法,包括机器学习和深度学习的方法,某种程度上都是在吃大数据的红利,机器学习的效果,模型的效果本质上是由大数据来喂养,我们灌进去的数据越多,模型的效果就越好,尤其是深度学习,随着它的层次结构越来越深以后,它对样本数据的规模和质量的要求也会更高,那么当我们把大数据的红利吃完之后,我们该怎么办呢?
事实上,学术界和工业界在这里年越来越多的意识到这个问题的严重性,就是当我们把大数据红利吃完之后,我们的模型效果应该如何进一步的提升?
对于这个问题,从我这个研究方向给出的答案是什么呢?就是知识。知识的重要性将会越来越突出,我相信很多模型,推荐模型,机器学习算法都将会从数据驱动走向知识引导,越来越多的模型和算法将从基于行为的模型走向基于语义的模型。
今天,我会更多的谈论如何摆脱行为数据的影响来做用户画像和推荐。因为很多场景下是没有行为数据的,在一些极端的情况下,根本没有用户信息,那么这个时候我们怎么推荐?再比如说在互联网搜索用户画像,高频用户和VIP用户都可以解决的很好,那是因为它数据量足够,但是关键的问题是,很多长尾用户压根没有什么数据,那这个时候我们的模型怎么办?这时候我们就要借鉴语义和背景知识来给我们力量。这也是为什么我想跟大家分享利用知识图谱来理解用户,给用户画像,来解决推荐的问题的原因。
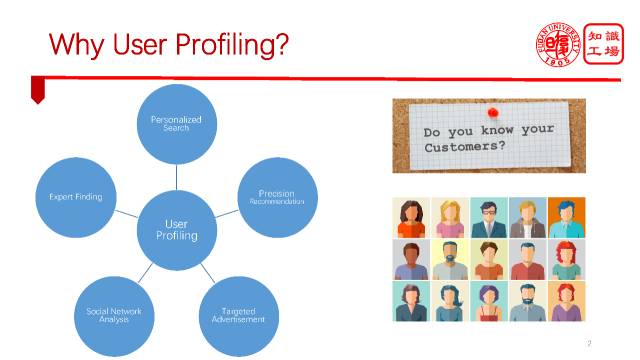
为什么要做用户画像?因为企业要了解他们的用户,像三星这么大的一个企业,有着宽广的产品线,有着来自全世界的用户,企业希望产品服务是个性化的,那么这个个性化的前提就是用户画像。
在整个互联网时代其实催生了很多基于用户画像的应用。比如搜索,百度搜索是通用搜索,因不同的人而展现不同的结果。再比如推荐,不同的人看到不同的推荐结果。广告投放,社交网络分析,甚至在企业内部找专家等等,都需要去理解用户,那么就需要一个非常有效的用户画像。

那么在各种各样的画像当中,最流行的一种方法是基于标签的。在很多实际应用中,大家都在广泛的应用这一类基于标签的画像方法。基于画像的标签方法其实很简单,就是给用户打一组标签,每个标签给一个权重,权重代表了用户在这个方面兴趣的强烈程度,如图我们给出了一个豆瓣用户的标签云,也给出了一个微博用户的标签云。不同平台的语言风格,语言体系是不完全一样的,豆瓣的语言倾向于书面化,而微博的语言倾向于碎片化,口语化。
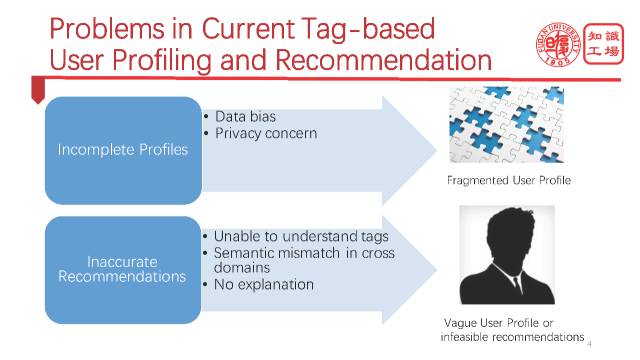
时至今日,我们已经有很多方法来帮助解决画像和推荐的问题,那为什么今天还要来谈论这个话题呢?是因为这些方法里面还存在一些问题,问题集中在两个方面。
第一个方面就是用户画像某种程度上还是不完整的。 导致这个问题可能有两个原因,第一个原因就是任何画像的来源数据都是有一定偏差的,一般描述的都是用户画像的某一方面,很难有一个非常完整的画像。还有一个非常重要的原因就是隐私,后面我们会有case study,大家就会发现在微博上其实还是有很多人不愿谈及自己的,比如说宗教信仰,政治观念等等,但是很多时候可能了解用户不愿谈及的这个方面的内容对于我们做产品,做服务又是非常重要的。基于这两个原因,我们对用户的理解就是一个碎片式的,很难召回完整的目标客户。
用户画像第二个关键的问题就是不正确性,也就是说我们对用户画像的理解很多时候是错误的,这导致就会出现错误的推荐。导致不正确性的原因有很多,第一个就是机器还无法理解这些标签,也就无法做出精准推荐。第二个原因就是在跨领域场景下,由于缺失用户的商品,也就是缺失推荐对象之间的历史交互信息,使得冷启动变成一个非常突出的问题,没有历史信息,一切基于这个的推荐就会失效。这个时候我们可能会采取一些基于语义的办法,但是基于语义的办法前提是要有精准的语义匹配,这就需要一个庞大精准的知识库来作为背景知识来支持。第三个原因就是没有针对推荐给出解释。这个是非常重要的,当且仅当你给出一个非常合理的解释的时候,用户才会很好的接受推荐。那如何给出解释呢?以前,解释在人脑里面,现在我们可以利用大规模知识库来产生解释,从而实现能够给出带解释的推荐给用户。

