半监督目标检测相关方法总结

极市导读
本文结合相关论文介绍了一些半监督目标检测算法,即如何利用大量的 unlabeled data 提升模型的检测性能。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
近期阅读了一些半监督目标检测(Semi-Supervised Object Detection,SSOD)的文章,特此总结,以供未来查阅。
什么是半监督目标检测?
传统机器学习根据训练数据集中的标注情况,有着不同的场景,主要包括:监督学习、弱监督学习、弱半监督学习、半监督学习。由于目标检测任务的特殊性,在介绍半监督目标检测方法之前,我们查看一下目标检测在这四个方向下的具体设定,如下图所示(不包括无监督学习):

总而言之,我们可以讲目标检测的 setting 分为四个部分:
-
有监督目标检测: 拥有大规模带标签的数据,包括完整的实例级别的标注,即包含坐标和类别信息; -
弱监督目标检测: 数据集中的标注仅包含类别信息,不包含坐标信息,如图一 b 所示; -
弱半监督目标检测: 数据集中拥有部分实例级别的标注,大量弱标注数据,模型希望利用大规模的弱标注数据提升模型的检测能力; -
半监督目标检测: 数据集中拥有部分实例级别的标注,大量未标注数据,模型希望利用大规模的无标注的数据提升模型的检测能力;
半监督目标检测方法的核心在于,如何充分利用大量未标注、多样性的数据提升模型在测试集上的性能,目前的半监督目标检测方法主要有两个方向:
-
一致性学习(Consistency based Learning) -
伪标签(Pseudo-label based Learning)
前者利用两个深度卷积神经网络学习同一张 unlabeled 图像不同扰动(比如水平翻转,不同的对比度,亮度等)之间的一致性,充分利用 unlabeled data的信息。后者利用在 labeled data 上学习的预训练模型对 unlabeled data 进行推理,经过 NMS 后减少大量冗余框后,利用一个阈值去挑选伪标签,最后利用伪标签训练模型。个人认为这两种方法没有本质的区别,本身都是伪标签技术,一致性学习可以认为是一种 soft pseudo label,而后者是一种 hard pseudo label。
接下来我讲介绍几篇近期半监督目标检测文章,主要发表在 ICLR, NeurIPS, CVPR等会议。
Consistency-based Semi-supervised Learning for Object Detection, NeurIPS 19
CSD 这篇文章是比较早期的半监督目标检测方法,非常简单,该文章提出了一个 Consistency-based 半监督目标检测算法,可以同时在单阶段和双阶段检测器上工作。
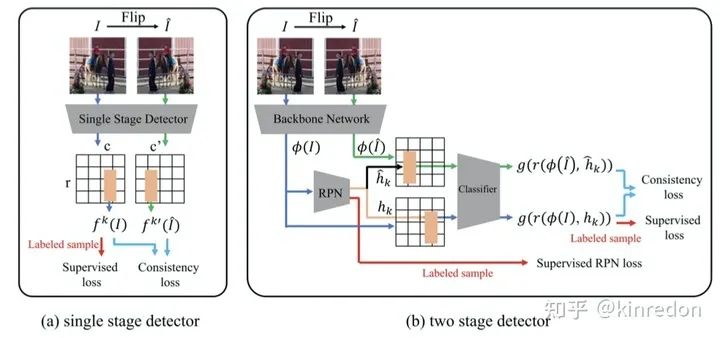
CSD 的结构如图二所示,以单阶段目标检测器为例,训练的损失函数主要包括两个部分,labeled sample 的监督损失和 unlabeled samples 的 Consistency loss。针对 unlabeled samples,首先将图像水平翻转,然后分别送入网络当中,得到对应的 Feature map,由于两张翻转的图像的空间位置是可以一一对应的,因此可以在对应的位置计算一致性损失。分类部分,利用 JS 散度作为 consistency loss;定位部分,利用 L2 loss 作为 consistency loss。
双阶段检测器的部分与单阶段检测器类似,差别主要在于 RPN(Region Proposal Network) 对于不同的输入可能产生不同的 proposals,因此在计算 consistency loss 时无法一一对应。解决此问题也很简单,两张图像使用同一个 RPN 生成同一组 RoI (Region of Interest) 来提取特征得到 proposals。
作者还提出了一个 Background elimination 方法来消除大量背景部分的损失主导训练过程的问题,因此作者定义了一个 mask 来过滤大量的背景样本:
其中,当该实例的类别不等于背景类时等于1,否则为 0。
