RoI Pooling 与 RoI Align 有什么区别?

极市导读
本文主要介绍了RoI Pooling与RoI Align的原理、差异和作用,并举例解释了执行步骤。>>加入极市CV技术交流群,走在计算机视觉的最前沿
基本概念
RoI
RoI(Region of Interest)是通过不同区域选择方法,从原始图像(original image)得到的候选区域(proposal region)。
需要注意的一点是RoI并不等价于bounding box, 它们可能看起来像,但是RoI只是为了进一步处理而产生的候选区域。
bounding box
boundding box 指的是检测目标的边界矩形框。
量化
量化(quatization)是指将输入从连续值(或大量可能的离散取值)采样为有限多个离散值的过程。也可以理解为,将输入数据集(如实数)约束到离散集(如整数)的过程。
RoI Pooling 和 RoI Align的作用
RoI Pooling 对于任意大小的图像输入,总能产生固定大小的输出。
Region features always the same size even if input regions have different sizes!
RoI Pooling 原理
RoI Pooling在Fast RCNN 中被首次提出。
RoI Pooling 直接从feature map 里截取各个兴趣区域(Region of Interest, RoI)的feature, 并换为为相同大小的feature输出。
RoI Pooling = crop feature + resize feature
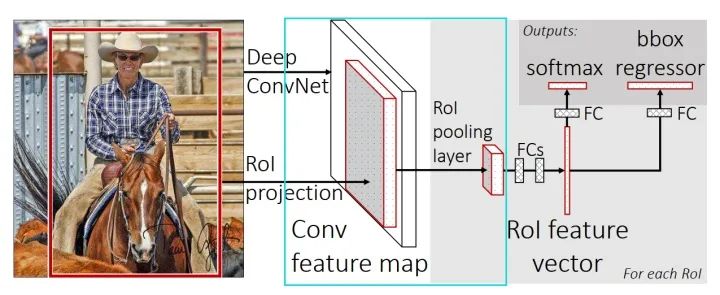
通过上图的容易得到,RoI Pooling的作用本质上是为了将不同尺寸的RoI特征转换为相同的特征图输出,保证特征图展开(flatten)后具有相同的大小尺寸,能够与下层的全连接层连接,分别执行线性分类(linear classifier)和边框回归(bounding box regressor)。
执行步骤
-
前置条件
对于输入图片,通过候选区域方法发网得固定大小数量(Faster RCNN中为256)的候选区域坐标,。
将整个输入图片喂入基网络(如vgg, resnet等)提取图片的特征(Fast RCNN 中为vgg网络的conv5层特征)。
下面以输出目标特征图尺寸大小为 进行说明
-
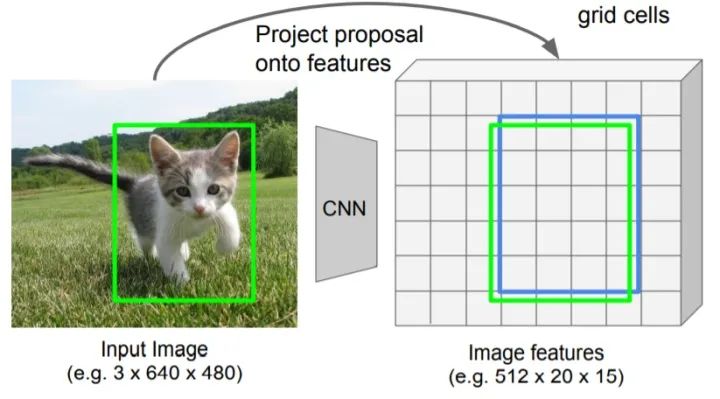
对齐到网格单元(snap to grid cell)
首先将一个浮点数RoI量化为特征映射的离散粒度。表现为RoI对应的特征图的与原始特征图的网格单元对齐。这里为第一次量化操作。
下图中绿色框为RoI对应的实际区域(由于经过特征尺度变换,导致RoI的坐标会可能会落到特征图的单元之间), 蓝色框代表量化(网格对齐)后的RoI所对应的特征图。(得到到量化特征图尺寸为 )
-
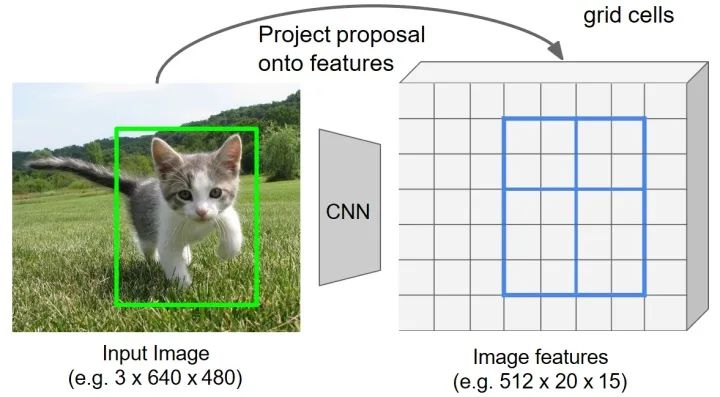
划分网格为子区域(bin)
