基于深度学习的人脑视觉神经信息编解码研究进展及挑战【附PPT】

关注文章公众号
回复"杜长德"获取PPT资料
引言
现实世界中,外部视觉刺激是多种多样、杂乱无章的,而人类的视觉系统,从视网膜到高级视觉皮层的各个认知阶段,却能以某种方式稳定地识别和理解这些视觉输入数据。人脑在复杂视觉信息处理方面具有计算机所无法比拟的高效性、鲁棒性。视觉信息编码是指人脑将外部视觉刺激转换成神经活动信号的过程,解码是指根据观测到的脑信号模式预测对应的外部视觉刺激的过程。研究人脑视觉神经信息编解码,开发类似人脑的视觉信息处理模型,对于提高机器的智能感知能力具有重要意义。本报告讲解视觉神经信息编解码研究背景,国内外已取得的成果,并重点围绕深度学习来讲解视觉神经信息编解码研究进展以及该领域面临的挑战。
作者简介
杜长德,中科院自动化所类脑智能研究中心在读博士,目前主要研究统计机器学习、深度学习及人脑视觉神经信息处理模型。目前其已发表多篇学术论文, 如IEEE TNNLS、 ACMMM、 IJCAI、 SIGKDD、ECML、UAI 等,并曾获得博士生国家奖学金。其关于人脑视觉信息解码的研究工作曾被《MITTechnology Review》、《中国科学院》报道。

杜长德
相关工作
目前国际上已经有很多视觉信息解码方面的研究,涵盖了对初级视觉特征(方向、对比度、颜色)、中级视觉特征(轮廓、深度信息)以及高级视觉特征(对象、语义)的分类、辨识或重建。早在2001 年,Haxby 等人[1]就利用多体素模式分析(Multi-Voxel Pattern Analysis, MVPA)方法成功实现了根据fMRI 信号对呈现给被试者的六个不同类别的图像进行分类。2005 年,Kamitani 等人[2] 将不同方向的条纹作为视觉刺激,根据fMRI 信号实现了对不同条纹刺激的分类,也证明了在初级视觉区域含有外界图像刺激的信息。2006 年,Thirion 等人[3] 的研究进一步表明可以利用大脑视觉区域的信号重建出被试实际观察到的图像,不过该研究只使用了初级视觉区域的信号,重建精度有待提高。2008 年,Miyawaki 等人[4] 以二值几何图像作为视觉刺激,利用fMRI 信号和MVPA 方法成功重建出了视觉刺激内容。同年,Kay 等人[5] 利用 Gabor 小波金字塔模型(Gabor Wavelet Pyramid)建立了从视觉图像到大脑响应的感受野模型(Receptive-field Model),并根据新的 fMRI 数据,成功辨识出了被试看到的图像。2009年,Naselaris等人[6]在Gabor 小波金字塔模型中加入了基于贝叶斯方法的语义编码模型,从而使得识别出的图片不仅在结构上相似,而且在语义上也极其相似。
该领域面临的问题及挑战