我们如何利用知识图谱,把它作为background knowledge来理解用户标签,进而理解标签背后的用户呢?

理解用户是我们的终极目标,但是我们要先理解由于用户的行为而产生的标签,这就非常难了,为什么呢?标签可以认为是自然语言的一部分,是一个简单形式,比如可以给我打标签,“IT教师”、“复旦大学”,“知识图谱”,那机器如何理解这些标签呢?目前机器还不能有效的准确的理解人类的自然语言,因为我们的自然语言很多时候是有歧义的,需要通过上下文才能理解的。很多时候语言的表达式是隐含的,比如我们中国人说两个人是爱人关系的时候,不会直接说他们俩是伴侣关系,而会说他们共进晚餐或者看电影之类的,很少直接去谈及这块,所以很多关系是隐含的。语言还有一个重要的难点,就是它的多样性,同一个意思,可以有很多种说法。
那么再进一步分析为什么语言理解这么困难?从根本上来讲,是因为语言理解是建立在人对世界认知的基础之上。你为什么能够理解语言?是因为你已经对这个世界,对在你身边发生的事情有了充分的认知。机器现在还达不到认知世界的能力,机器的大脑里还缺乏非常重要的背景知识,比如这里有几个卡通人物,大家一看就理解了,那是因为你已经有这个背景知识在背后,那么机器想要理解语言,理解标签,就需要有海量的背景知识去支撑它认知这些概念。