粗略地将网格分为 (Fast RCNN 中设为 )个子网格区域。将上一步得到的量化RoI 特征进一步细分为量化的空间单元(bin)。这里进行了第二次量化操作。
为了得到输出的特征图为 ,这里的量化操作就是将上一步的到量化特征图划分为 个特征单元。如果无法通过直接均分得到量化的子区域,通过分别采取向上取整(ceil)和向下取整(floor)的到对应的单元尺寸大小。以当前 尺寸的特征图为例,对于宽度方向 ,,但是对于高度方向由于 , 通过向上和向下取整整,确定高度方向特征子区域的大小分别为2和3。
-
最大池化操作
在每一个子区域执行聚合操作得到单元的特征值(一般是最大池化)。对上一步得到的 个子区域分别做最大池化操作,得到 的目标特征图。
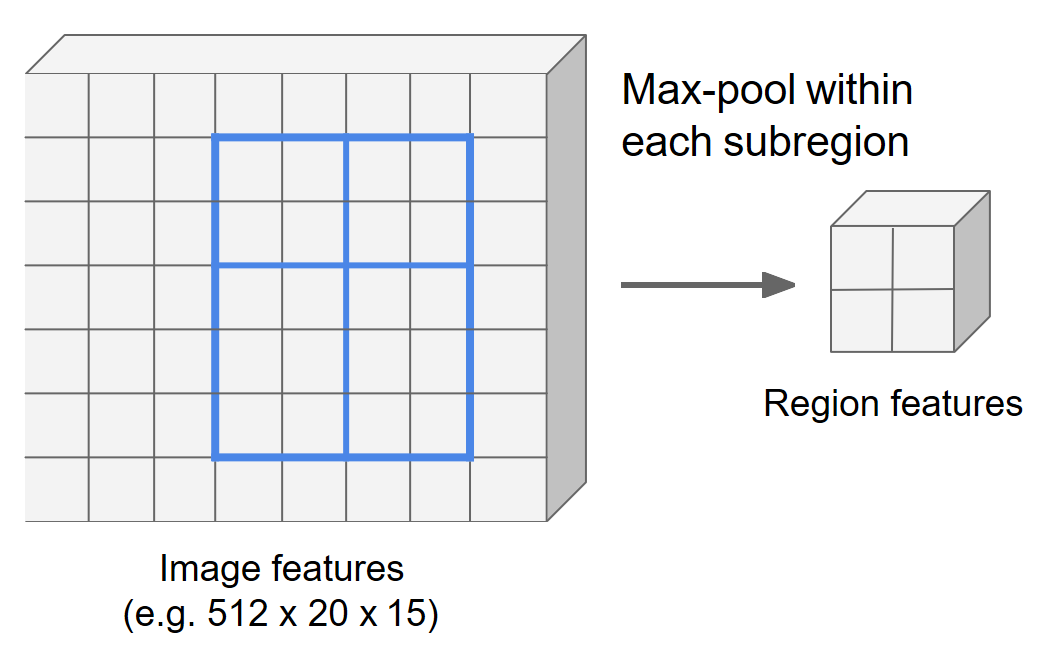
执行结果
通过RoI Pooling, 对于具有不同特征大小的的输入区域, 都可以得到相同大小输出特征。
缺点
每一次量化操作都会对应着轻微的区域特征错位(misaligned), 这些量化操作在RoI和提取到的特征之间引入了偏差。这些量化可能不会影响对分类任务,但它对预测像素精度掩模有很大的负面影响。
RoI Align 原理
RoI Align 在 Mask RCNN 中被首次提出。
针对RoI Pooling在语义分割等精细度任务中精确度的问题提出的改进方案。
执行步骤
下面以输出目标特征图尺寸大小为 进行说明
-
遍历候选每个候选区域,保持浮点数边界不做量化(不对齐网格单元);同时平均分网格分为 (这里为 )个子网格区域,每个单元的边界也不做量化。
