推荐!2022综述论文《强化学习在航空中的应用》第一份调查航空领域RL方法的研究论文,

1 引言
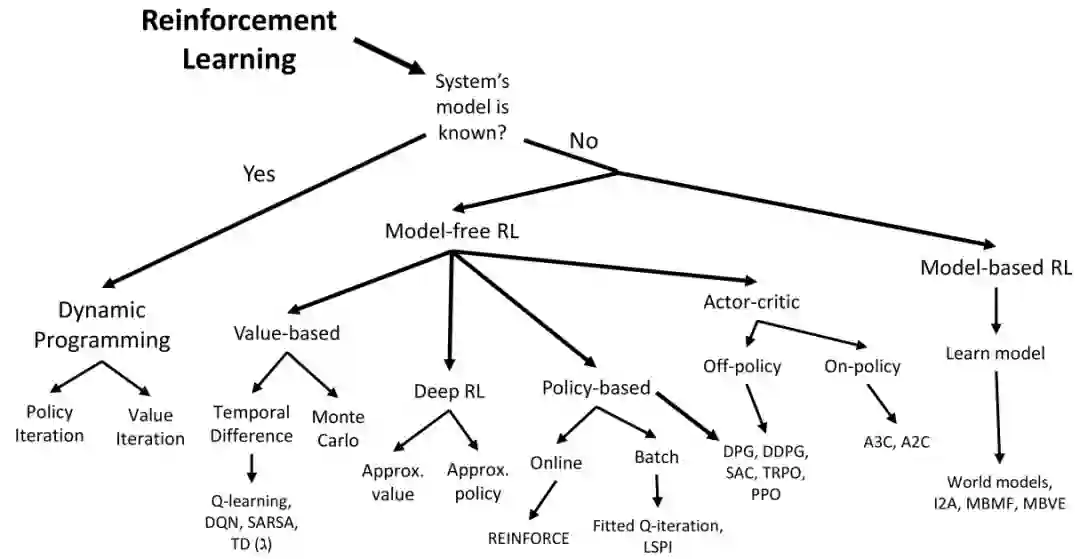
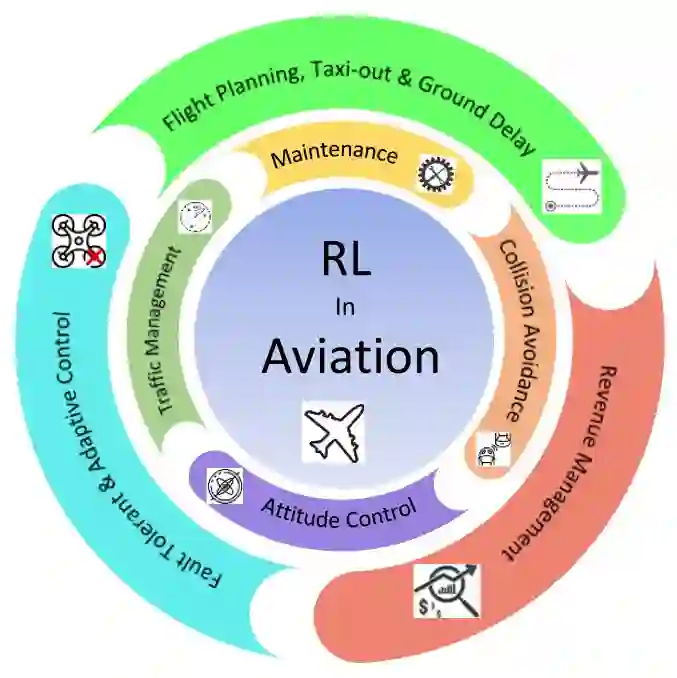
2 强化学习在航空中的应用
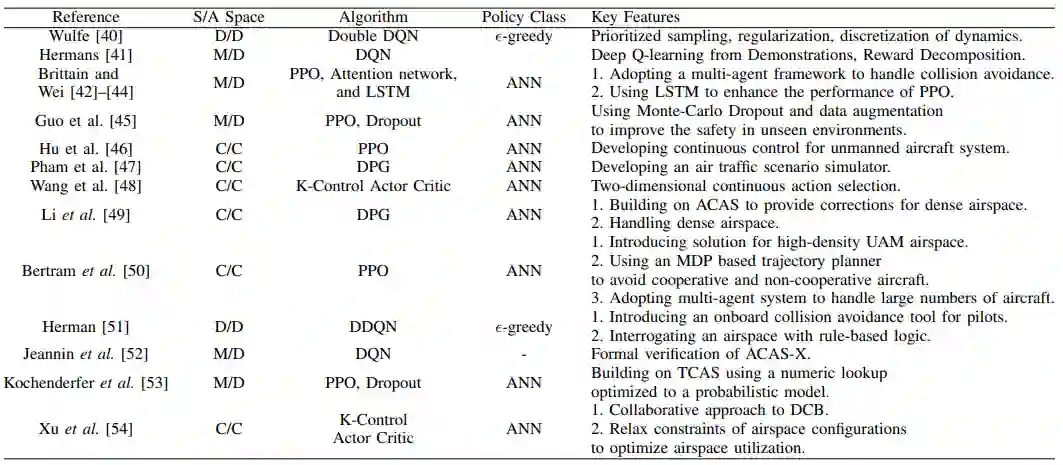
A 防撞和间距保证
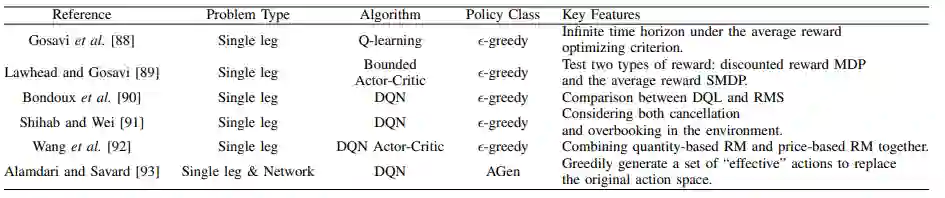
B 空中交通流量管理

