深度剖析 | 推荐系统中的信息茧房问题——因果强化学习在交互式推荐的前沿探索
作者:高崇铭
单位:中国科学技术大学博士生,快手实习
第一次写博客,这篇博客的目的是想分享和探讨一些在交互式推荐或者序列推荐问题中的一些关键痛点,其中最大的一个就是信息茧房问题。
“信息茧房”在英文文献中,可对应Filter bubble(过滤泡)这个词,由美国一个著名的互联网活动家Eli Pariser发明,并随着其著作《The Filter Bubble: What The Internet Is Hiding From You》以及9分钟TED演讲[1]变得广为人知。其实还有相似的英文概念,比如Echo chamber,Epistemic bubbles,Information cacoon。这些词汇的发源领域和场景有区别,但渐渐被大家混用。
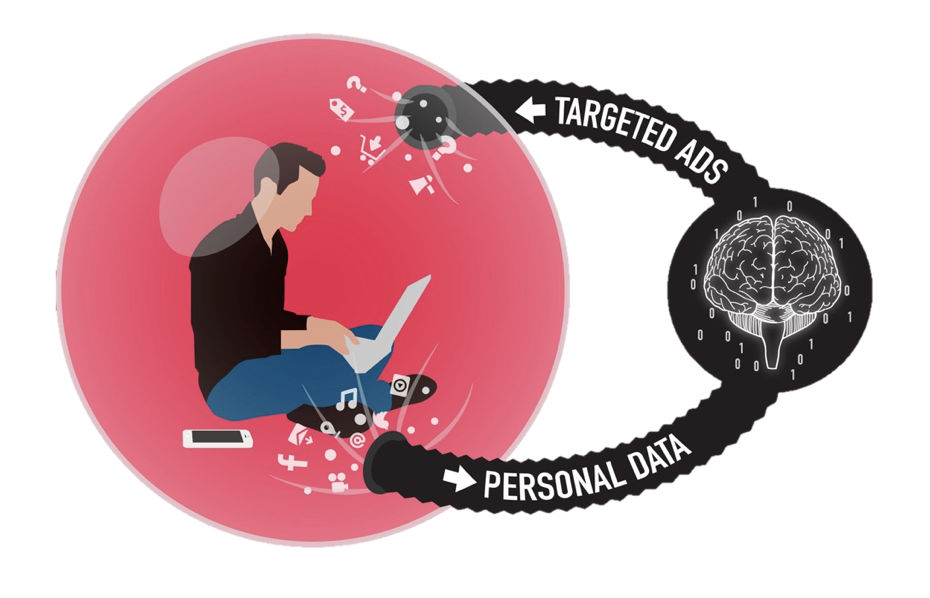
在当今信息时代的语境下,信息茧房着重描述互联网的用户们接受的信息(新闻消息、商品推荐、思想观念等)在算法干预下变得逐渐单一的现象。这一现象的结果是,一方面让我们能够享受到网络给我们带来的方便快捷和舒适,另一方面也或多或少地限制了我们求知、思考、探索和创新的能力。
故信息茧房是一个很有价值的议题。在本博文中,我想结合自己的专业方向谈一谈信息茧房在推荐系统中的一些定义、影响以及解决思路。个人见识有限,说的观点可能有漏洞,希望大家能够一起探讨交流。
以下的很多观点,都已经总结在我们的这篇论文中了:

代码:https://github.com/chongminggao/CIRS-codes
推荐系统中的信息茧房:过曝光效应