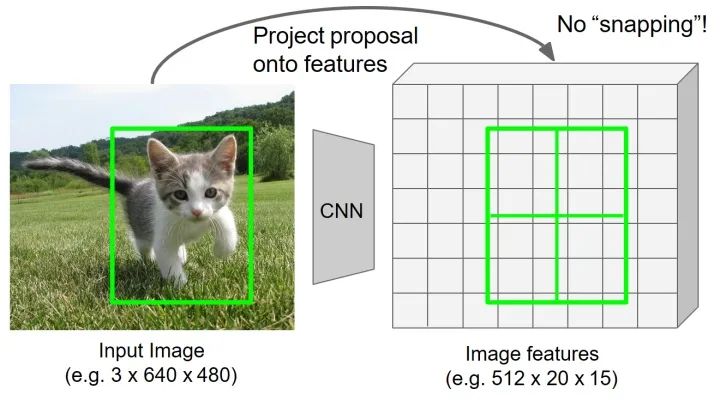
-
对于每个区域选择4个规则采样点(分别对应将区域进一步平均分为四个区域,取每个子区域的中点)。
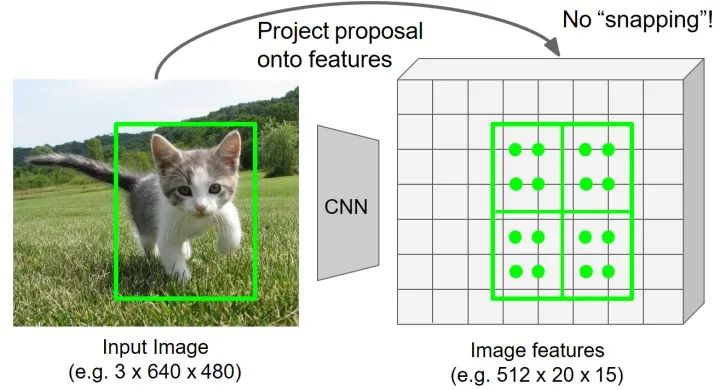
-
利用双线性插值计算得到四个采用点的像素值大小。下图为一个规则采样点所对应的邻近区域示意图。
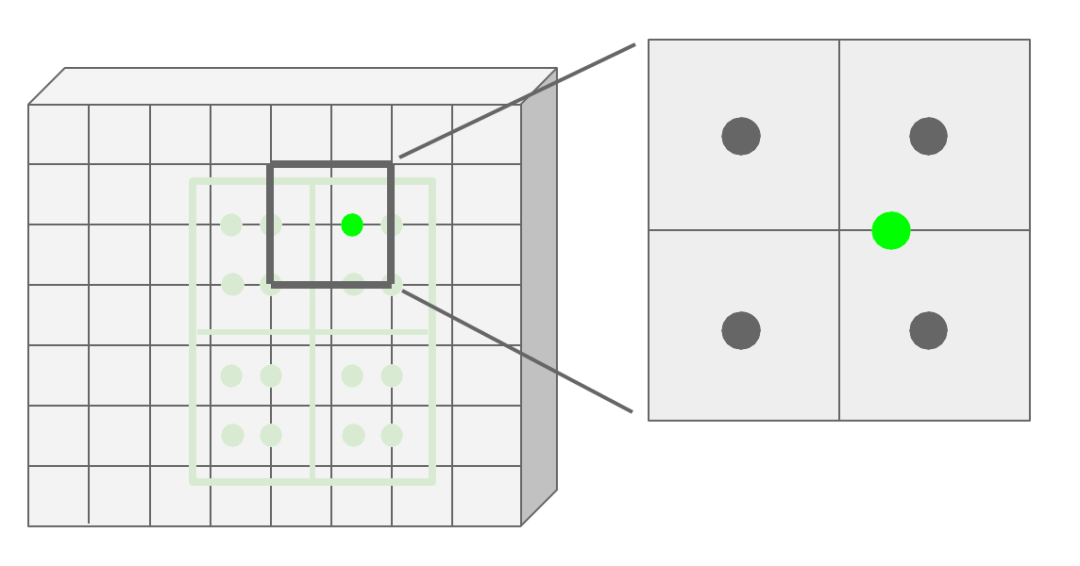
-
利用最大池化(max pooling)或平均池化(average pooling)分别对每个子区域执行聚合操作,得到最终的特征图。
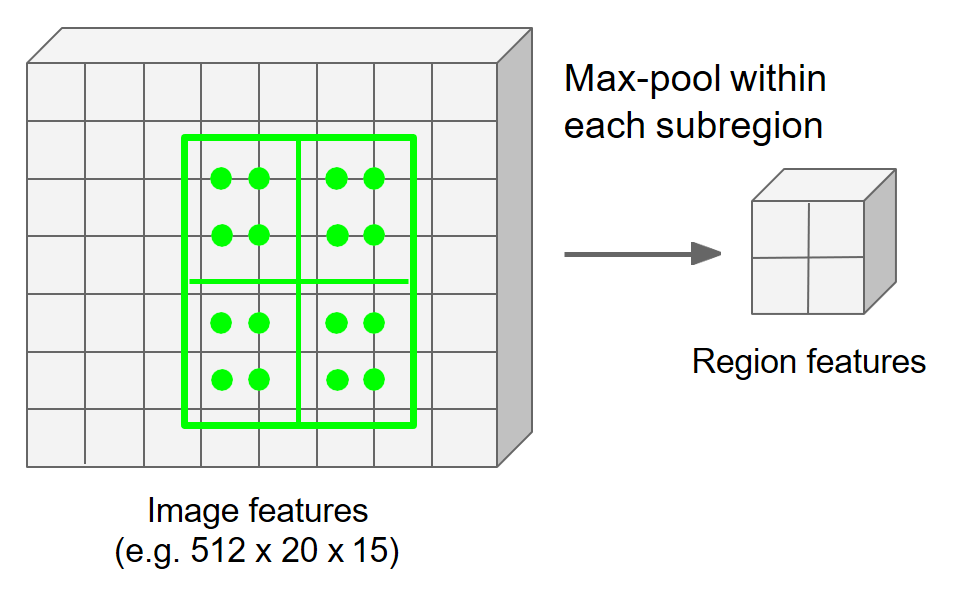
执行结果
通过RoI Align, 对于具有不同特征大小的的输入区域, 都可以得到相同大小输出特征。
补充
双线性插值
-
概念
双线性插值(bilinear interpolation),又称为双线性内插。在数学上,双线性插值是有两个变量的插值函数的线性插值扩展,其核心思想是在两个方向分别进行一次线性插值。在数字图像和音频处理领域都有应用。
在图像处理中,双线性插值法考虑围绕未知像素的计算位置的 最近邻域的已知像素。然后对这4个像素进行加权平均,以得出其最终的内插值。
-
公式推导
如图,已知求位置像素P的像素值, 已知相邻 的像素区域对应位置和像素值,其中坐下角像素区域标号为11,左上角像素区域标号为12,右下角像素区域标号为21,右上角像素区域标号为22。
