英伟达肖像动画新模型SPACEx发布,三步就让照片里的人「活」过来!

新智元报道
新智元报道
【新智元导读】如何仅凭一张图像,就让照片里的人物活过来?英伟达肖像动画新模型SPACEx带你体验。
其中一项棘手的任务,就是从单个肖像自动生成逼真的动画。
这个任务十分复杂,一直是计算机视觉领域的一个悬而未决的问题。
而最近,英伟达团队攻克了这一难题,以巧妙的方式,使用语音和2D单个图像,就可以为人像制作逼真的动画了。

论文链接:https://arxiv.org/pdf/2211.09809.pdf
克服以往的弊端
它采用多阶段方法,将面部特征点的可控性和预训练面部生成器的高质量合成能力相结合。
另外,SPACEx还允许控制情绪和强度。在图像质量和面部运动的客观指标上,它都优于先前的方法。
从下面的两个视频中,可以看出,SPACEx对于人像的语音驱动动画,可控制输出姿势、情绪和表情强度。


在以往,图像生成动画领域最近的工作都是利用语音信号来驱动动画过程,这个过程需要学习如何将输入语音映射到面部表征。
而理想的生成视频,应该与音频具有良好的口型同步、自然的面部表情和头部动作,以及高帧质量。
在以往,图像生成动画领域的SOTA模型,依赖于由预处理网络组成的端到端深度神经网络架构。

这些网络可以将输入的音频序列转换为可使用的token,以及学习到的情感嵌入,以将这些token映射到相应的姿势。
但是,这些方法需要特殊的训练数据,例如3D面部模型,而这些数据,可能不适用于许多应用程序。
然而,当与单个输入图像一起使用时,嘴唇动作的结果会缺乏真实感,因为脸部的其余部分会保持静止,效果就很诡异。
因此,英伟达团队推出SPACEx。
他们的目标是,以巧妙的方式使用2D单个图像,以克服上述SOTA的局限性,同时获得逼真的结果。
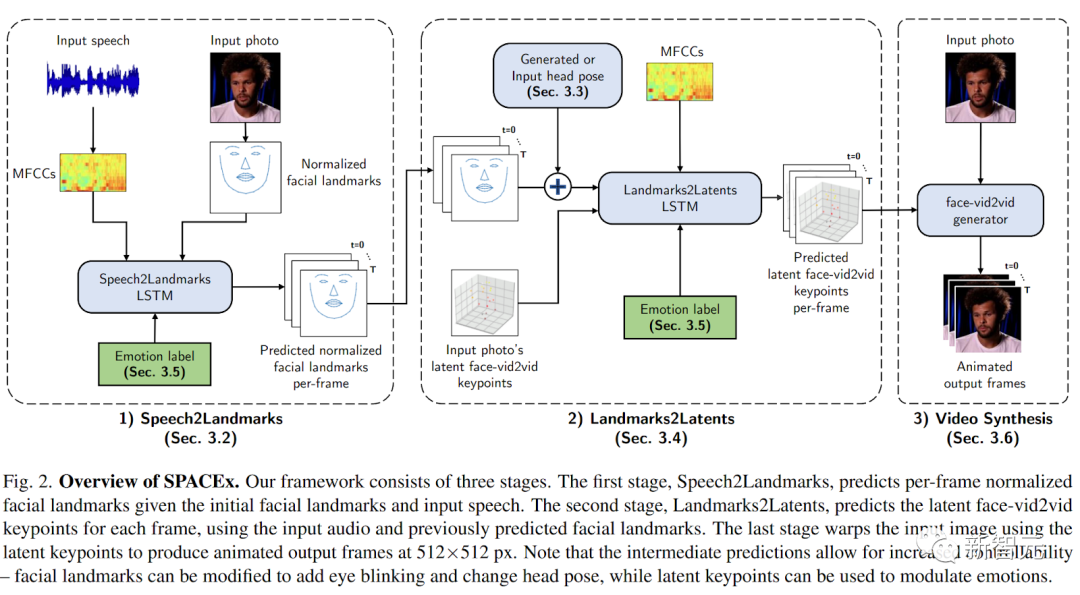
三个步骤
它使用了一个三阶段的预测框架。
第一步,语音-特征点(Speech2Landmarks)。
给定输入图像,提取归一化的3DDFA和MTCNN面部特征点(上图中的Speech2Landmarks)。
根据输入的语音和情感标签,神经网络会使用计算出来的特征点,预测每帧的动作。但输入的语音并不会直接喂到特征点预测器。
使用1024个样本的FFT(快速傅里叶变换)窗口大小,以30帧/秒的速度从其中提取出40个梅尔频率倒谱系数 (MFCC)。
第二步,特征点-潜在关键点(Landmarks2Latents)。
此步骤将每帧面部特征点译成潜在关键点(上图中的 Landmarks2Latents),供Face-Vid2Vid使用。这是一个预先训练的基于图像的面部动画模型。
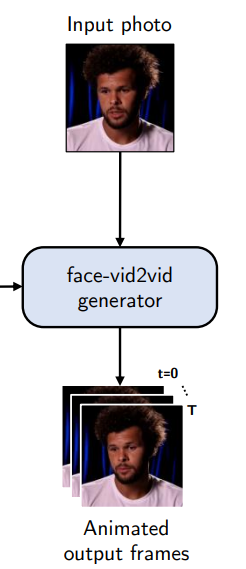
第三步,视频合成。
给定输入图像和上一步中预测的每帧潜在关键点,face-vid2vid生成器(一种基于图像的预训练面部动画模型)输出 512×512像素帧的动画视频。
分成这三个阶段的方法,有很多优点。
首先,它允许对输出面部表情(比如眨眼或特殊的头部姿势)进行细粒度控制。例如,可以修改面部特征点,以引入眨眼或其他头部姿势,来输入特定的姿势或预测姿势。
此外,可以使用情绪标签调制潜在关键点,以改变表情强度或控制注视方向。
通过利用预训练的人脸生成器,我们可以获得高质量的输出视频,同时训练成本大大降低。
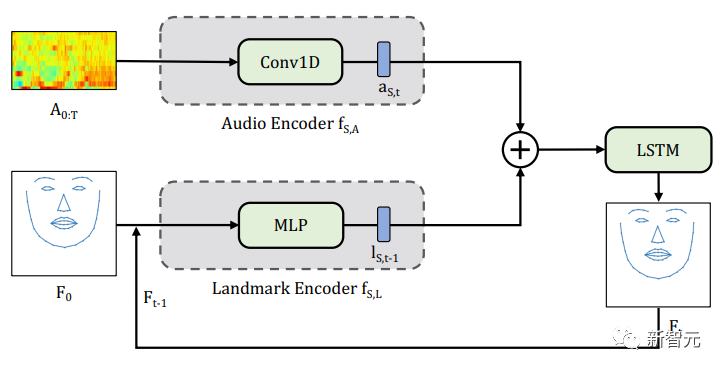
S2L:预测归一化面部特征点