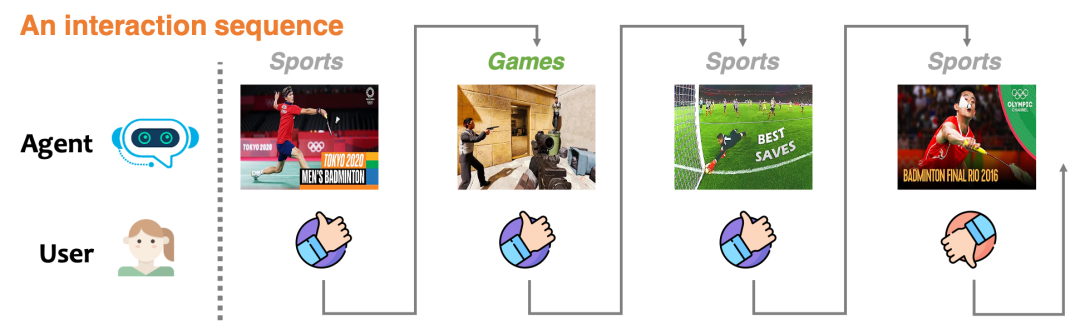
推荐系统的目的是准确拿捏每个用户的喜好,从而给用户主动提供投其所好的商品、信息或服务。好的推荐系统让用户欲罢不能,淘宝抖音快手B站知乎网易云音乐,总有一款让你印象深刻。为了方便叙述,我们就以短视频为例,经典例子如众所周知的抖音快手。沉浸其中,难免能发现信息茧房的影子,那就是:相似的短视频开始重复出现在时间线上。用正式一点的话来描述就是,特定的视频被过曝光(overexposure)了。
造成这种结果有两方面的原因:
-
用户就喜欢只看特定类型的视频。那我举例,就喜欢看羽毛球、电子游戏、摄影作品这几种类型的视频。每天看,不亦乐乎。 -
算法端在训练过程中,只强调了用户的部分主流兴趣。大多数算法都会出现在数据头部过拟合、尾部欠拟合的问题。
无论是哪方面的原因,在不加干预的情况下,由于推荐系统的持续学习性,这个过曝光效应将会随着时间逐渐积累,在“系统推荐—用户反馈—系统再推荐”的这一反馈环路(feedback loop)中逐渐扩大,越来越严重。最后的后果必然是推荐结果的高度相似、趋同性。这时候,爱好再专一的用户也无法接受了。
下图展现出了一个信息茧房的例子,当推荐系统从一开始的多元到之后的过分单一,用户难免感到腻烦。
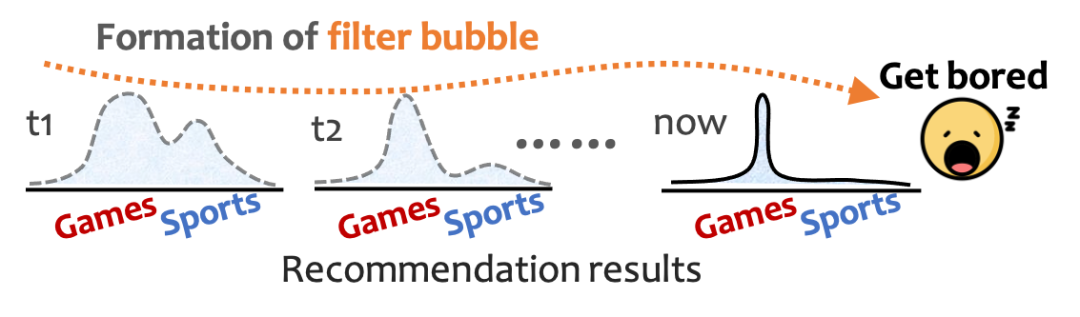
另一方面,我在快手实习的这几年,与大佬们交流的过程中也能总结出一些经验:短期来看,推荐系统的单调和趋同能够让用户上头并多刷一会儿。但从长期的指标来看,这样的推荐方式将降低用户的活跃性,降低用户留存率。
故,作为推荐算法的设计者,我们需要主动避免这种单调的推荐结果,我们需要避免信息茧房!