机器需要怎样的背景知识呢?第一个是要有足够大的规模,必须覆盖足够多的实体,足够多的概念。第二个是语义要足够丰富,当说到各种各样的关系的时候,机器必须都能够理解。第三个就是质量足够精良。第四个就是结构必须足够友好。
大家都知道机器最喜欢的是有结构的数据,最怕的是纯文本,无结构的数据,我们希望知识库是以一种机器友好的结构形式来组织的。也有人发出疑问,知识图谱跟传统的本体语义网有什么差别呢?先来说本体,以前在特定领域尤其是医疗领域积累了大量的本体,但是大部分都是人工构建的,规模十分有限,而且当要把传统知识工程从一个领域转移到另一个领域的时候,就会发现代价极大,因为人工构建的成本极为高昂。再来看看以前的语义网络,它往往是集中在单一的语义关系上,而不像知识图谱,涵盖了上千数万种语义关系。再比如说文本,文本结构不友好。这么一看大家就知道传统的知识表示都不行。
这样,知识图谱成为了机器语言认知所需要的知识表示,所谓知识图谱,本质上是一种语义网络,它表达了各种各样实体概念及其之间的语义关系。与之前的知识表示作比较,会发现知识图谱有非常多的优势:第一,它规模巨大,像google的知识图谱现在已经到了几百亿的实体规模。第二,它的语义关系也很丰富,比如说我们自己的CN-DBpedia里涵盖了成千上万种语义关系。第三,知识图谱通常是用RDF来表示的,对于机器来讲,结构足够友好。第四,知识图谱是通过大数据众包的手段来校验它的质量,也就是靠人来校验质量,所以有着比较好的质量。
所以利用知识图谱来帮助机器理解标签,最终理解用户是有可能的。
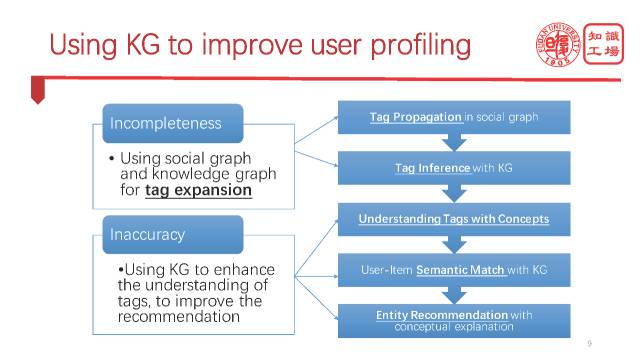
怎样利用知识图谱来解决刚才提到的不完整和不正确的两个问题呢?
我们利用知识图谱来做标签扩展,标签推断,来提高机器对标签的理解水平,实现基于标签的,基于知识图谱的精准推荐。
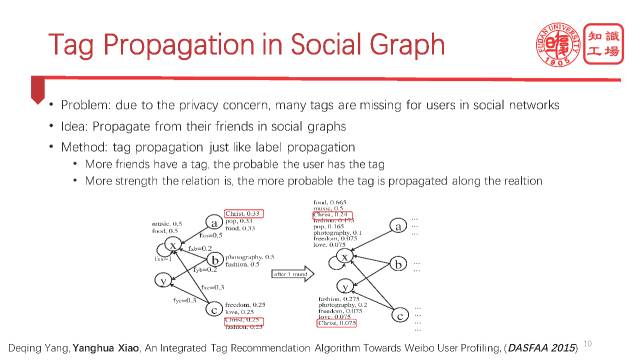
我们把social graph当做一个knowledge graph,只不过social graph是人与人之间的关系,而knowledge graph是更为一般的语义关系,所以某种程度上可以认为social graph是knowledge graph的一个typical case。
出于隐私的考虑,很多用户不愿意给自己打标签,那怎么办呢?我们可以利用social network上的一些关系来推断一些不具备标签或者具备很少标签的用户的一些标签。
如果用户的大部分朋友都有这个标签,那么我觉得用户也可以拥有这个标签。如果用户与朋友关系非常紧密,那么朋友的标签传播过来的可能性就更大。
我们就是基于这两条准则来进行标签传播的。

这里有一个实际案例,我们在微博上做实验,结果显示这种传播方法很有效,尤其是在宗教信仰,政治观念,教育等方面的推断准确率能高达95%。
比如在这个user case,基于label propagation这么一个思路,用LTPA算法,user A的real tags是music和fashion,但是通过标签传播,你会发现实际上他是一个基督教徒,因为传播出来很多类似Christian,Bible,faith等等这样的标签,那我们看他的微博发现他确实就是一个基督教徒。
这就是tag propagation,通过传播来找到用户的缺失标签。

关于标签的不正确性,我们做一个tag inference。这里有两个真实的案例,第一个案例就是季建业受审的案子,我们要给这个新闻打合理的标签,这个标签难在什么地方呢?大家都知道季建业是南京市长,在山东烟台受审,结果“烟台”出现的频率显著高于“南京”,但是这个新闻按道理应该是“南京”打的这个标签权重高于“烟台”,那么怎样识别出更准确的标签呢?怎么把“烟台”这个标签弱化,而把“南京”这个标签给强调出来?
第二个例子就是枪决案件,打的标签是“朝鲜”,“崔英建”,“枪决”这三个标签,虽然通篇没有提到平壤,但这件事肯定跟平壤是有关系的。
实际上这样的例子很多,一篇讲姚明的文章,即便通篇没有讲篮球,但肯定跟篮球有关系,打上“篮球”的标签准没错。
我想表达什么意思呢?就是有很多应该打的标签,由于这个事实太显然,以至于文本里没有提,而我们现在所有的办法都基于一个假设,就是文本里提到才能打上标签,那么我们有没有办法推断出这些不存在与文本中的标签呢?
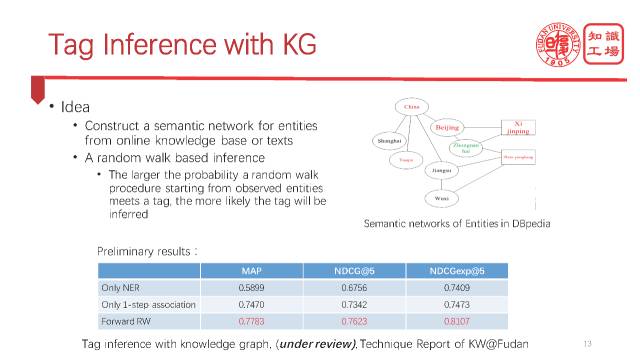
实际上我们用知识图谱是可以做到的。我们建构一个语义网络,利用CN-DBpedia把新闻里提到的候选实体之间的语义关联建立起来。我们的算法怎么实现呢?其实也很简单,我们可以用一些随机游走的办法,可以从新闻中观察到的这个实体去随机游走,看它们能都倾向于走到哪些未被观察到的实体,而这些实体就是很有可能作为标签出现的。实验结果证实这个办法的确能够找到更多人工判断下来的更为准确的标签。