尽管现有的视觉信息解码模型在对大脑信号的分类、识别任务上表现良好,但是试图通过大脑视觉皮层信号精确重建视觉刺激内容仍然非常困难。阻碍人们有效地进行视觉信息解码的因素主要包括 fMRI 数据维度高、样本量小、噪声严重、解码模型不科学等。传统的基于多体素模式分析的视觉信息解码方法直接在高维的 fMRI 体素空间和视觉图像像素空间建立映射关系,这种解码方法很容易造成对冗余或噪声体素的过拟合。此外,现有的视觉信息解码方法大多数基于对视觉图像的线性变换,没有结合人脑视觉系统的信息处理机制,解码效果差并且缺乏生物学基础。
基于深度学习的解码研究
近期,多项fMRI研究已经表明深度神经网络在视觉信息处理方面与人类大脑的视觉处理过程具有类似的表现。深度神经网络的浅层单元与人脑初级视觉区域的神经元在功能上具有很强的一致性,而深度神经网络的深层单元和人脑高级视觉区域的神经元表现也极其相似。正是因为借鉴了大脑的视觉处理机制,人工神经网络才表现出与人脑类似的感知和学习能力。针对视觉信息解码技术中的视觉图像特征提取、fMRI 体素选择、体素噪声抑制、视觉图像重建等问题,中科院自动化所类脑智能研究中心何晖光研究团队提出了一种新的基于贝叶斯深度多视图学习的视觉信息编解码框架(图1)其概率图模型如图2所示。具体地,针对传统视觉信息编码方法在图像特征提取方面的不足,结合大脑视觉信息处理机制和贝叶斯深度学习的特点,作者提出利用深度变分自编码器(Variational Auto-Encoders, VAE)从原始图像刺激中逐层提取可解释性强的视觉特征,并在视觉信息解码实验中验证了该方法的优越性。采用基于VAE架构的深度生成式模型(Deep Generative Model, DGM)可以自动地从输入图像中学习到多种可解释的隐含表示,如描述物体的空间位置、尺寸大小、旋转角度等信息,这和人类视觉系统具有一定的相似性,对建立类脑智能视觉模型非常重要。受人脑视觉通路中存在的 Bottom-up和Top-down机制的启发,他们设计了一种基于变分贝叶斯推断的高效模型求解方法。相关论文[7]已在神经网络及机器学习领域的国际权威期刊IEEE Transactions on Neural Networks andLearning Systems(TNNLS, IF=7.982)在线发表。
论文下载:https://ieeexplore.ieee.org/document/8574054,
代码下载:https://github.com/ChangdeDu/DGMM。
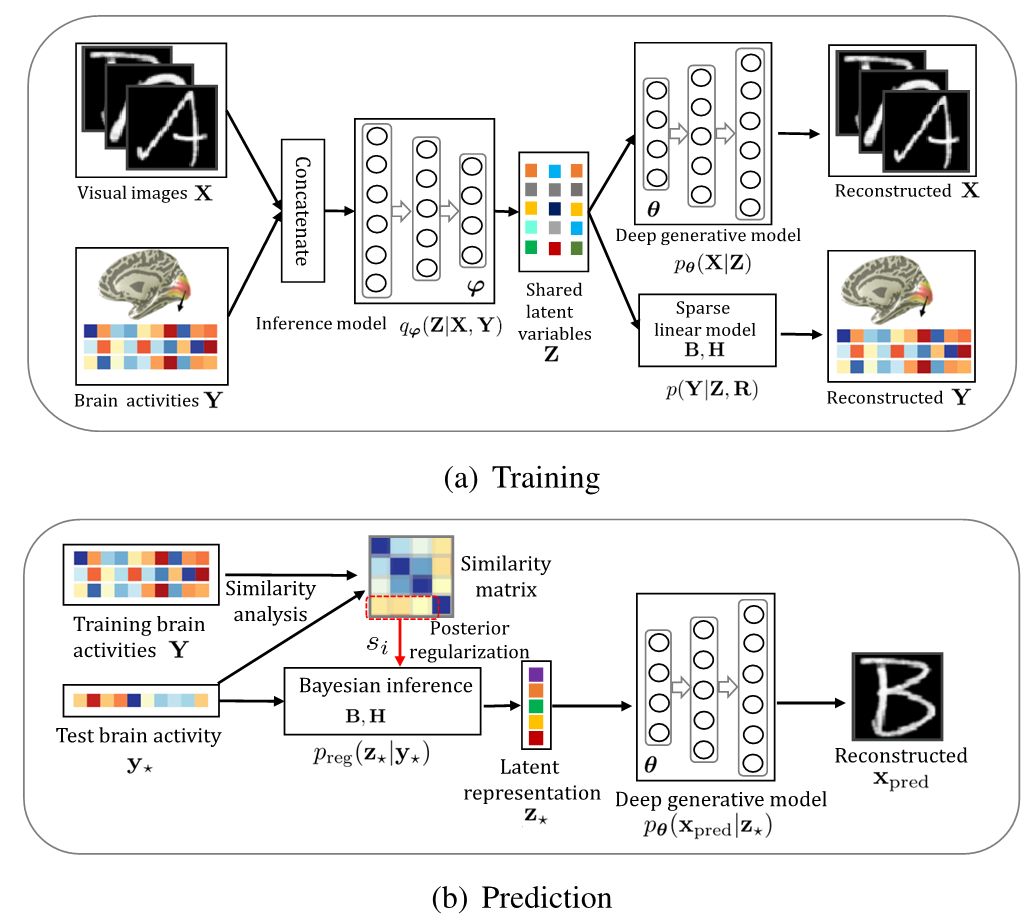
图1 基于贝叶斯深度多视图学习的视觉信息编解码框架
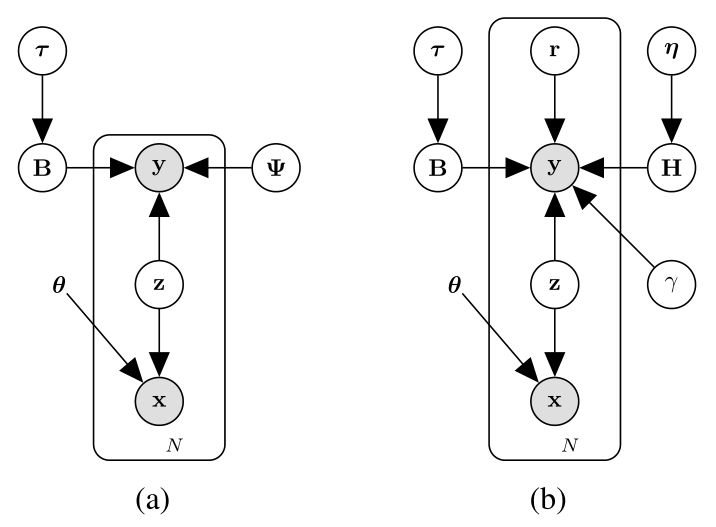
图2 深度生成式多视图模型
参考文献
[1] J. V. Haxby, M. I. Gobbini, M. L.Furey, A. Ishai, J. L. Schouten, P. Pietrini, Distributed and overlappingrepresentations of faces and objects in ventral temporal cortex, Science 293(5539) (2001) 2425–2430.
