函数分布视角下的神经过程
编者按:几个月前,Deepmind在ICML上发表了一篇论文《Neural Processes》,提出了一种兼具神经网络高效性和高斯过程灵活性的方法——神经过程,被称为是高斯过程的深度学习版本。虽然倍受关注,但目前真正能直观解读神经过程的文章并不多,今天论智带来的是牛津大学在读PHD Kaspar Märtens的一篇可视化佳作。
在今年的ICML上,研究人员提出了不少有趣的工作,其中神经过程(NPs)引起了许多人的注意,它基于神经网络概率模型,但又可以表示随机过程的分布。这意味着NPs结合了两个领域的元素:
深度学习:神经网络是灵活的非线性函数,可以直接训练
高斯过程:GP提供了一个概率框架,可用于学习非线性函数的分布
两者都有各自的优点和缺点。当数据量有限时,由于本身具备概率性质可以描述不确定性,GP是首选(这和非贝叶斯神经网络不同,后者只能捕捉单个函数,而不是函数分布);而当有大量数据时,训练神经网络比GP推断更具扩展性,因此优势更大。
神经过程的目标就是实现神经网络和GP的优势融合。
什么是神经过程?
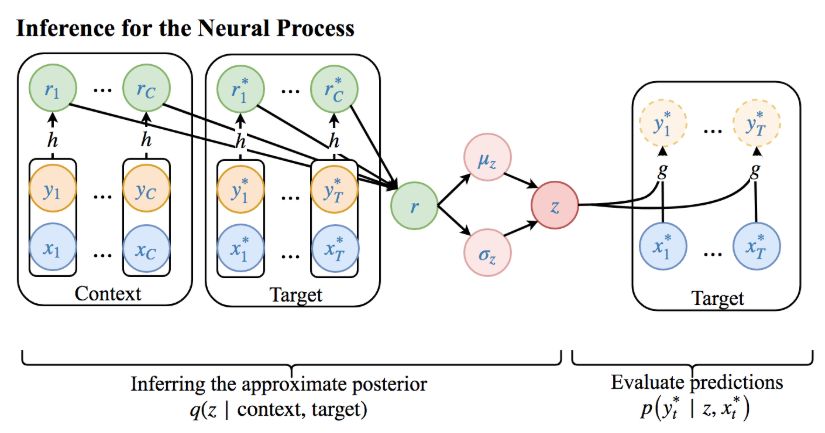
NP是一种基于神经网络的方法,用于表示函数的分布。下图展示了如何建立NP模型,以及训练模型背后的一般想法:
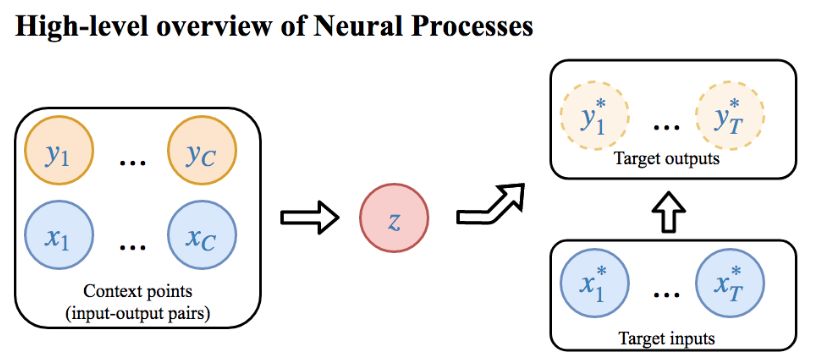
给定一系列观察值(xi,yi),把它们分成“context points”和“target points”两组。现在,我们要根据“context points”中已知的输入输出对(xc,yc),其中c=1,…,C,和“target points”中的未知输入x∗t,其中t=1,…,T,预测其相应的函数值y∗t。
我们可以把NP看作是根据“context points”中的“target points”建模的模型,相关信息通过潜在空间z从左侧流向右侧,从而提供新的预测。右侧本质上是从x映射到y的有限维嵌入,而z是个随机变量,这就使NP成了概率模型,能捕捉函数的不确定性。一旦模型完成训练,我们就可以用z的近似后验分布作为测试时进行预测的先验。