A Simple Semi-Supervised Learning Framework for Object Detection
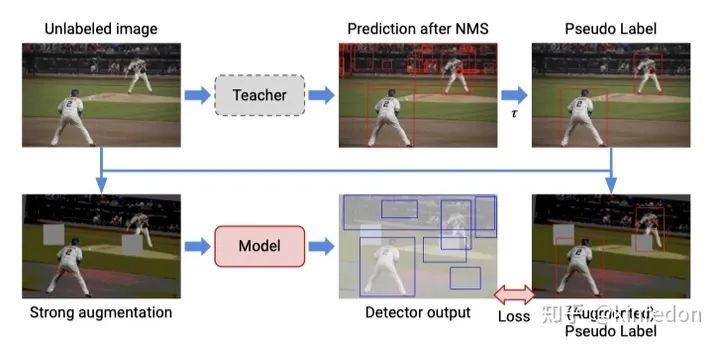
STAC 提出了一个基于 hard pseudo label 的半监督目标检测算法,如图三所示,该方法包含四个步骤:
-
首先利用 labeled data 训练一个 Teacher 模型; -
生成 pseudo label, 将 unlabeled data 输入进 Teacher 网络中,得到大量的目标框预测结果,利用 NMS 消除大量的冗余框,最后使用阈值来挑选高置信度的 pseudo label; -
应用 strong data augmentation。得到 pseudo label 后与 unlabeled image 图像相结合,包括图像级别的颜色抖动、geometric transformation(平移、旋转、剪切)、box-level transformation(小幅度的平移、旋转、剪切); -
计算无监督 loss (pseudo label)和监督学习 loss;
Instant-Teaching: An End-to-End Semi-Supervised Object Detection Framework
Instant-Teaching 主要的 motivation 在于 STAC 仅生成一次的 pseudo label,即离线生成,在训练的过程中不会更新。这样的模式存在一个问题是,当训练的模型精度逐步提升,超过原本的模型,继续使用原来模型生成的 pseudo label 会限制模型精度进一步提升。因此作者提出 Instant-Teaching,以及 Instant-Teaching*。
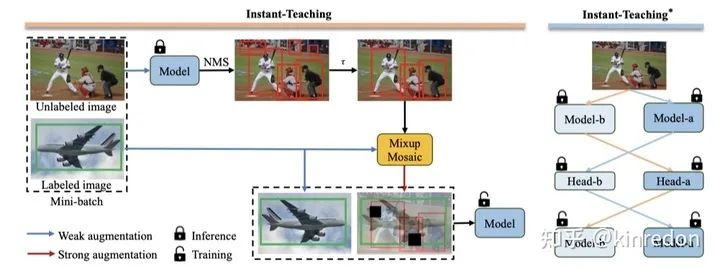
Instant-Teaching 采用即时生成 pseudo label 的模式,在每一个迭代中,包括两个步骤:
-
生成 pseudo label: 对 unlabeled image 进行 weak augmentation,送入模型中得到 hard label; -
利用生成的 pseudo label 进行 strong augmentation,除了 在 STAC 中的数据增强,还包括了 Mixup 和 Mosaic,利用增强后的数据训练模型;
Instant-Teaching 主要提出了一个 co-rectify scheme 来解决 pseudo label 的 confirmation bias 的问题(噪声 pseudo label 的错误累计效应)。因此,作者利用两个模型,给予不同的初始化参数,输入不同的数据增强的样本,分别彼此纠正和检测对方生成的 pseudo label,形式如图四右半部分。
Data-Uncertainty Guided Multi-Phase Learning for Semi-Supervised Object Detection
这篇工作提出一个多阶段的学习半监督目标检测学习算法,前面的方法基本在伪标签生成后,直接拟合生成的伪标签,这样将会引发 label noise overfitting 问题,即由于深度网络较强的拟合能力,即时错误的标签模型也能够拟合。因此作者利用图像级别 uncertainty 来进行多阶段学习,思想类似于课程学习(curriculum learning),先学习 easy 样本再学习 difficult data。具体来说,作者利用 RPN 出来的 proposal 的平均分数作为 uncertainty 的指标。平均分数越高,uncertainty 越小,视为 easy sample,反之为 difficult sample。
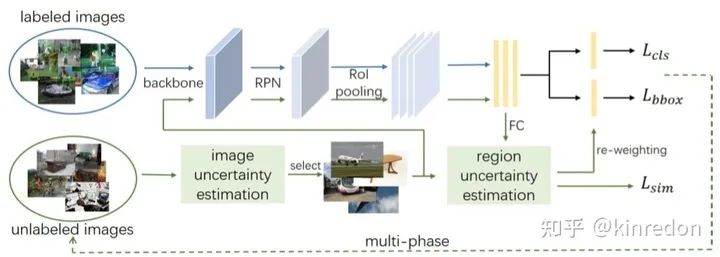
在区域级别,作者提出 RoI 的 re-weighting 操作,作者从 Soft sampling for robust object detection 得到启示,对于具有噪声的数据(伪标签),在训练时,不同的 RoI 应该给予不同的权重,作者提出了几个的简单但有效的策略来解决这个问题,受限于篇幅,这里不再具体介绍,感兴趣可以去阅读原文的 Section 3.3.2.