再进一步我们想通过知识图谱让机器准确理解这些标签。
人类是在合适的概念层次来理解标签的。比如说人类看这么一组标签“China,Japan,India,Korea”,很快就会理解,讲的是Asian country。基于概念级别去理解这些标签对于后面做精准推荐是十分重要的。那现在问题来了,我们怎么让机器去理解这些标签?怎么为标签产生一个合适的概念呢?
首先我们用一个knowledge base叫probase,它包含了大量的实体,也可以认为是标签及其概念。比如“apple”,它可以是一个company,也可以是一个fruit,company和fruit都是“apple”的概念。
我们利用probase去产生概念标签的时候,要解决两个问题,第一个问题就是我们希望找到的这个概念的覆盖率高,第二问题就是概念的信息尽可能详细。比如第一个例子“China,Japan,India,Korea”,可以用“Asian country”这个标签,也可以用“country”这个标签,但显然“Asian country”比较好。
我们要处理的最核心的问题就是coverage和minimality这么一对矛盾。我们采用的是一个非常通用的模型,是基于信息论的,也就是Minimal Description Length最小描述长度的方法。

我们把刚才那个概念标签选择问题建模成找一堆概念来encoding我们看到的tag这么一个问题。那么很显然,刚才的两个标准,就可以体现在这里的两个目标里。第一部分,就是我们要用尽可能少的概念去cover这些实例,那么也就是说概念自身的编码代价要尽可能小。第二个利用这种概念去encoding知识图谱的tag的代价尽可能小,也就是基于知识图谱的条件的length尽可能小。就有这么一个优化的问题。当然了,这是一个很general的model。在这个general的model下面,我们还要处理一些很实际的情况。

我们这里很多都是很实际的案例,来自很多实际的data的tag。比如在实际的用户的tag或者image或者document往往会有噪音。比如这个tag里面有很多“apple,banana,breakfast,dinner,pork,beef”,突然出现一个“bullet”,那这个很可能就是个噪音,所以这个模型要能够噪音容忍,这是第一个问题。
第二个问题就是说有很多像“population,president,location”,实际上最好的概念是“country”。但你要注意“country”跟“population,president,location”实际上不是严格的isA关系。population人口,president总统都是“country”的一个属性,而不是isA关系。像刚才“China”和“Asian Country”那是isA关系。但是population只能说是Country的一个attribute。所以我们在建模的时候不仅仅要考虑isA关系,还需要能够应用这里的attribute关系,这是在模型方面的两个改进。

最终的实际效果大家看,非常有意思。我们可以看到,基于MDL的方法是可以非常有效的解释这个标签的。我们人为做了一个实验,把来自三组不同概念的实体混在一起,看看我们的模型能不能找到这三组实体的三个正确的概念标签。图中Table 3第一行就真的找到相应来源的概念。
再看看Table 4,带属性和不带属性是可以产生不一样的概念的。比如“bride,groom,dress,celebration”在带属性的模型中产生的是“wedding”这个概念标签,但是在不带属性的模型中产生的是“tradition”这个概念标签。
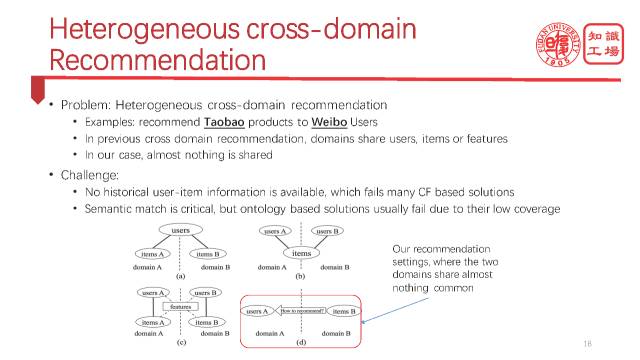
我们怎样利用这个知识图谱来做一些精准推荐呢?在推荐中最难的一类是跨领域推荐,不同的领域要不共有user,要不共有item,要不共有feature,可是也有非常情况,比如说给微博用户推荐淘宝商品,当然可以用传统的ontology的办法,但是ontology的覆盖率比较低,所以我们要用知识图谱。