乍看之下,这种分“context points”和“target points”的做法有点类似把数据集分成训练集和测试集,但事实并非如此,因为“target points”集也是直接参与NP模型训练的——这意味着模型的(概率)损失函数在这个集上有明确意义。这样做也有助于防止模型过拟合和提供更好的泛化性。在实践中,我们还需要反复把训练数据通过随机采样分为“context points”中的“target points”,以获得更全面的概括。
让我们来思考以下两种情况:
基于单个数据集推断函数的分布
当存在多个数据集且它们之间存在某种相关性时,推断函数的分布
对于情况一,常规的(概率)监督学习就能解决:给定一个包含N个样本的数据集,比如(xi, yi),其中i=1,…,N。假设确实存在一个函数f,它能产生yi=f(xi),我们的目标就是学习f的后验分布,然后用它预测测试集上某点的函数值f(x∗)。
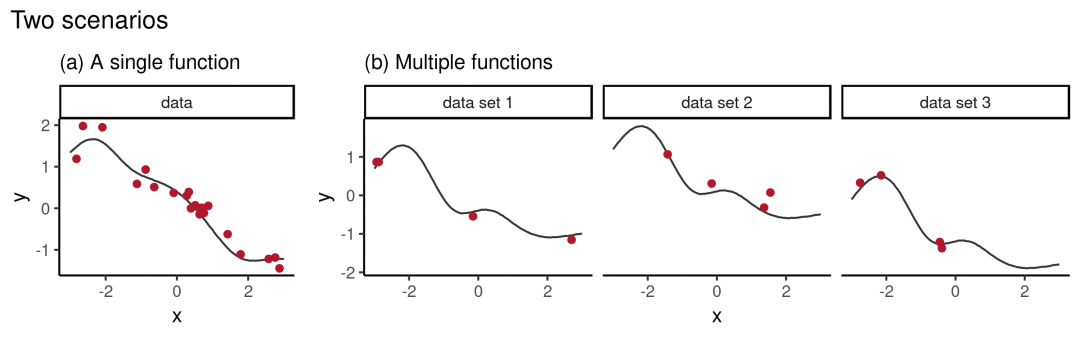
对于情况二,我们则需要从元学习的角度去观察。给定D个数据集,其中d=1,…,D,每个数据集包含Nd个数据对(xi(d), yi(d))。如果我们假设每个数据集都有自己的基函数fd,输入xi后,它们有yi=fd(xi),那么在这种情况下,我们就可能想要了解每个fd的后验分布,然后把经验推广到新数据集d∗上。
对于数据集很多但它们的样本很少的情况,情况二的做法特别有用,因为这时模型学到的经验基于所有fd,它的内核、超参数是这些函数共享的。当给出新的数据集d∗时,我们可以用后验函数作为先验函数,然后执行函数回归。
之所以要举着两个例子,是因为一般来说,GP适用于情况一,即便N很小,这种做法也很有效。而NP背后的思路似乎主要来自元学习——在这种情况下,潜在的z可以被看作是用于不同数据集间信息共享的机制。但是,NP同样具有概率模型的特征,事实上,它同时适用于以上两种情况,具体分析请见下文。
NP模型是怎么实现的?