[2] Y. Kamitani, F. Tong, Decoding thevisual and subjective contents of the human brain, Nature neuroscience 8 (5)(2005) 679–685.
[3] J.-D. Haynes, G. Rees, Decoding mentalstates from brain activity in humans, Nature Reviews Neuroscience 7 (7) (2006)523–534.
[4] Y. Miyawaki, H. Uchida, O. Yamashita, M.-a.Sato, Y. Morito, H. C. Tanabe, N. Sadato, Y. Kamitani, Visual imagereconstruction from human brain activity using a combination of multiscalelocal image decoders, Neuron 60 (5) (2008) 915–929.
[5] K. N. Kay, T. Naselaris, R. J. Prenger,J. L. Gallant, Identifying natural images from human brain activity, Nature 452(7185) (2008) 352–355.
[6] T. Naselaris, R. J. Prenger, K. N. Kay,M. Oliver, J. L. Gallant, Bayesian reconstruction of natural images from humanbrain activity, Neuron 63 (6) (2009) 902–915.
[7] C. Du, C. Du, L. Huang, H. He, ReconstructingPerceived Images from Human Brain Activities with Bayesian Deep Multi-viewLearning, IEEE Transactions on Neural Networks and Learning Systems, 2018.
SFFAI招募召集人!
Student Forums on Frontiers of Artificial Intelligence,简称SFFAI。
现代科学技术高度社会化,在科学理论与技术方法上更加趋向综合与统一,为了满足人工智能不同领域研究者相互交流、彼此启发的需求,我们发起了SFFAI这个公益活动。SFFAI每周举行一期线下活动,邀请一线科研人员分享、讨论人工智能各个领域的前沿思想和最新成果,使专注于各个细分领域的研究者开拓视野、触类旁通。
SFFAI自2018年9月16日举办第一期线下交流,每周一期,风雨无阻,截至目前已举办18期线下交流活动,共有34位讲者分享了他们的真知灼见,来自100多家单位的同学参与了现场交流,通过线上推文、网络直播等形式,50000+人次参与了SFFAI的活动。SFFAI已经成为人工智能学生交流的第一品牌,有一群志同道合的研究生Core-Member伙伴,有一批乐于分享的SPEAKER伙伴,还有许多认可活动价值、多次报名参加现场交流的观众。
2019年春季学期开始,SFFAI会继续在每周日举行一期主题论坛,我们邀请你一起来组织SFFAI主题论坛,加入SFFAI召集人团队。每个召集人负责1-2期SFFAI主题论坛的组织筹划,我们有一个SFFAI-CORE团队来支持你。一个人付出力所能及,创造一个一己之力不可及的自由丰盛。你带着你的思想,带着你的个性,来组织你感兴趣的SFFAI主题论坛。
当召集人有什么好处?
谁可以当召集人?
怎样才能成为召集人?
为什么要当召集人?
了解我们,加入我们,请点击下方海报!


历史文章推荐:
芯片行业都难在哪儿?这篇说得最详细!
陶哲轩对数学学习的一些 建议
448页伊利诺伊大学《算法》图书【附PDF资料】
一文看尽2018全年计算机视觉大突破
从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
SFFAI分享 | 曹杰:Rotating is Believing
SFFAI分享 | 黄怀波 :自省变分自编码器理论及其在图像生成上的应用
AI综述专栏 | 深度神经网络加速与压缩
若您觉得此篇推文不错,麻烦点点好看↓↓




