作者 | 青 暮、陈大鑫
编辑 | 蒋宝尚
作为ACL和ISCA所属的关于对话系统的兴趣小组的年度会议,SIGDIAL 2020已经开幕。其中,清华COAI小组拿到了SIGDIAL2020最佳论文。
这篇论文的第一作者是清华大学研二学生高信龙一,论文的题目是《Is Your Goal-Oriented Dialog Model Performing Really Well? Empirical Analysis of System-wise Evaluation》。中文译为《你的目标导向型对话模式表现得很好吗?系统评价的实证分析》。
近年来,目标(任务)导向型对话系统引起许多研究者的关注。一个目标型对话系统可包括多个模块,例如一个传统的流水线模型包括语言理解、状态追踪、对话策略、语言生成四个模块,而各个模块均有大量的新算法和模型被提出。
然而,大部分工作忽视了去评价一个完整的对话系统的性能。这些新算法基本只在相应模块内进行比较验证,而没有评估该算法嵌入一个对话系统中的表现。根据细粒度和具体模型不同,各个模块和模型之间可以有多种拼接方式组成一个对话系统。
此外,模块内的评价基本只是在单论对话的设定下进行,而一个完整的对话应当由系统和用户进行多轮交互达成的。故在论文中,作者尝试比较了不同模块、不同细粒度、不同配置下各个目标导向型对话系统,以作系统级的性能评估。搭建完的对话系统通过与模拟用户或真实用户进行多轮对话交互,并使用对话级别的评价指标进行实验。
据清华大学黄民烈教授介绍到,论文的二作是同组的朱祺博士,此外还得到了微软合作者和朱老师的支持。。论文视频介绍☟
注:SIGDIAL为学术界和行业研究人员提供定期的论坛,介绍话语和对话领域的前沿研究。该会议由SIGdial组织赞助,该组织属于ACL和ISCA的话语和对话特别兴趣小组。具体来说,SIGDIAL接收正式的、基于语料库的、实现、实验或分析性工作,包括但不限于以下主题:话语处理、对话系统、语料库、工具、方法论、语用和/或语义建模、对话与话语处理技术的应用。
面向目标的智能对话系统通常需要多个回合的对话完成用户要求的复杂任务。
与开放域对话系统不同,面向目标的对话系统可以访问外部数据库,在该数据库上向复杂任务的用户查询信息。
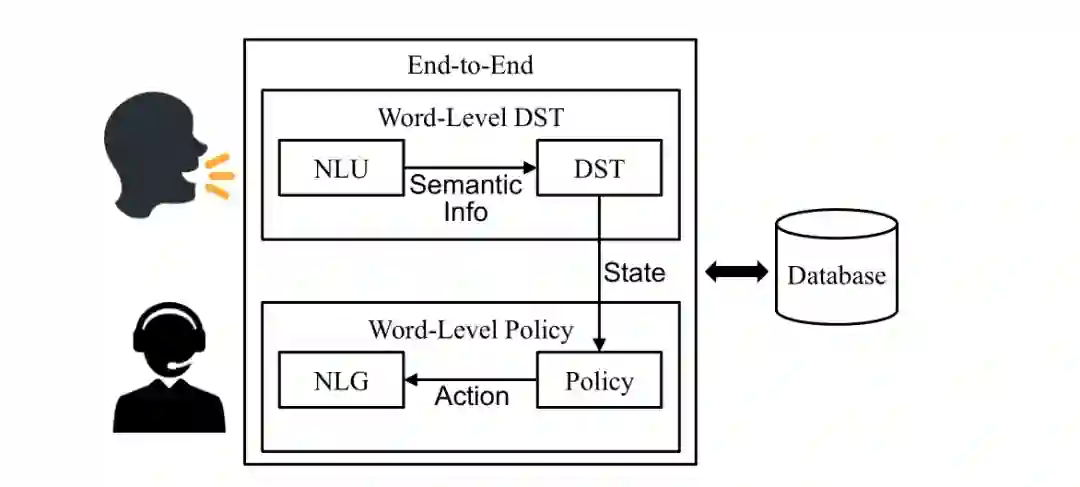
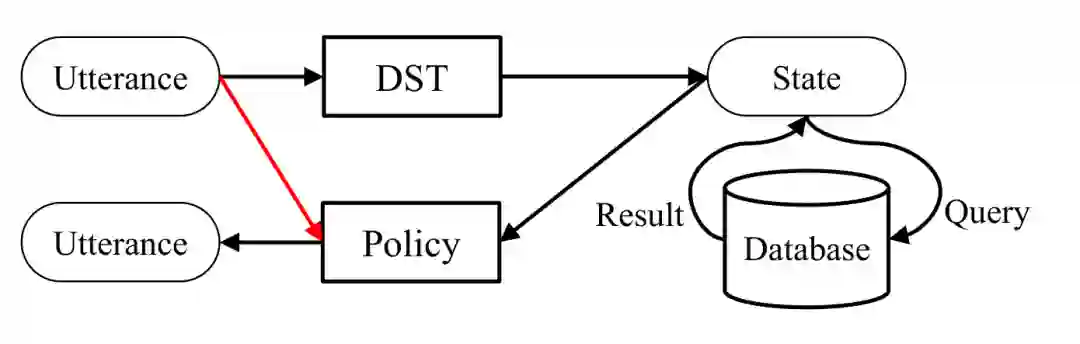
面向目标的对话系统可以分为三类,基于它们的体系结构,如下图所示。
第一类是pipeline(或模块化)系统,通常由四个部分组成:自然语言理解(NLU)、对话状态跟踪(DST)、对话策略(Policy)和自然语言生成(NLG)。