下面是NP生成模型的详细图解:
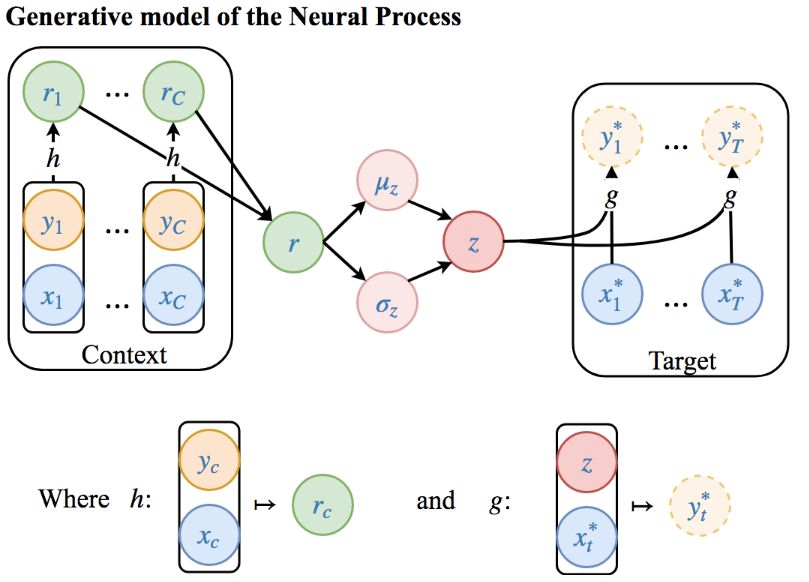
如果要逐步分解这个过程,就是:
首先,“context points”里的数据(xc,yc)通过神经网络h映射,获得潜在表征rc
其次,这个向量rc经聚合(操作:平均)获得单个值r(和每个rc具有相同的维数)
这个r的作用是使z的分布参数化,例如p(z|x1:C,y1:C)=N(μz(r),σ2z(r))
最后,为了预测输入x∗t后的函数值,对z采样并将样本与x∗t组成数对,用神经网络g映射(z,x∗t)获得预测分布中的样本y∗t。
NP的推断是在变分推断(VI)框架中进行的。具体来说,我们介绍了两种近似分布:
让q(z|context)去近似条件先验p(z|context)
让q(z|context,target)去近似于各自的p(z|context,target),其中context:=(x1:C,y1:C),target:=(x∗1:T,y∗1:T)
下图是近似后验q(z|·)的具体推断过程。也就是说,我们用相同的神经网络h映射两个数据集,获得聚合的r,再把r映射到μz和σz,使后验q(z|⋅)=N(μz,σz)被参数化。
变分下界包含两个项(下式),其中第一项是target集上的预期对数似然,即先从z∼q(z|context,target)上采样(上图左侧),然后用这个z在target set上预测(上图右侧)。