怎么量化信息茧房的影响呢?我们将信息茧房与过曝光效应挂钩。而过曝光效应可定义为:相似的商品在短时间内重复出现的次数。至于相似有多相似,时间有多短,这个只需要定义合适的度量函数即可。
这里其实还有一个问题,过曝光效应和信息茧房这二者之间,到底谁是因谁是果?是信息茧房导致了过曝光效应,还是由于算法的过曝光产生了信息茧房?对于这个问题,我的个人看法是,鸡生蛋蛋生鸡,两者互为因果。所以,我上面用词是,将两者“挂钩”,通过度量过曝光效应,我们就能得知此时此刻信息茧房的严重程度。
缓解、消除信息茧房的思路:
最直观的方式有提升推荐结果的多样性(diversity)、新颖性(serendipity)等,通过各种规则(rule)来干预推荐结果,使其不陷入单调的境地。下图总结了一些在推荐系统中常见的策略,详情可以参考我们论文引用部分。

这些不失为很好的方式,然而,简单的规则在复杂的推荐场景中,将面临一系列问题,例如:在什么情况下增大多样性?对所有的用户都应该采用相同的方式增大多样性?如果答案为否,那对不同的用户该如何控制其多样性的程度?
这时候,就发现简单规则(rule)的局限性了。对于复杂的环境,最省事的方法:开发一个自适应的策略(policy),自动地回答以上问题。那么,这个策略的根本思路是什么?抓住用户满意度(User satisfaction)与其内在兴趣(Intrinsic interest)与过曝光效应(Overexposure effect)之间的关系。
根据上一小节的讨论,我们能够建模,用户满意度与内在兴趣正相关,与过曝光效应负相关。如下图所示。
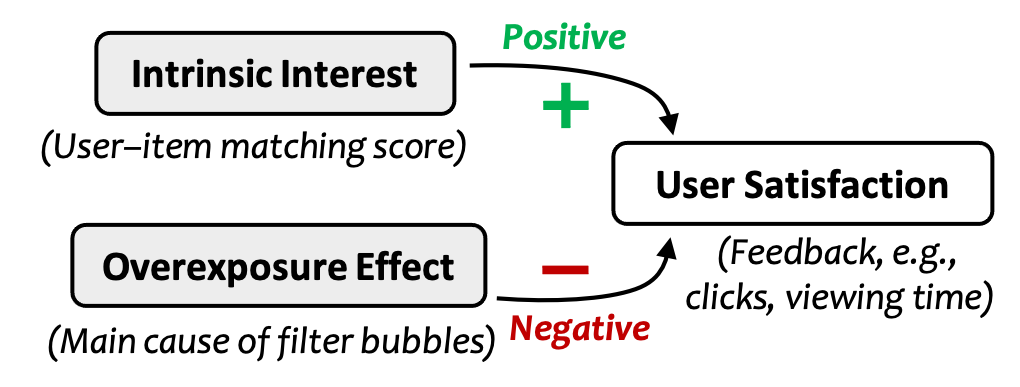
举例来说,比如我很喜欢看动漫火影忍者,内心深处憋着满满的热血(有内在兴趣),但是,如果我的短视频App天天给我推火影,其他啥也不推(过曝光了),那我也不买账啊,时间长了我也想看其他内容啊,看到火影的视频我就想跳过了(满意度下降)。
下一步,该如何建模上述的正相关、负相关呢?
我们采用了一个很合适又切合当下主流研究的技术:因果推理。对以上三个因素做出因果图。
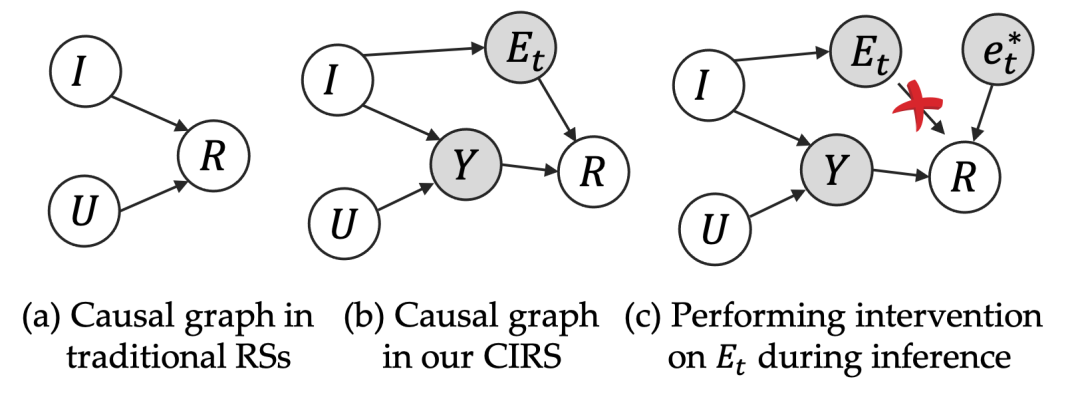
图中的因素的意义如下:
-
:代表特定的一个用户 的ID信息或特征向量。
-
: 代表一个推荐给用户 的特定商品 .
