DeepMind发Nature子刊:通过元强化学习重新理解多巴胺
Root 编译整理
量子位 出品 | 公众号 QbitAI
比起人类,深度学习算法已经在很多任务上的表现更优秀。但它们的学习效率很低。
一个电子游戏,人类玩一个下午大概就会了,而算法得花上百个小时。

DeepMind认为,这可能是人类的元学习能力占了优势。
据昨天DeepMind在Nature Neuroscience刊出的新论文Prefrontal cortex as a meta-reinforcement learning system指出,人类之所以能非常快地掌握新事物,原因可能是能从以往的经历中提取出规律,这种能力称为元学习。
不过元学习的底层机制一直是个谜。
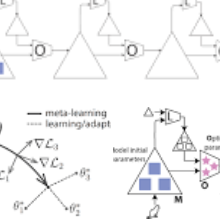
为了研究元学习的机制,DeepMind团队采用循环神经网络对人类心理建模,从过去训练过程中的动作和观察抽象出规律然后内化。
研究结果发现,元强化学习agent能够灵活地在多任务之间切换,这说明agent已经学会了怎么学习。
更重要的是,DeepMind团队发现大部分的学习发生在循环神经网络中。
这说明多巴胺不仅仅是传统学说认为的增强突触强化相应行为那么简单,还在元学习过程中起着统筹的作用(more integral role)。
按以往的认知,多巴胺只是增强前额皮质中突触的连接,从而加强某种行为。但在权重固定的情况下,神经网络在不同的任务之间依然有相同的表现。这说明多巴胺还能传递、编码任务和规律的信息。
神经网络的奖励预测误差,类似于我们人脑中的多巴胺,是一种信号:每运行一次,算法在数据上的表现就得到一次优化。
多巴胺可以影响我们人的心情,行为,感知,痛苦和快乐,对于学习过程来说,是一种非常重要的神经递质。
DeepMind团队用神经网络复现了6个神经学上的元学习实验,然后和动物实验的表现进行比较。
其中一个实验,源自上世纪四十年代一个探究元学习概念的心理学实验,叫Harlow实验。

△ 用神经网络再现Harlow实验
最初的实验设计,是在一组猴子面前摆两个它们没见过的东西,猴子捡起其中一个后可以获得食物奖励。然后随机调换物品的位置,再让猴子选。如此重复6次之后,换上新的两个物品。奖励规则一样,猴子选中其中一个才有食物。
经过训练之后,猴子学会了食物奖励只和特定的某种东西有关,而与东西摆放的位置无关。这个实验结果说明,猴子是可以掌握任务的底层规则的,换句话说就是,能学会如何学习。
给神经网络的实验设计也类似,给它们看两张从来没有见过的图,奖励与图片绑定。

△ DeepMind的神经网络在做Harlow实验
DeepMind团队在官方博客里谈到,“人类要有很强的学习能力,掌握到多变事物的规律,不可能仅依赖突触增强这种长期慢性的改变。这暗示着多巴胺很可能有能力抽象出模块化的信息。”
不过,这不是科学家首次用AI模拟人脑。
荷兰内梅亨大学就用循环神经网络预测出了人脑处理感知信息的过程,特别是视觉刺激。但DeepMind官博认为,大体来讲这些发现对机器学习领域有更大的启发,对神经生物学倒没起到什么推进的作用。
去年,DeepMind针对人脑的部分解剖结构建模,用神经网络模仿前额皮质的活动以及海马的记忆。结果得到了一个强于大多数网络的AI。最近,DeepMind把研究重心转移到了理性机制上,造了一个合成的神经网络,可进行逻辑推演以及解决问题。
通过这个多巴胺的研究,论文的作者称,医学界终于可以从神经网络研究中有所收获和启发了。
从AI里获得对神经生物学界有启发的认知洞见,这两个学科之间的互哺非常可贵。希望随着AI研究的深入,对人脑的运作机制有更多的了解,进一步设计出学习能力更强大的智能体。
最后,附论文地址:
https://www.biorxiv.org/content/biorxiv/early/2018/04/06/295964.full.pdf
— 完 —
加入社群
量子位AI社群16群开始招募啦,欢迎对AI感兴趣的同学,加小助手微信qbitbot6入群;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进群请加小助手微信号qbitbot6,并务必备注相应群的关键词~通过审核后我们将邀请进群。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态