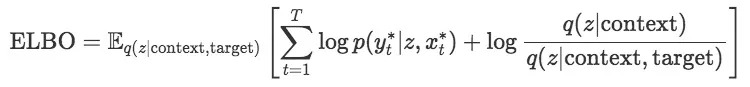
第二项是个正则项,它描述了q(z|context,target)和q(z|context)之间的KL散度。这和常规的KL(q||p)有点不同,因为我们的生成模型一开始就把p(z|context)当做条件先验,不是p(z),而这个条件先验有依赖于神经网络h,这就是我们没法得到确切值,只能用一个近似值q(z|context)。
实验
NP作为先验
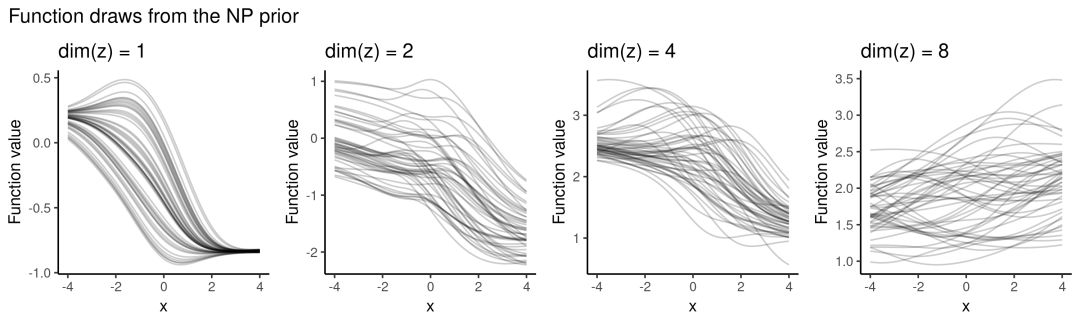
我们先来看看把NP作为先验的效果,也就是没有观察任何数据,模型也没有经过训练。初始化权重后,对z∼N(0,I)进行采样,然后通过x∗值的生成先验预测分布并绘制函数图。
和具有可解释内核超参数的GP相反,NP先验不太明确,它涉及各种架构选择(如多少隐藏层,用什么激活函数等),这些都会影响函数空间的先验分布。
例如,如果我们用的激活函数是sigmoid,调整z的维数为{1, 2, 4, 8}。
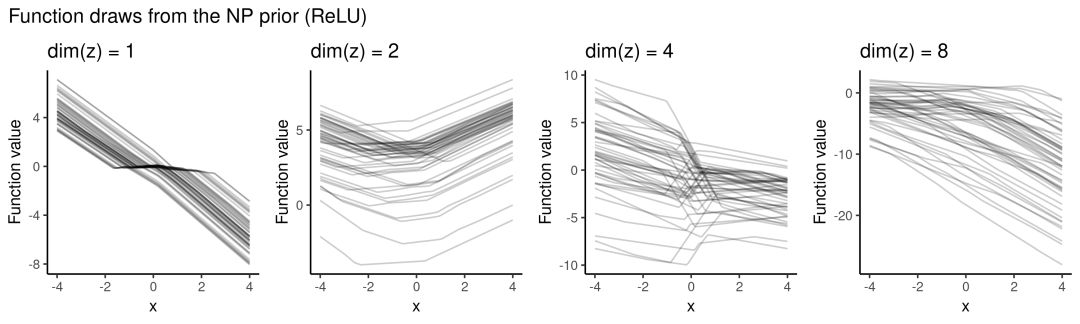
如果用的是ReLU:
在一个小数据集上训练NP
假设我们只有5个数据点:
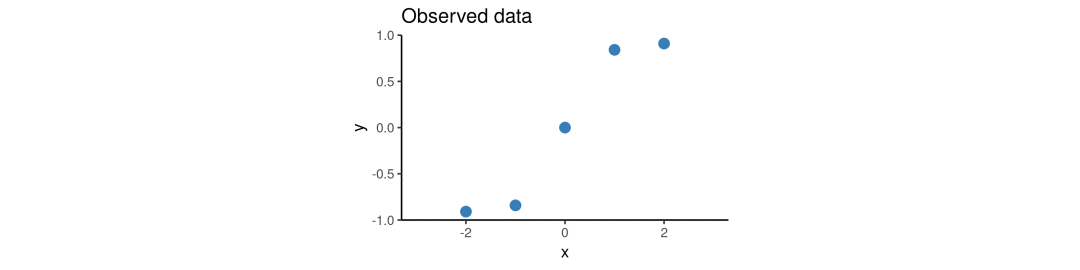