团队使用CNN和MLP对音频和面部特征进行编码
从第二列到最后一列对应的视频分别如下:
通过L1损失网络和归一化面部特征点的基准真相来训练S2L模型,加大对垂直运动误差的惩罚。
团队表示,在归一化空间中进行预测,对于简化音素和嘴唇运动之间的映射非常重要。
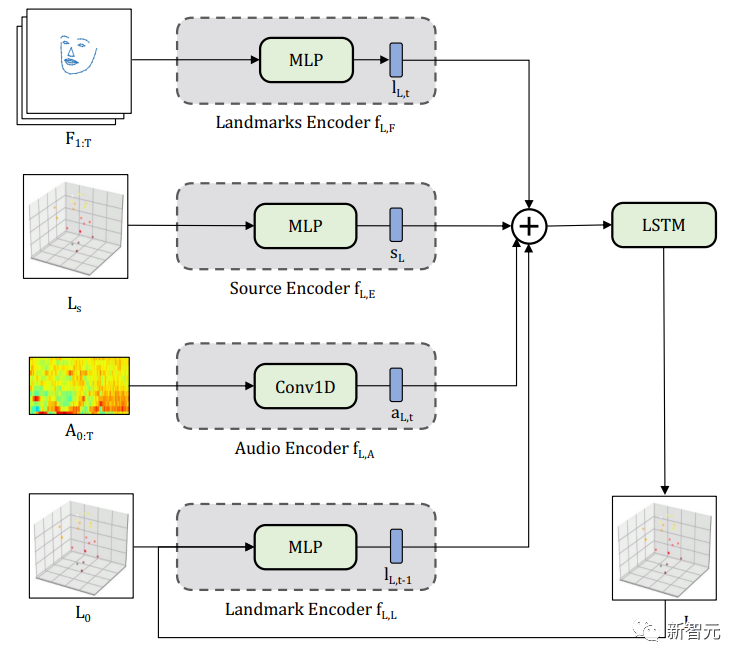
Face-vid2vid对每个输入帧预测20个潜在关键点。基于输入的源图像和当前视频帧的潜在关键点,face-vid2vid预测基于流的图像扭曲。
通过将图像扭曲应用到源图像特征,该模型可以将源图像的肖像特征应用于新生成的视频中。
研究团队使用FiLM层,根据视频帧的情感调节Speech2Landmark和Landmark2Latent模型 。
对于S2L网络,使用FiLM来调制音频特征和初始特征点输入。对于L2L,研究人员将FiLM应用于音频、特征点和初始潜在关键点输入。