-
: 用户满意度,也代表奖励信号reward.
-
: 用户内在兴趣 (不取决于item曝光情况)
-
: 商品 对于用户 的过曝光程度*.* 其中 是随机变量 在强化学习规划阶段(因果推理阶段)的一个具体取值。
而图中从左到右,分别是 (a) 传统的推荐系统建模,其中用户满意度(反馈信号)只由用户对商品本身的兴趣决定。而 (b) 中则是我们模型建模方式,满意度由用户内在偏好决定,同时又受到过曝光信息的负向影响。
-
:这条路径刻画了用户内在兴趣 对最终满意度 的影响,在本文中实现为传统的DeepFM推荐模型。也可以由其他推荐模型进行实现。
-
:这条路径刻画了过曝光效应 对用户最终反馈的影响。
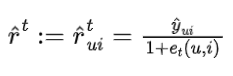
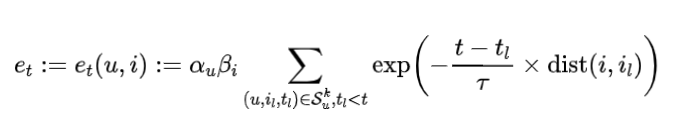
需要注意的是,我们的因果图没有走传统套路!按照传统套路的因果建模, 这个位置通常会被建模成为一个混淆因子(Confounder,具体可见下文因果部分讨论)。但我们在商议后觉得这并不符合实际情况,于是画出了这样反套路的因果图,所有的剪头都从左到右。更符合实际意义。
这就是我们论文对这些量的核心建模部分,至于模型的具体实现,是一个基于离线强化学习的交互式推荐系统。见下文分析。
为什么要选交互式推荐系统(Interactive Recommendation)?
-
可行性:因为这才是最接近真实推荐场景的系统。如上图,所有上线了的推荐系统,都是一来一回的工作的,并不是像传统推荐论文那样在训练集上训练好了之后,参数从此固定,再在测试集上进行工作。线上的推荐系统,是在不断根据用户的反馈进行实时调整的。 -
必要性:只在这样现实的序列(sequential)数据上,我们才能够对用户兴趣做出实时追踪,才有评测信息茧房的能力!
下图的左边给出了一个交互式推荐系统的流程,区别于传统推荐系统只需要一个静态模型,交互式推荐得到的是一个策略(policy) ,一个策略就像一个大脑一样,能根据系统目前的状态 给出一个合适的动作 。状态在这里,表示交互的上下文、以及用户此时此刻的心情、偏好;动作在这里自然就是推荐。
下图右边给出了我们提出的CIRS模型的流程。主要分为两步,学习一个因果用户模型(causal user model),再学一个强化学习的策略 。这就是一个强化学习模型的流程。
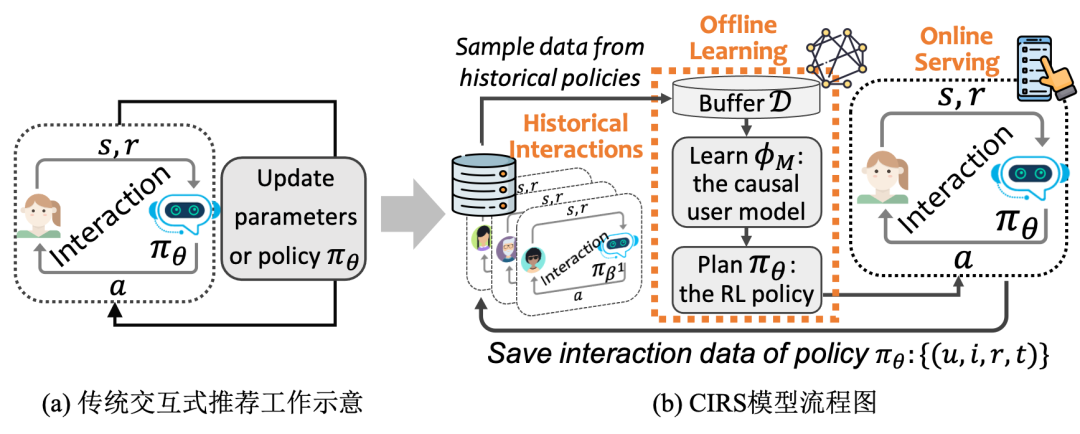
至于一个策略,而不是传统的静态模型,请看下文,为啥我们需要用离线强化学习?