由于NP模型需要context set和target set两个数据集,一种方法是选取固定大小的context set,另一种方法则是用不同大小的context set,然后多迭代几次(1个点、2个点……以此类推)。一旦模型在这些随机子集上完成训练,我们就可以用它作为所有数据的先验和条件,然后根据预测结果绘制图像。下图展示了NP模型训练时的预测分布变化。
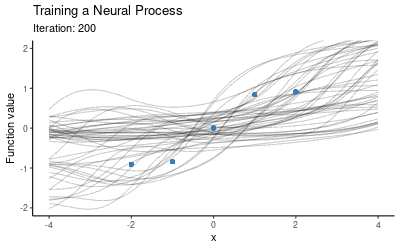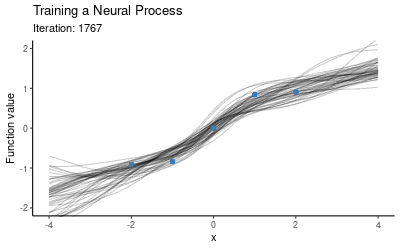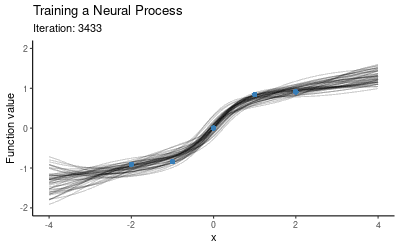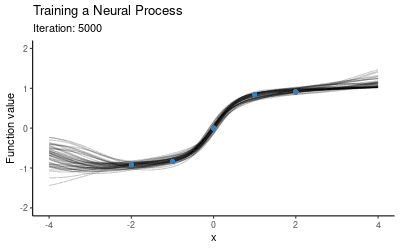
可以发现,NP似乎已经成功学习了这5个数据点的映射分布,那它的泛化性能如何呢?我们把这个训练好的模型放在另一个新的context set上,它的表现如下图所示:
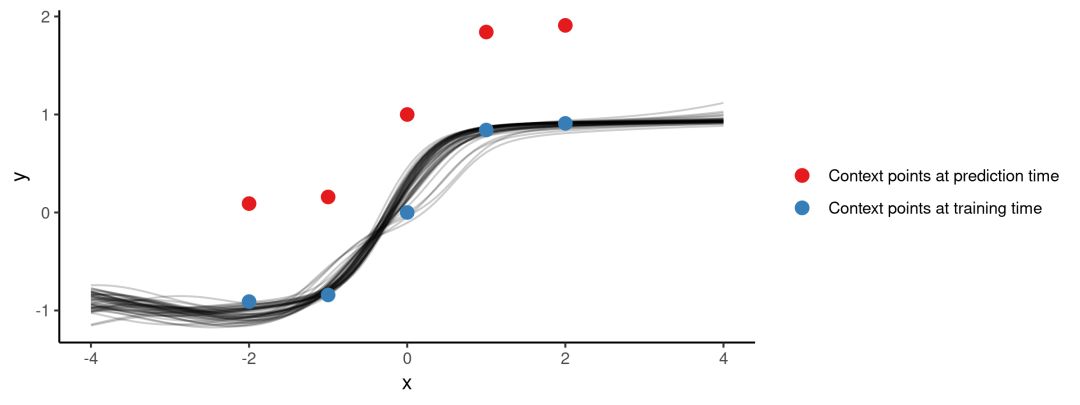
这个结果不足为奇,数据量太少了,模型过拟合可以理解。为了更好地提高模型泛化性,我们再来试试更大的函数集。
在一小类函数上训练NP
上文已经用单个(固定)数据集探索了模型的训练情况,为了让NP像GP一样通用,我们需要在更大的一类函数上进行训练。但在准备复杂函数前,我们先来看看模型在简单场景下的表现,也就是说,这里观察的不是单个函数,而是一小类函数,比如它们都包含a⋅sin(x),其中a∈[−1,1]。
我们的目标是探究:
NP能不能捕捉这些函数?
NP能不能概括这类函数以外的函数?
下面是具体步骤:
设a满足均匀分布:a∼U(−2,2)
设xi∼U(−3,3)
定义yi:=f(xi),其中f(x)=a⋅sin(x)
把数据对(xi,yi)随机分成context set和target set两个数据集,并进行优化
重复上述步骤
为了方便可视化,这里我们用了二维z,具体图像如下所示:
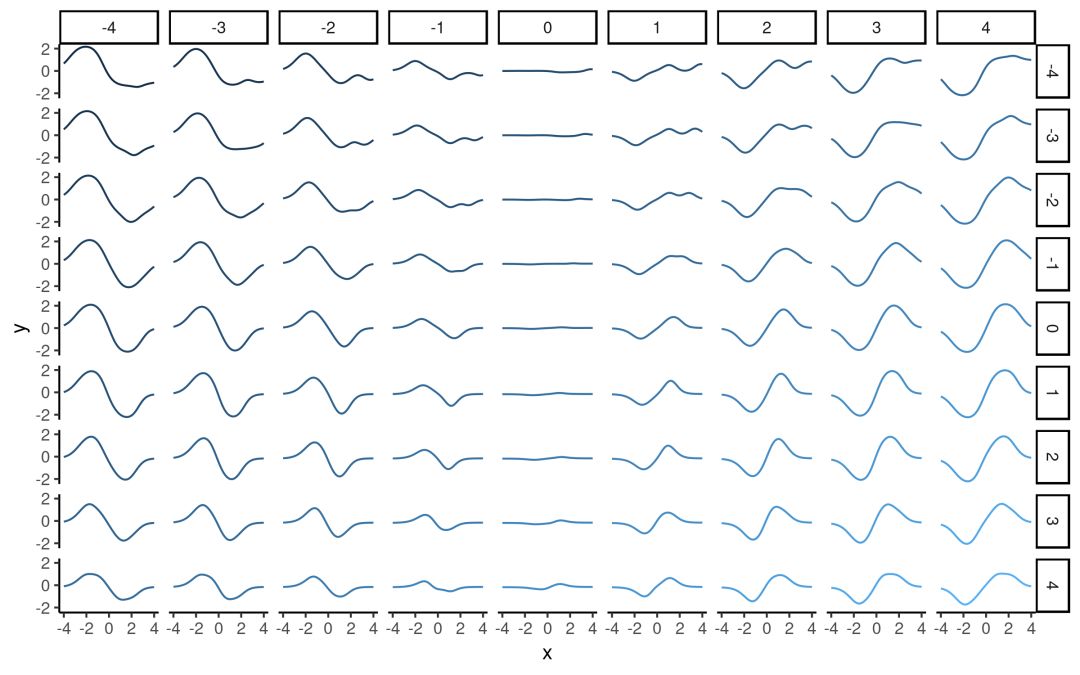
从左往右看,模型似乎编码了参数a,如果这幅图不够直观,下面是调整某一潜在维度(z1或z2)的动态可视化:
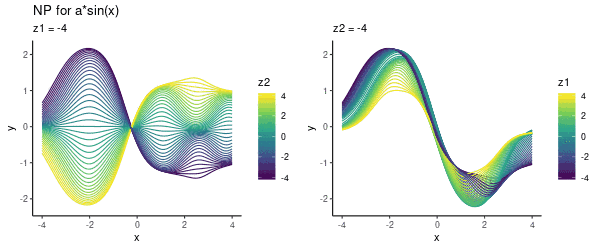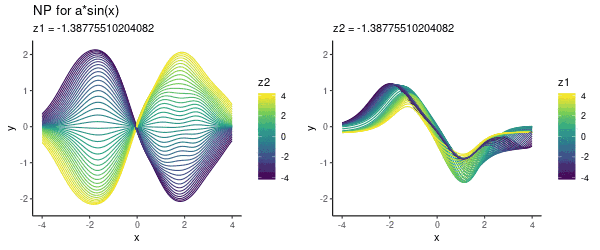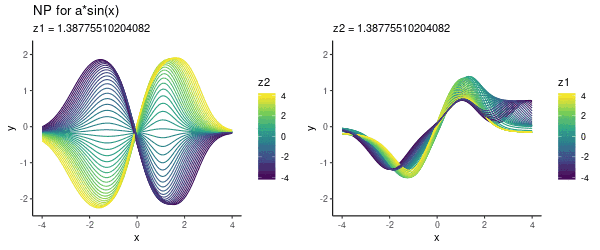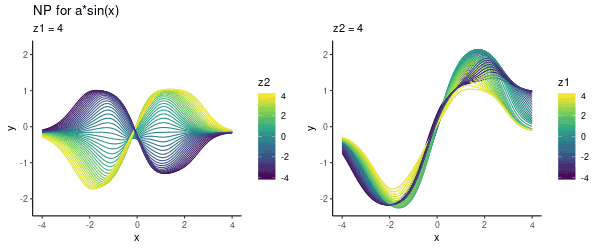
需要注意的是,这里我们没有用任何context set里的数据,只是为了可视化指定了具体的(z1, z2)值。接下来,就让我们用这个模型进行预测。
如下左图所示,当context set数据集里只包含(0, 0)一个点时,模型覆盖了一个较宽的范围,包含不同a取值下a⋅sin(x)的值域(虽然a∈[−2,2],但训练时并没有完全用到)。
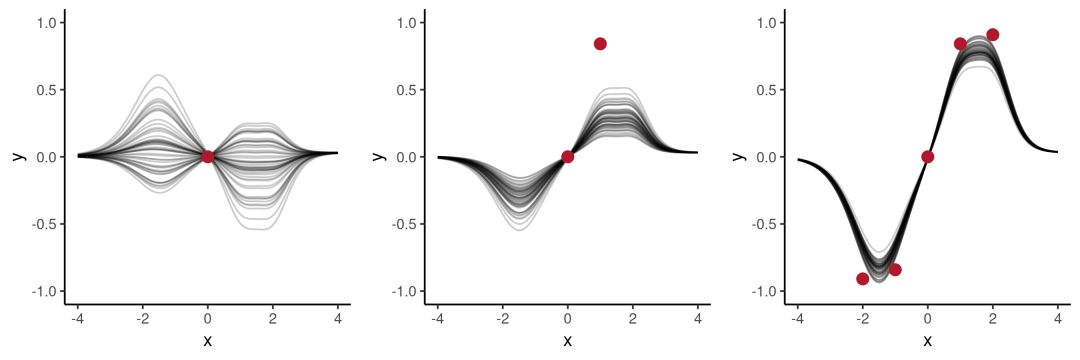