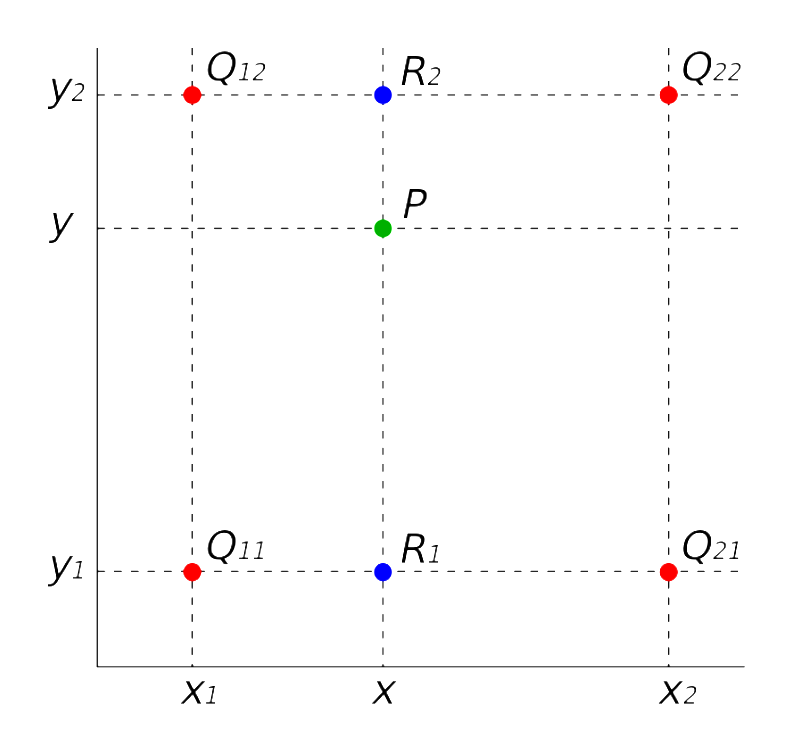
注意 , , , ,分别对应像素单元(区域)的中心点。
线性插值的计算公式描述:已知直线上两点 , , 求直线上任意一点 的值 。
第一步,利用公式 执行两次线性插值操作:使用 和 计算 点的像素值大小;使用 和 计算 点像素值大小。
第二步, 利用公式 和公式 的到的结果,再次执行一次线性插值,得到目标位置 的像素值。
由于 , , , 分别为相邻像素的中间位置坐标,如下图所示。
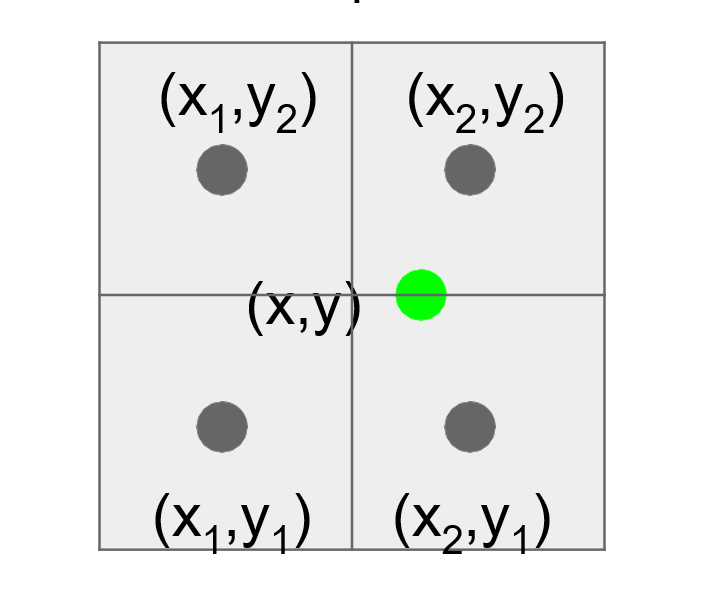
容易得到 , ,因此双线性插值公式 可以进一步简化为
同理容易得到
公式 也可以进一步表示为
-
公式物理意义
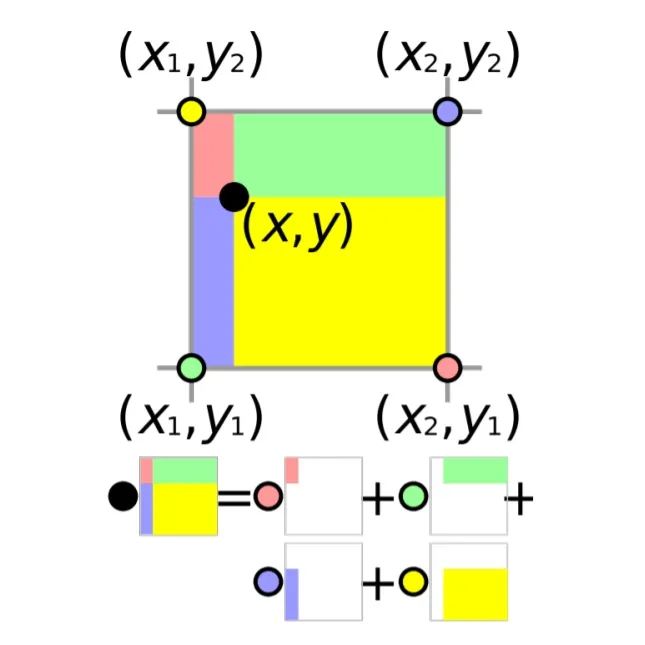
通过公式 可以看出, 双线性插值本质上是目标像素值相邻四个像素的像素值加权和值。
对于第一项 表示右上角像素 的像素值加权后的结果,其对应的权重公式 ,可以看出第一项权重本质上是目标像素 对应的对角像素 所构成的矩形区域的面积大小,如上图紫色区域。同理其它三项也满足同样的规律。
当目标元素与某个相邻元素的距离越近,目标元素元素与该相邻像素的对角像素组成的矩形框面积大小就越大,该相邻像素对应的权重值就越大。
综上可以得到, 双线性插值本质上是目标像素所相邻的四个像素, 分别以像素对应的对角像素与目标像素的构成的矩形区域为权重,像素大小为值的加权和。
参考资料
推荐阅读