为什么要用离线强化学习(Offline Reinforcement Learning)?
这个问题蕴含着两个子问题:
-
为什么要用强化学习(RL),而不是监督学习(Supervised learning)? -
为什么要用离线强化学习(Offline RL)?“离线”二字如何理解?
相信第一个问题困扰了很多同学。这里给出我总结出来的最简洁到位的答案:
-
强化学习的目标是累计收益,其做出的动作对未来是有着好处的,尽管其在当下看来可能不是一步好棋。而监督学习,只是在简单拟合数据,贪心地得到一个单步最准确的答案。 -
强化学习得到的是一个策略,这个策略就像一个大脑,能够自动根据不同状态做出不同动作。而监督学习得到的只是一个静态模型。实际上线这个静态模型的时候,我们也需要加很多人工策略,比如“之前推荐过的东西就不能再次推荐”这一规则。
深入理解这两点,你就能知道为什么强化学习如此重要,为什么机器学习三大会如此热衷研究强化学习。
至于第二个问题的答案,则好理解得多。强化学习的策略模型需要与环境进行动态交互,在玩游戏领域,这个在线交互很容易。但在自动驾驶领域,我们不可能用真实汽车去上路训练强化学习策略吧,这个试错代价承受不起。同样地,在推荐系统领域,线上的用户就是真实环境,我们没法随意给用户推荐东西来在线学习强化学习策略。
与此同时,我们有大量的离线log啊,那都是历史的策略与真实用户留下的交互记录。不管历史策略是啥,反正我们有这个数据。于是,如何利用已经发生的离线数据,来学习本来应该在线学习的策略,成为近两年机器学习领域最重要的研究课题之一。
关于离线强化学习,可参考这篇这篇综述:Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems[2]。
我们在论文中的离线强化学习的实现框架图如下:
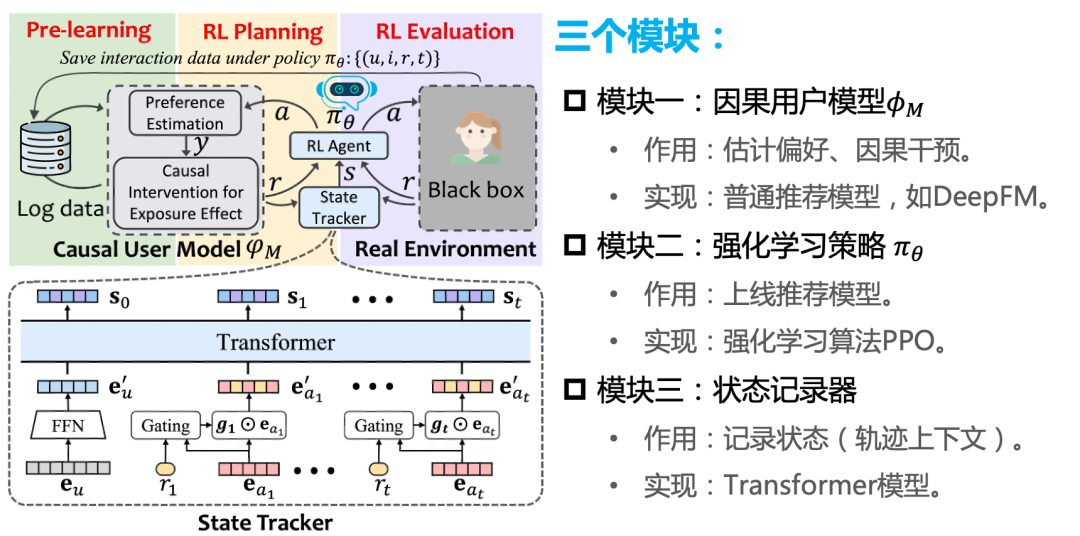
具体工作原理可见原论文。
怎么做实验?怎么评测信息茧房?