在训练中,当数据集提供时,就使用单热情绪标签(one-hot emotion labels),当地面真实情绪(ground-truth emotions)不可用时,就使用预测的每帧情绪概率分布。
在推理时,我们可以提供所需的情感标签组合及其强度作为输入,如下一部分的动图所示。
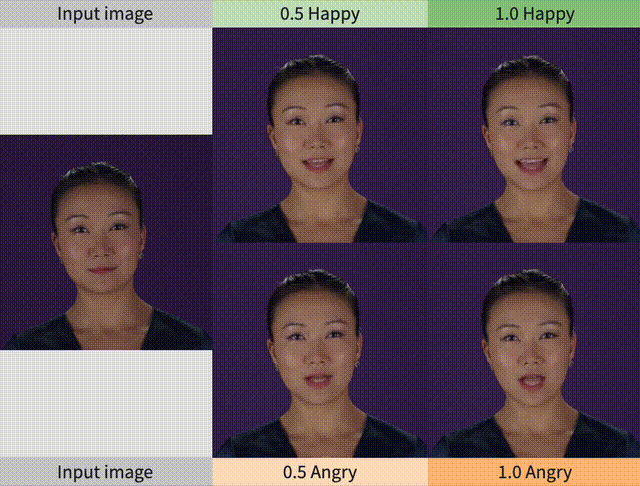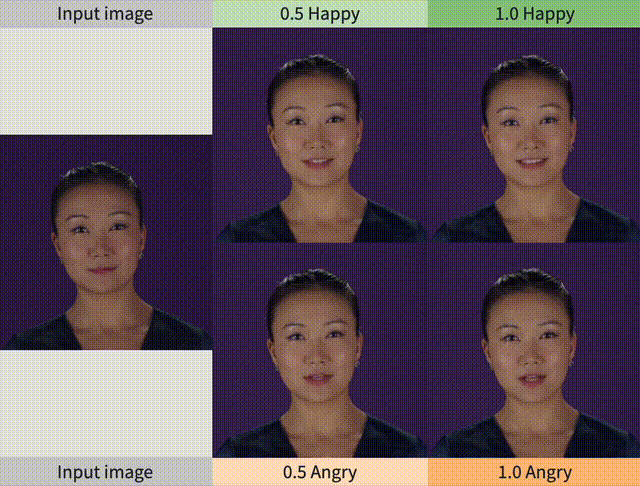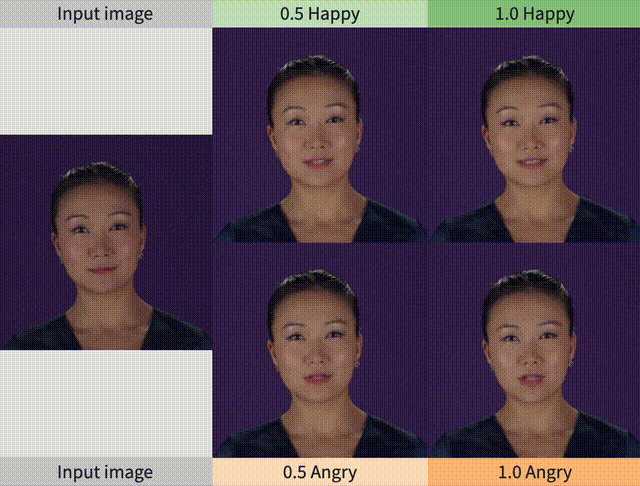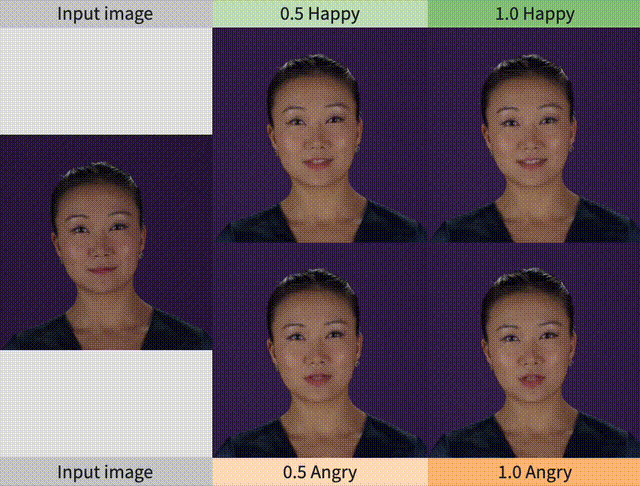
第2列和第3列对应的视频如下
英伟达团队表示,使用面部特征点作为中间表示利于视频生成,因为其允许面部特征的显式操作。例如,通过操纵眼部特征点来添加眨眼等动作。