往context set数据集里添加第二个点(1,sin(1))后,可视化如中图所示,相比左图,它不再包含a为负数的情况。右图是继续添加f(x)=1.0sin(x)的点后的情况,这时模型后验开始接近函数的真实分布情况。
这之后,我们就可以开始探究NP模型的泛化性,以2.5sin(x)和|sin(x)|为例,前者需要在a⋅sin(x)的基础上做一些推断,而后者的值始终是个正数。
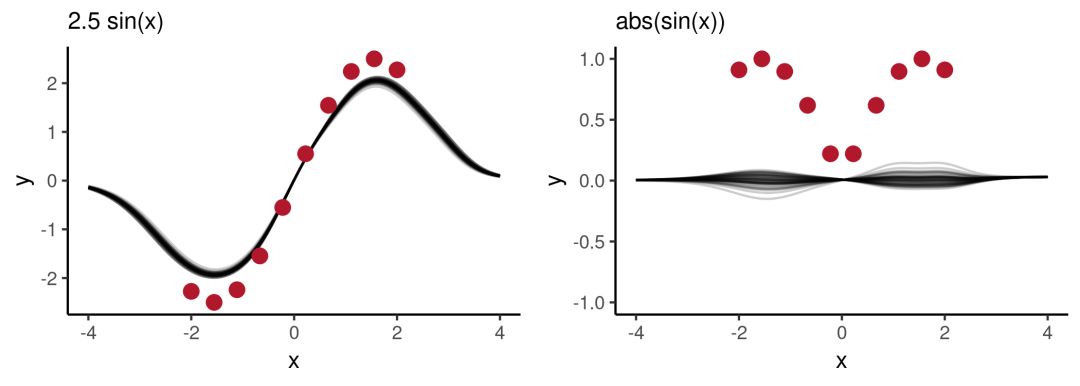
如上图所示,模型的值域还是和训练期间一样,但它在两种情况下都出现了符合函数分布的一些预期。需要注意的是,这里我们并没有给NP提供足够多的不确定性,所以它预测不准确也情有可原,毕竟比起易于解释的模型,这种自带黑盒特性的模型更难衡量。
之后,作者又比较了GP和NP的预测分布情况,发现两者性能非常接近,只是随着给出的数据点越来越多时,NP会因为架构选择(神经网络过小、低纬度z)出现性能急剧下降。对此,以下几个改进方法可以帮助解决问题:
2维z适合用于学习理解,在实际操作中,可视情况采用更高的维度
让神经网络h和g变得更深,扩大隐藏层
在训练期间使用更多样化的函数(更全面地训练NP超参数),可提高NP模型泛化性
结论
虽然NP号称结合了神经网络和GP,能预测函数的分布,但它从本质上看还是更接近神经网络模型——只需优化架构和训练过程,模型性能就可以大幅提高。但是,这些变化都是隐含的,使得NP更难被解释为先验。
原文地址:kasparmartens.rbind.io/post/np/