大家看到这应该累了。但还没结束,这部分其实才是痛点。一个很值得思考的问题:
如何离线评测信息茧房带来的危害?如何在离线数据上评测出用户的“腻烦程度”?
答案是:不可能!这也是传统推荐系统研究工作中评测方法的局限。
正确方法是啥?要么上线进行A/B test,这个上面说过,不现实。要么就是在离线数据上做文章。
首先,要想得知任一用户对任意推荐商品的喜好,传统的推荐数据做不到,过于稀疏了。而我们在快手App上收集了一个全曝光的数据,解决了这个问题。见下图红色的小矩阵部分,1411个用户对3327个视频的偏好全部已知。
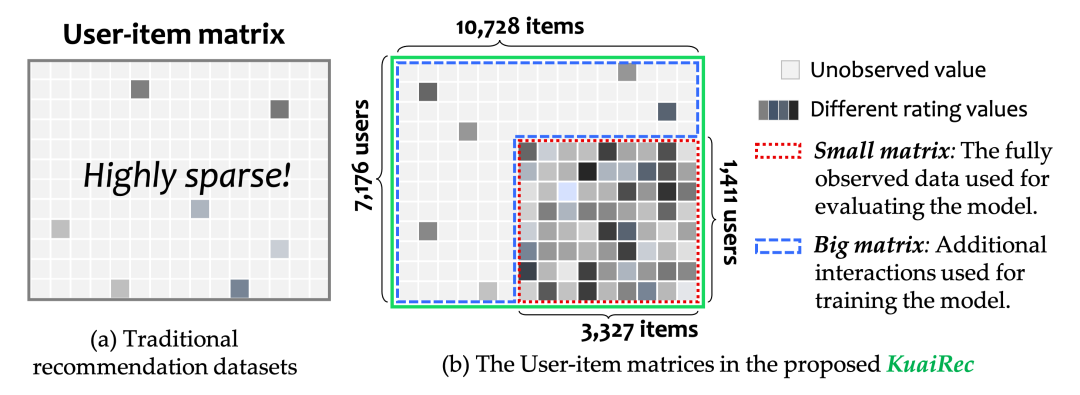
关于数据集这部分请见我的另一篇博文:快手+中科大 | 全曝光推荐数据集KuaiRec 2.0版本。
其次,我们还是无法在离线情况下得到重复曝光后用户的“腻烦心理”。这一步无解,我们只能模拟这个机制。模拟出这个机制后,我们对不同策略模型进行评测,也是公平有效的。
这个机制如何模拟呢?具体来说,在上述收集的全曝光的小矩阵数据上,我们从真实的1411个用户中随机采样并与训练好的交互式推荐策略模型进行交互。在推荐策略返回推荐结果,即从3327个商品中任一推荐一个商品后,我们查询小矩阵数据的对应的用户喜好值并如实返回作为监督信号,这个过程将一直重复。此外,我们指定一个使得交互中止的规定:即如果当前推荐的商品与最近 轮推荐的商品中有超过阈值 个商品有着相同的类目,例如都是美食类,则交互退出。