基于生成的说话人视频,研究团队首先使用3DDFA特征识别模型,提取视频每帧68个3D面部特征点和头部姿势。
随后,研究团队使用预测的头部姿势,将3D面部特征转正,并正交投影到 2D平面上。
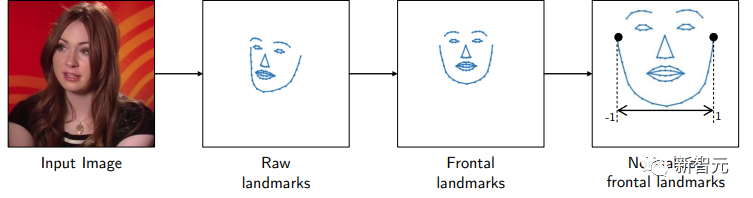
同时,研究团队将每个帧归一化,例如固定两个耳朵之间的距离。
为获得精准眼部特征点,研究团队使用MTCNN模型,捕捉52个眼部特征,用以生成视频中人像的眼部动作,例如眨眼和凝视。
除了面部特征点,团队还使用face-vid2vid提取每帧的潜在关键点。给出每帧的(面部特征点、潜在关键点)对。
音频方面,团队使用1024个样本的FFT(快速傅里叶变换)窗口大小,以30帧/秒的速度从其中提取出40个梅尔频率倒谱系数 (MFCC),以便将音频特征与视频帧对齐。
同时,还使用音高转换、均衡、响度变化等方法来处理音频数据。
比以前强在哪?直接看图
而英伟达的SPACEx是在归一化的特征点空间中预测嘴部运动,应用姿势转换,就能够处理更多的脸部图像姿势。
另外,SPACEx还能生成缺失的细节,比如牙齿。而其他方法要么会失败,要么会引入伪影。
当音频中有呼吸声时,SPACEx甚至还可以增加真实的头部和肩部动作。
与之前的工作相比,SPACEx的唇部运动也更加平滑,不会像之前的工作那样,产生夸张和生硬的运动。
可以说,其他的工作中,没有像SPACEx这样,对输出的视频有如此大的可控性。
让我们来看看对比——
输出视频采用的方法,从左到右依次是:PC-AVS、MakeItTalk、Wav2Lip和SPACEx。





-
PC-AVS是对输入的图像严丝合缝地裁剪,并且改变输入姿势,脸部动作相当生硬。 -
MakeItTalk的唇部动作较差,而且在输出的视频中引入了伪影。在最下面的两段视频中,有白色斑块状的伪影。 -
Wav2Lip的设计考虑到了配音的问题。但它移动了嘴唇,而脸部的其他部分保持静止,产生的输出非常不真实。 -
而最后一栏的SPACEx,解决了上面的所有问题。它能处理大量的输入姿势,产生逼真的嘴唇动作,和高质量的输出。