如果一个微博用户经常谈论各种旅游名胜,我们能不能把淘宝上的登山杖,旅游鞋推荐给他呢?要知道旅游名胜和登山杖,旅游鞋的描述是风马牛不相及的,是没有办法直接匹配的,那就需要一些间接匹配的方式,通过什么呢?就是通过背景知识图谱来做一个桥接,也就是CN-DBpedia。
“九寨沟”会在知识图谱在里面,知识图谱 里可能有一些相关实体,比如“旅游”,“旅游”和“九寨沟”直接相关,“旅游”与“登山杖”“旅游鞋”也相关,就可以用这种中间实体和概念来桥接两个完全不相关的物品和用户。
实际上我们利用knowledge base构建了很多concept vector来进行描述,分别描述user和item,然后来实现匹配,最终的效果也是相当不错的。

事实证明,在knowledge graph和knowledge base的支持下,的确是可以把两个看上去语言描述完全不一样的东西进行匹配的。

最后我们来聊聊推荐解释。
举个例子,假如说用户在亚马逊上搜索了“iPhone 7”,又搜了“华为 9”,那么亚马逊应该给用户推荐什么呢?如果亚马逊给用户推荐“小米 Note”,那好像就不太对,比较好的就是推荐类似“三星 S7”。为什么用户搜了“iPhone 7”和“华为 9”就要推荐“三星S7”呢?因为它们共有相同的概念,它们可以归到相同的品类,它们都是昂贵的、高端的smart phone 。
那我们能不能根据用户搜索的实体给他推荐其他的商品,并给出解释呢?

这里我们用概念作为解释,比如说,如果我说三个国家,中国,印度,巴西,然后让你再说一个国家,你很有可能就会说俄罗斯,因为它们都是金砖四国,都是新兴市场,都是发展中国家,它们共有很多概念。 所以概念是一个非常好的解释。

那么概念哪里来呢?概念又是来自于刚才提到的一个叫probase的知识库。那么为了做这个事情,我们提出好几个model。比如在这个model 2里面,我要推荐一个实体e,那么实体e跟刚才已经观察到的一堆实体q组合到一起之后,应该能够非常好的保持住原来那堆实体的概念分布。我们用概念分布来表示实体的语义,比如说刚才的中国,巴西,印度,他们的概念分布就是发展中国家,新兴市场,金砖四国这样一些概念。概念实际上是实体的一个非常好的语义表示。那我用概念分布来做它的语义表示。那么很显然,我要加进来的这个实体e跟q组合到一起之后,他们的概念分布要尽可能保持住已经观察到的这组实体的概念分布。就有这么一个model,我们需要把它的交叉熵给最小化。这就是我们这个model 2。下面就是求解,那就非常简单了。
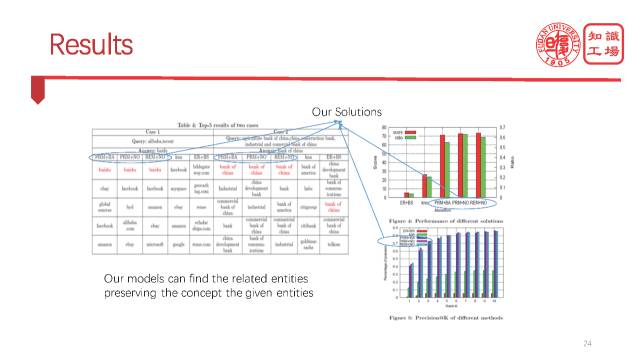
那最终的效果也就是很有意思,如果用户先搜索了“阿里巴巴”,“腾讯”,我们的模型就会推荐“百度”,而其他的模型会推荐其他的一些大公司。再如果用户搜索了中国的三大国有银行,我们的模型会推荐第四大国有银行,而其他的模型可能会推荐一些不准确的东西。
以上给大家讲的就是我们基于知识图谱来做推荐的内容。
(以上是肖仰华教授报告的主要内容,以下关于知识工场实验室介绍以及实验室所做工作的内容,这里就不做详细描述。)





关注“知识工场”微信公众号,回复“20170926”获取下载链接。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。