下图给出了一个退出的机制的示意图,除了上文提到的快手数据以外,我们还用了VirtualTaobao这个强化学习的交互环境。
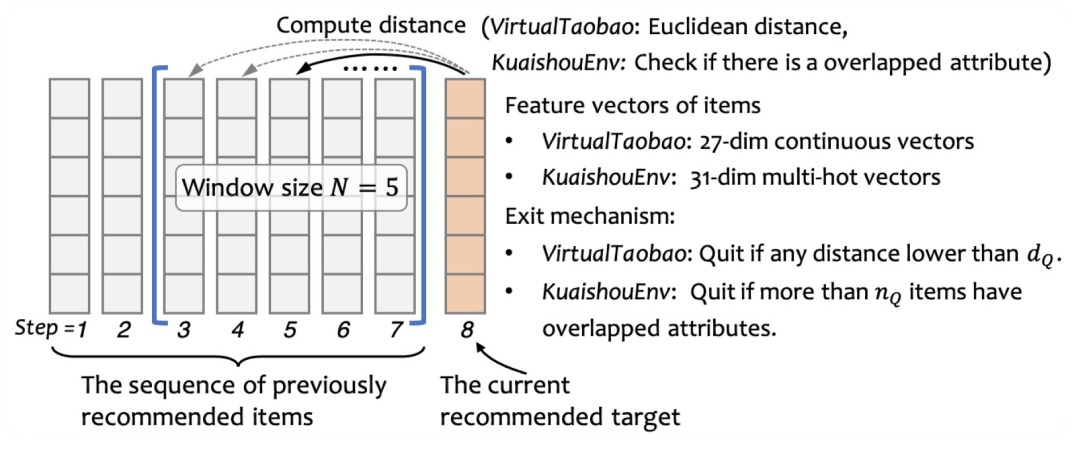
这个评价过程也是本发明的独到之处之一。在这个评价体系下,交互式推荐模型既要保证每轮推荐有着高准确率,又要保证连续推荐不能让推荐的商品重复。从而考验策略的自动平衡能力。我们的评价的指标如下图所示:
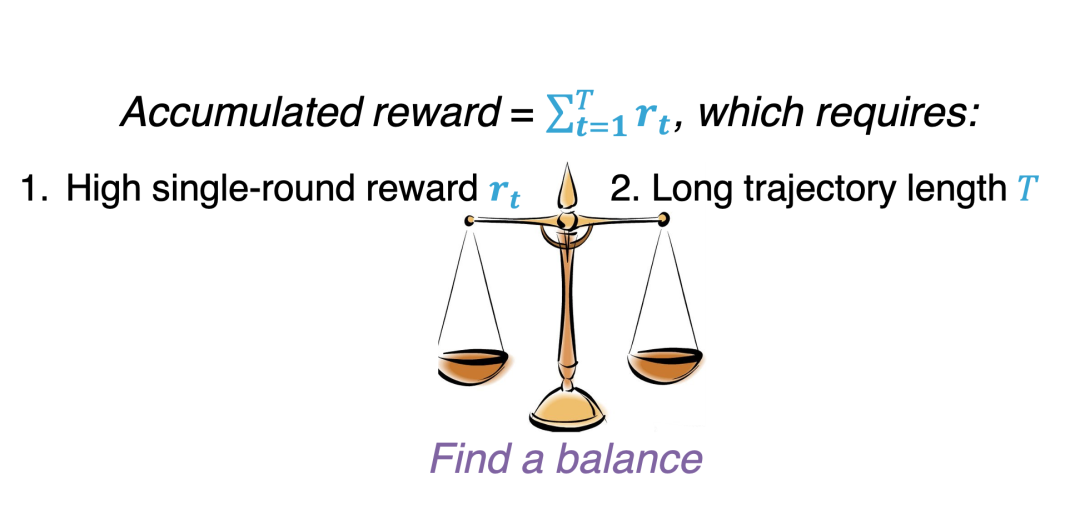
这种评测方式也是一种创新吧。我很喜欢这篇工作,因为从头到尾都是各种好玩的新东西。这里就简单放一下这种评测下的结果,见下图所示,具体讨论可见原论文。
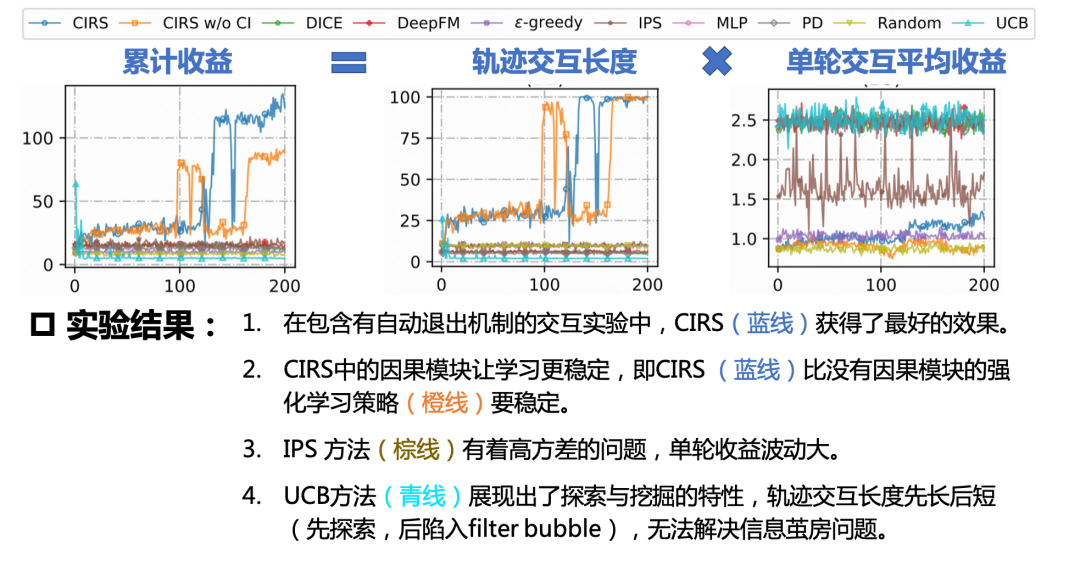
快手业务端实际上线性能
这个是最近的进展和成就!我们已将该离线强化学习框架落地在快手App的精选页的端上重排场景中。并在线上利用了10%的流量进行了A/B test。经过调试得到了两个显著的成绩:
-
推荐多样性指标大幅改善!这个结论符合预期。 -
很多重要指标也获得一些提升,包括用户App使用时长这种关键指标。
第二点成就非常喜人,这意味着我们在端上大幅提升多样性的同时,用户不仅没有排斥,还更喜欢看了!这也成为离线强化学习在真实业务中获得应用的样例。
当我们在说因果的时候我们在说什么?