第二类是端到端(或统一)系统,直接从对话历史中生成系统响应。
第三类介于上述两种类型之间,有些系统使用结合了四种对话框组件中的某些(但不是全部)的运动类型模型。(例如,联合词级DST模型结合了NLU和DST,联合词级策略模型结合了对话策略和NLG。)
虽然人们设计了许多方法来评估和改进单个对话组件的性能,但是对于不同组件如何对对话系统的整体性能做出贡献,还缺乏全面的实证研究。
据论文介绍,作者进行了系统的评估,并对不同设置下由不同模块组成的不同类型的对话系统进行了实证分析。
(1)使用不同组件级别的细粒度监控信号训练
的pipeline对话系
统通常比使用粗粒度标签训练的联合或端到端模型的系统获得更好的性能。
(2)单轮、模块内的评估结果并不总是与多轮、系统级的整体性能一致。
(3)
尽管模拟用户和真实用户之间存在差异,但模拟评估仍然是昂贵的人工评估的有效替代,特别是在开发的早期阶段。
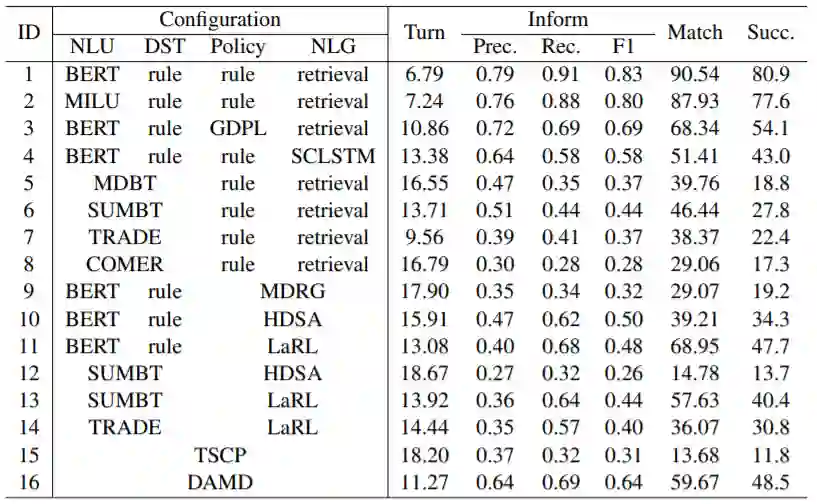
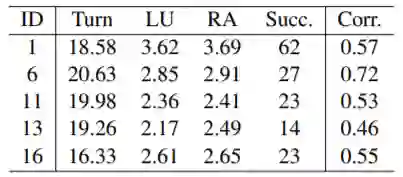
表1中的数据表明,与在联合模型和端到端系统相比,pipeline系统通常可以获得更好的总体性能,因为在组件级别使用细粒度标签可以帮助pipeline系统提高任务成功率。
表1:具有不同配置和模型的系统级仿真评估,这里使用SYSTEM-表示配置的缩写。
通过比较表1和表2中的结果表明验证组件评估是否与系统评估一致很重要。
可以观察到有时它们是一致的(例如表2a中的BERT> MILU,而SYSTEM-1> SYSTEM-2),但并非总是一致的(例如表中的TRADE> SUMBT 2b,但SYSTEM-6> SYSTEM-7)。
组件评估与系统评估之间有差异,使用检索模型系统的优越性可能意味着,在面向目标的对话系统中,NLG中较低的SER比较高的BLEU更为关键。
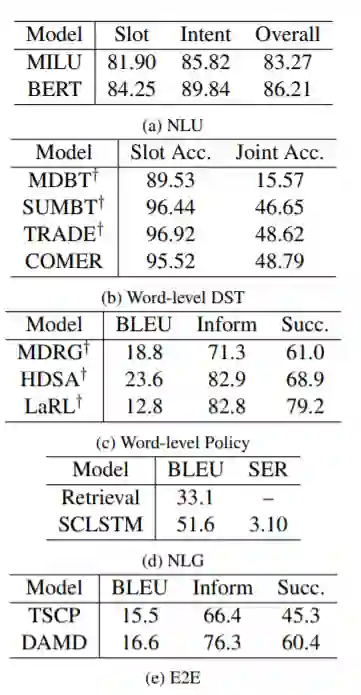
表2:每个模块的组件性能。†表示来自MultiWOZ排行榜的结果。其中,NLG为:自然语言生成模块从对话行为表示生成自然语言响应。E2E为:端到端模型将用户的话语作为输入,直接以自然语言输出系统响应。
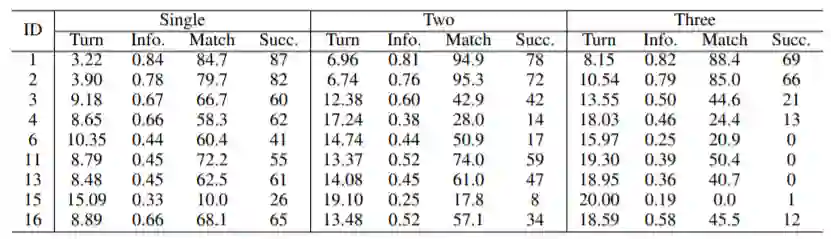
表3和表4中的结果表明,所有系统的整体性能随任务域的不同而变化,并且随着任务复杂度的增加而显着下降,而pipeline系统对任务复杂性则相对鲁棒。
表3:不同单域的性能。与“吸引力”相比,大多数系统在“餐厅”和“火车”中的性能更高。
表4:不同域数下的性能。随着域数的增加,所有系统的性能都会下降。
