【泡泡图灵智库】使用语义检测来增强人群场景的3D重建(CVPR37)
泡泡图灵智库,带你精读机器人顶级会议文章
标题:Augmenting Crowd-Sourced 3D Reconstructions using Semantic Detections
作者:True Price, Johannes L. Sch¨onberger, Zhen Wei, Marc Pollefeys, Jan-Michael Frahm
来源:CVPR2018
编译:黄文超
审核:刘小亮
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——使用语义检测来增强人群场景的3D重建,该文章发表于CVPR2018 。
用于互联网照片的基于图像的3D重建已经成为一项强大的技术,可以用来产生令人印象深刻的真实世界场景的虚拟表示。然而,运动恢复结构(SfM)仍存在几个重要挑战,即:仅在单个视图中观察到的瞬态物体的放置和重建,估计场景的绝对尺度以及恢复地面。本文的作者们提出了一种同时解决上述问题的方法。特别的是,算法实现了检测单张图像中的人体后将其准确地放入现有的3D模型中。作为此放置的一部分,该方法还根据对象语义(构成人群的身高分布)估计场景的绝对比例。此外还可以获得地面的平滑近似并直接从人体检测恢复场景的重力矢量。作者在众多无序的互联网照片上展示了该方法的结果,并且定量地评估了所获得的绝对的场景尺度。
简介
近年来,虚拟漫游系统变得流行起来,允许用户体验和探索他们没有到过的地方(如Google Earth VR)。这些应用使用了3D重建的方法来建立真实场景的模型。虚拟场景的感知体验固有地与重建结果的完整性有关,当前,地面重建和瞬态物体建模是大尺度场景重建的两大难点。由于相对少的地面匹配点,地面重建通常比较困难,而瞬态物体的放置比如移动的人和车无法用多视图同步也同样困难。此外,自动地恢复大场景的绝对尺度在缺少GPS信息的(室内或建筑密集等)情况下也存在问题。在本文中,作者致力于增强SfM + MVS的重建结果,尤其是从互联网图片集中重建3D场景,并且把从单张图片中检测到的人放置到场景中。图1展示了地面重建和3D场景中的人体放置。

图1 场景重建和人体放置示例
上图:稠密但不完整的3D重建;
下图:同样的场景但包含了地面和观测到的行人
算法流程

图2 本文提出的重建系统的流程图
首先,对某个场景的图片集使用SfM来获得相机参数和稀疏的结构,随后在图片中检测2D的人体躯干点,并且估计每个人相对相机的距离和旋转角以及全局的重力向量。接着对一系列重建场景的可能尺度做彻底的检验,进行排序并近似地语义三角测量。然后进行尺度的精调,用已知的人体身高统计信息和局部地面放置3D人体。最后,用泊松表面重建法恢复地面。为了可视化,放置到3D场景中的人体衣物颜色是从图像中采集的,同时地面的纹理也用图像和语义像素标记来渲染。
人体检测和重力方向估计
这一部分进行人体绝对位置和重力向量的同时优化。人体检测的方法是Convolutional Pose Machines,对于每个检测结果,拟合出一个以脖子点为中心的平面躯干模型(图3)