关于因果的介绍,我认为最好的是下面这篇博客,曾经我的本科师弟,现在已成大佬的王谭写的这篇介绍文章:无监督的视觉常识特征学习——因果关系上的一点探索(CVPR 2020)[3]。
目前主流的研究方向有两个分支:
其一是以图领奖获得者Judea Pearl的因果图模型,此外是以potential outcome为核心假设的Rubin因果模型。
这部分有空再展开讲吧。推荐我觉得讲的最好的一个Ph.D.大佬Brady Neal的课程以及他写的书: 在这个链接:Introduction to Causal Inference[4]。
结语
本来只是想浅浅介绍下这篇工作,但涉及的点有点多,不知不觉就写了挺多。这篇工作只能说是结合了因果推理和离线强化学习的一篇工作,思路比较简单直观。因果强化学习,这是一个很棒的方向,相信只是刚刚开始。
关于这篇论文的代码,PPT,数据集等信息,可从我主页上获取:https://chongminggao.me/
关于这篇论文的代码的技术解析,请见论文作者之一,重庆大学的王诗琦同学的长解析:CIRS: Bursting Filter Bubbles by Counterfactual Interactive Recommender System 代码解析(超详细噢…φ(๑˃∀˂๑)♪ )[5]。
参考链接:
[5]. https://zhuanlan.zhihu.com/p/493236410
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。