表5显示了5个对话系统的人工评估结果。与表1中的模拟评估相比,可以看到大多数系统的Pearson相关系数都在0.5到0.6之间,这表明模拟评估与人类评估的相关性中等。
表5:对人类用户的系统评估,最后一列展示了模拟评估与人工评估之间的相关系数。
表6显示了模拟评估中SYSTEM-1和SYSTEM-6之间的会话比较。
表7表明现有的对话系统容易受到人类语言变化的影响,例如表7中棕色突出显示的句子,这表明在处理真实的人类对话时缺乏稳健性。
需要明确的是,作者在论文中用的评价指标有两个:任务效率:使用对话的次数,平均所有对话会话,来衡量完成一项任务的效率。用户话语和随后的系统话语被视为一个对话回合。系统应帮助每个用户在20轮内完成目标,否则视为失败。
任务成功率:用Inform F1和匹配率衡量,其中informf1评估所有信息请求是否得到满足,匹配率评估所提供的实体是否满足用户目标中指定的所有约束。当且仅当Inform F1和匹配率均为1时,对话框才会标记为成功。
此外,还有一些其他结果:词级DST预测的对话状态只记录当前回合的用户约束,导致动作选择(通过对话策略)的信息丢失,如下图所示。
词级DST与字级策略相结合可以获得更好的整体性能,例如SYSTEM-13的成功率为40.4%,而SYSTEM-6的成功率为27.8%,如下图所示。
所有这些联合方法在传统的pipeline系统中仍然表现不佳,而通过联合训练策略和NLG模块可以改善响应生成:在使用联合模型的所有系统中,SYSTEM-16获得了最高的成功率(48.5%)和第二高的匹配率(59.67%)(SYSTEM-5∼14)。
这篇论文的第一作者高信龙一,原来是清华大学计算机系计55班。在大二的时候,也就是2016年10月份进入智能技术与系统国家重点实验室交互式人工智能(CoAI)课题组,在黄民烈老师的指导下进行科研训练。
主要研究方向为对话系统、推荐系统和强化学习。目前已在ACL,EMNLP,WWW,AAAI等顶级会议上以第一作者发表数篇长文。
高信同学进大学前专注于数学竞赛,没有丝毫计算机编程方面的基础,在清华读本科期间,一开始也是跟随实验室的冯珺学姐从事一些简单的科研工作,主要做一些baseline的实现和分析。在学姐和老师的辅助下,一点点掌握科学实验和结果分析等独立科研能力。
大三的时候,高信龙一由于人工神经网络课程和其他两名本科生一起合作完成了一个项目,在里面又体会到了团队合作时的一些心得,例如如何沟通、如何分配工作和时间。
他的科研经历也并不是一帆风顺,据高信龙一回忆:他为了完成第一个项目,整个暑假都和同学一起泡在实验室里,期间在实验上有过无数的尝试和修正,从一次次失败中分析其中的原因,汲取其中的经验。