D 飞机飞行与姿态控制
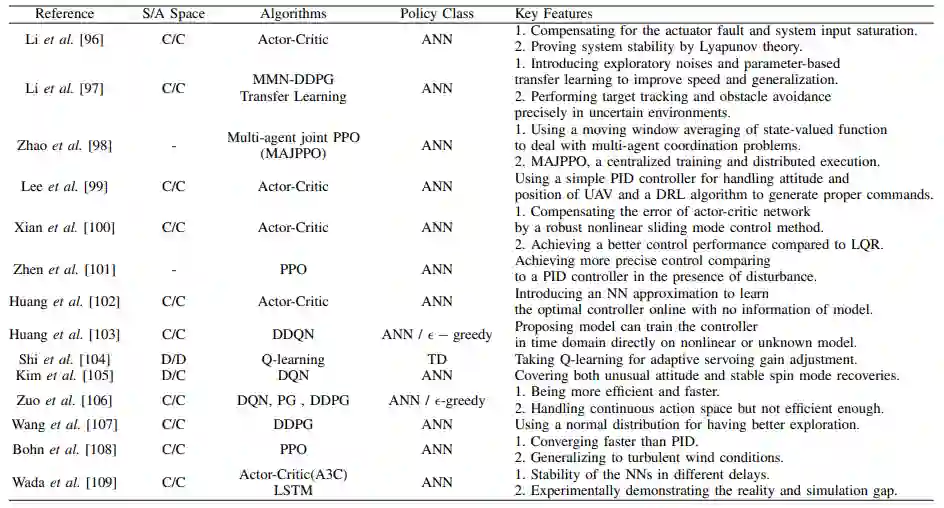
E 容错控制器

F 飞行规划
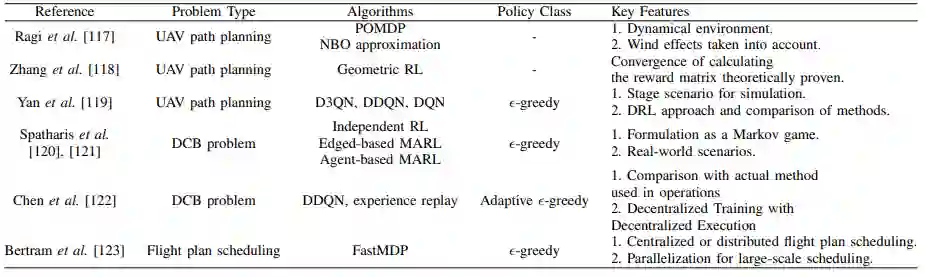
G 维护
H 强化学习的安全性和认证
便捷下载,请关注专知人工智能公众号(点击上方关注)
点击“发消息” 回复 “RLAA” 就可以获取《2022综述论文《强化学习在航空中的应用》第一份调查航空领域RL方法的研究论文,》专知下载链接



登录查看更多
相关内容
Arxiv
20+阅读 · 2020年3月10日


相关VIP内容
相关资讯
相关论文
Arxiv
20+阅读 · 2020年3月10日