Unbiased Teacher for Semi-Supervised Object Detection
这篇文章发表在 ICLR 2021, 主要思想还是说现在的半监督目标检测算法生成的标签具有 bias,这里作者主要 argue 的点在于目标检测中存在天然的类别不平衡问题,包括 RPN 前景和背景的分类,ROIHead 的多类别分类,因此作者提出了一个 Unbiased Teacher 方法,来解决此问题。
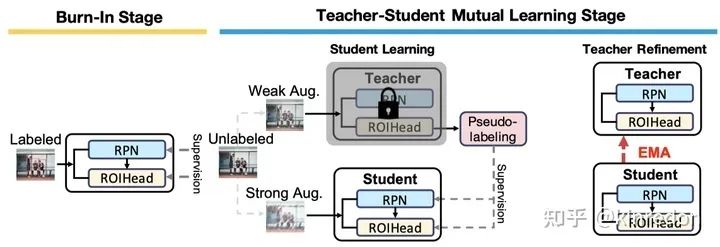
从方法上来说,非常的简单,首先是 Burn-IN stage,即在 labeled data 上训练一个预训练模型,然后利用 Mean Teacher 的结构,Teacher 生成 Pseudo label 来同时监督 RPN 和 ROIHead。不同的点在于,作者只利用 pseudo label 更新 RPN 和 ROIHead 的 classification 分支,主要原因在于由 confidence score 生成的 pseudo label 与 bounding box 位置的质量关系不大。除此之外,作者将原本的 cross entropy loss 替换为 Focal loss 来解决 pseudo label bias 问题,即 class imbalance 。
Interactive Self-Training with Mean Teachers for Semi-supervised Object Detection
这篇文章揭示了之前利用 pseudo label 的方法忽略了同一张图片在不同的迭代的检测结果之间的差异性,而且不同的模型对同一张图像的检测结果也有差异。

因此作者提出一个基于 Mean Teacher 的 Interactive form of self-training 的半监督目标检测算法:
-
解决不同训练迭代检测结果的不稳定问题,作者使用 NMS 将不同迭代的检测结果进行融合。 -
同时利用两个检测头部 ROIHead 生成 pseudo label,两个检测头部可以相互提供有用的互补信息。
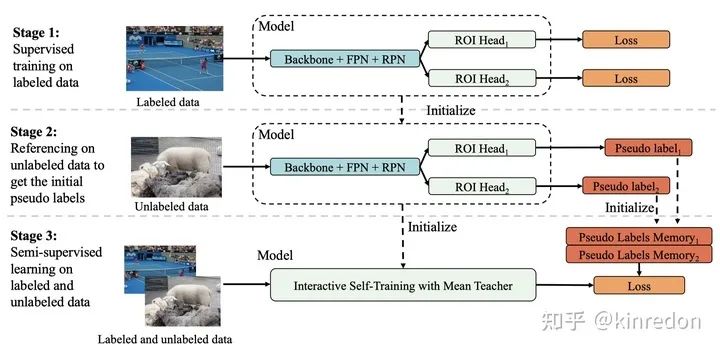
IST 算法的主要步骤如图八所示:
-
使用 labeled data 训练一个拥有两个 ROIHead 的预训练模型 -
利用预训练模型生成两个对应的伪标签 -
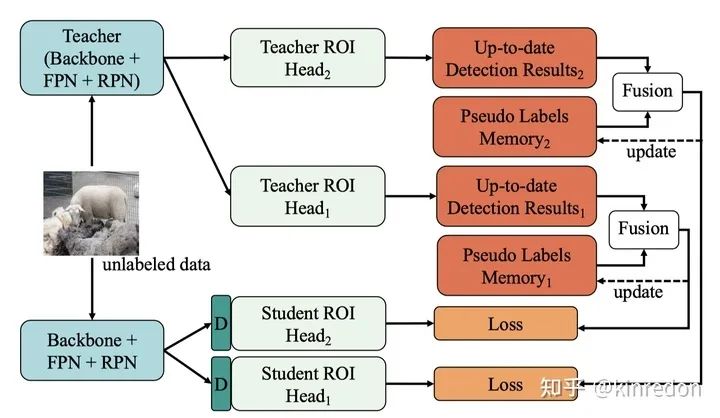
利用 labeled data 和 unlabeled data 进行监督学习,图八中 Pseudo Labels Memory 用来使用 NMS 融合不同迭代的检测结果。该步骤详情如图九所示,利用 Mean Teacher 的结构,teacher 生成 pseudo label 并与 Memory 中的 pseudo label 进行融合,并更新 Memory。作者使用 Dropblock 模块确保不同的 ROIHead 能够独立收敛,并提供互补的信息,即图九中的 D。
总结
本文介绍了一些半监督目标检测算法,即如何利用大量的 unlabeled data 提升模型的检测性能,当前主要的方法包含 consistency based 以及 pseudo label based 两类。consistency based 方法主要学习模型在 unlabeled data 上的一致性,pseudo label 则利用在 unlabeled data 上生成 pseudo label 进而监督模型训练,主要的方向即为如何生成高质量的伪标签以及模型如何对抗在 unlabeled data 上的 noise label。本文介绍了的半监督目标检测方法不多,关于方法的介绍较为笼统,如有谬误,烦请指正,其中细节,还需仔细阅读文章,欢迎讨论。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“transformer”获取最新Transformer综述论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~