图3 脖子、肩膀、和髋关节的平面躯干模型。
最右图为平面模型的坐标系
通过最小化躯干模型到原始图像的重投影误差来同时优化重力向量g和每个人 i 的位姿Θ = {(θi, xi, yi, zi)}。如式(2)所示,其中 j 为检测到的关节m的2D像素坐标,J为3D关节坐标 π() 是投影函数,ρ是关节检测置信度。
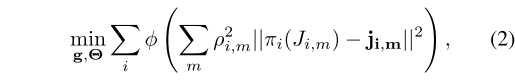
基于投票的尺度估计
此时已经获得了人相对相机的绝对深度的初始估计,接下来要估计每个躯干放置到重建空间中的初始位置,同时需要获得初始的场景绝对尺度。如果场景尺度已知,就可以用式(4)计算脖子在重建场景空间中的3D位置。其中N为脖子相对相机的3D位置,R为场景到相机的旋转矩阵,C为重建空间中相机的位置。
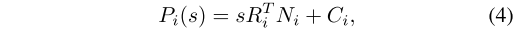
原则上,s可以用重建场景中两个点的绝对距离来决定。但是由于距离信息的缺乏,作者提出了利用近似的语义三角测量的方法来估计,并且用大量的图片对s进行投票评分。假设的尺度s由式(8)给出评分,其中M是二进制的表示符号,决定第 i 个人在尺度 s 上是否符合三角测量,ω为系数。作者在实验中发现令 ω 为图片中检测到的目标数的倒数时算法会有更好的性能。
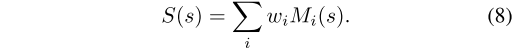
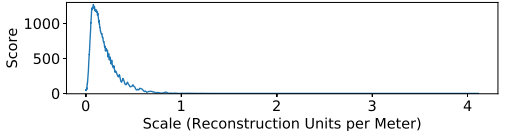
图4 尺度的统计得分曲线。峰值作为尺度的初始估计
尺度精调,高度估计和地平面估计
获得了尺度的初始估计 s 后,接下来需要同时优化这个尺度、每个人的高度 h 和对应于每个人站位的地平面法向量n。作为优化的一部分,作者还计算了每个人身体躯干的高度 t = βh,β是躯干到身体高度的比例。优化目标函数如式(14)所示,该式结合了:1)人体高度分布的先验信息 p(高斯混合模型);2)局部平面性质的先验信息 d,利用了两个相邻的人之间的地面是平滑的这一假设;3)可见性约束 v。
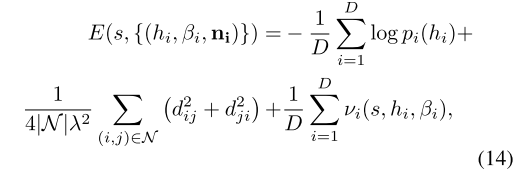
地面重建
有了优化的3D地面点和地面法向量,就可以使用泊松表面重建(Poisson Surface Reconstruction)拟合出地平面。
主要结果
本文作者在众多大规模图片集中测试了算法,包括著名的Cornell Arts Quad数据集。由于没有ground truth,在无序的互联网图片集中评估算法有一定难度。作者通过测量场景中建筑间的距离,手动建立了一个ground truth模型用于距离和尺度的估计。
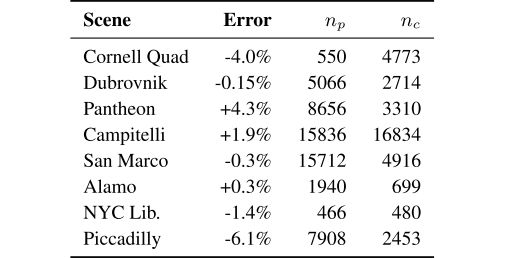
表1 距离估计结果
误差表示(超过/小于)%真实的单位距离
np 和 nc 分别表示人和摄影师的放置数量
同样的,由于没有可以获取的ground-truth来评估人体3D放置,作者从图片集中随机选择图片,定性地分析了放置的结果,四个大规模场景评估见图5。

图5 3D人体放置定性评估
左:顶视图,其中绿点表示人体放置位置,红点表示相机位置,黑点为静态建筑;
中:带有地面和人体替身渲染的模型输出;
右:真实图片示例

Abstract
Image-based 3D reconstruction for Internet photo collections has become a robust technology to produce impressive virtual representations of real-world scenes. However, several fundamental challenges remain for Structure-from-Motion (SfM) pipelines, namely: the placement and reconstruction of transient objects only observed in single views, estimating the absolute scale of the scene, and (suprisingly often) recovering ground surfaces in the scene. We propose a method to jointly address these remaining open problems of SfM. In particular, we focus on detecting people in individual images and accurately placing them into an existing 3D model. As part of this placement, our method also estimates the absolute scale of the scene from object semantics, which in this case constitutes the height distribution of the population. Further, we obtain a smooth approximation of the ground surface and recover the gravity vector of the scene directly from the individual person detections. We demonstrate the results of our approach on a number of unordered Internet photo collections, and we quantitatively evaluate the obtained absolute scene scales.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com