2019年,他成为清华大学计算机系硕士生,交互式人工智能组(CoAI)成员,算是正式“拜师”黄民烈教授。
所以,高信龙一算是“土生土长”清华学子,但从过往经历,可以看到,清华学子的科研路也是一步一步走出来的,例如他从大二就动了科研的念头,大三组织团队完成科研任务,再到2019年攻读硕士,以及今天的这篇最佳论文。高信龙一同学的科研路可谓踏踏实实,一步一个脚印。
1.这次获得最佳论文,你心情如何?有没有什么研究建议想给大家分享的?
答:挺开心的,很荣幸自己的工作能得到学界的认可,很感谢身边的老师、同学和同事给我的支持。我希望现在人工智能方向的研究者能静下心来研究一些真正有意义、有深度的课题。
2.获奖的这篇论文思路是什么样的?主要解决了什么问题?
答:随着近年来人工智能新模型和新算法层出不穷,我希望能让学界重新重视一下对话评价的问题,思考一下对话模型的实用性。
本次工作针对各类模型、各类配置、各类设定的多轮任务型对话系统进行全面的系统评测和分析,为对话系统的研究者和开发者提供了一些重要的借鉴。
答:可能更加关注于每个模块内的性能提升。例如在任务型对话中,对话状态追踪就是一个比较热门的方向。
一开始并没有明确的方向,所以先从算法入手,着眼到了强化学习上。后来随着对组里的研究方向有了进一步了解之后,对对话这种人机交互的形式比较有兴趣,同时也有一些场景可以利用到强化学习,所以选择了对话系统这个领域,其中我个人相对专攻任务型对话系统。
更多的把精力放到科研上了。平时要注意对文献的阅读积累,带着问题去阅读一些论文。
6.清华的培养机制,对你来说受益最大的是哪一方面?
可能是多元化的校园生活。只要用心,每个人都能在清华找到适合自己的环境。像是对科研感兴趣的同学,大二的时候就可以借助计算机系里的“学术新星”计划,提前进入实验室接触科研方面的知识。此外,和实验室的教师和同学的学术探讨也给我提供了很大的帮助。
听听音乐,看看植物,和家人或好朋友聊聊天,其他基本就是在闭目养神了(笑)。
8.黄民烈老师说,这篇文章有微软合作者的支持,请问毕业之后是打算去微软么?
原本微软研究院邀请我在今年春季过去参加实习的,但由于全球疫情爆发之后,没能去成西雅图那边,所以现在还没有确定毕业之后的去向。
![]()
ACL 2020原定于2020年7月5日至10日在美国华盛顿西雅图举行,因新冠肺炎疫情改为线上会议。为促进学术交流,方便国内师生提早了解自然语言处理(NLP)前沿研究,AI 科技评论将推出「ACL 实验室系列论文解读」内容,同时欢迎更多实验室参与分享,敬请期待!
点击"阅读原文",直达“ACL 交流小组”了解更多会议信息。