还敢说自己是TED粉吗? 连哪个演讲最爆款都不知道!

编译:元元、sunflower
科学VS心理,哪类演讲播放量能相差20倍!
当我看到Kaggle上的TED数据集时,竟然发现观看次数极为分散:从五万到四千七百万多(平均数为100万左右)。到底是什么原因使得某些演讲独占鳌头, TED组织者和演讲者能否抓住这个秘诀制造下一个"爆款"呢?
下文中,我们尝试着从预测TED演讲的受欢迎程度出发,来分析最具影响力的因素。
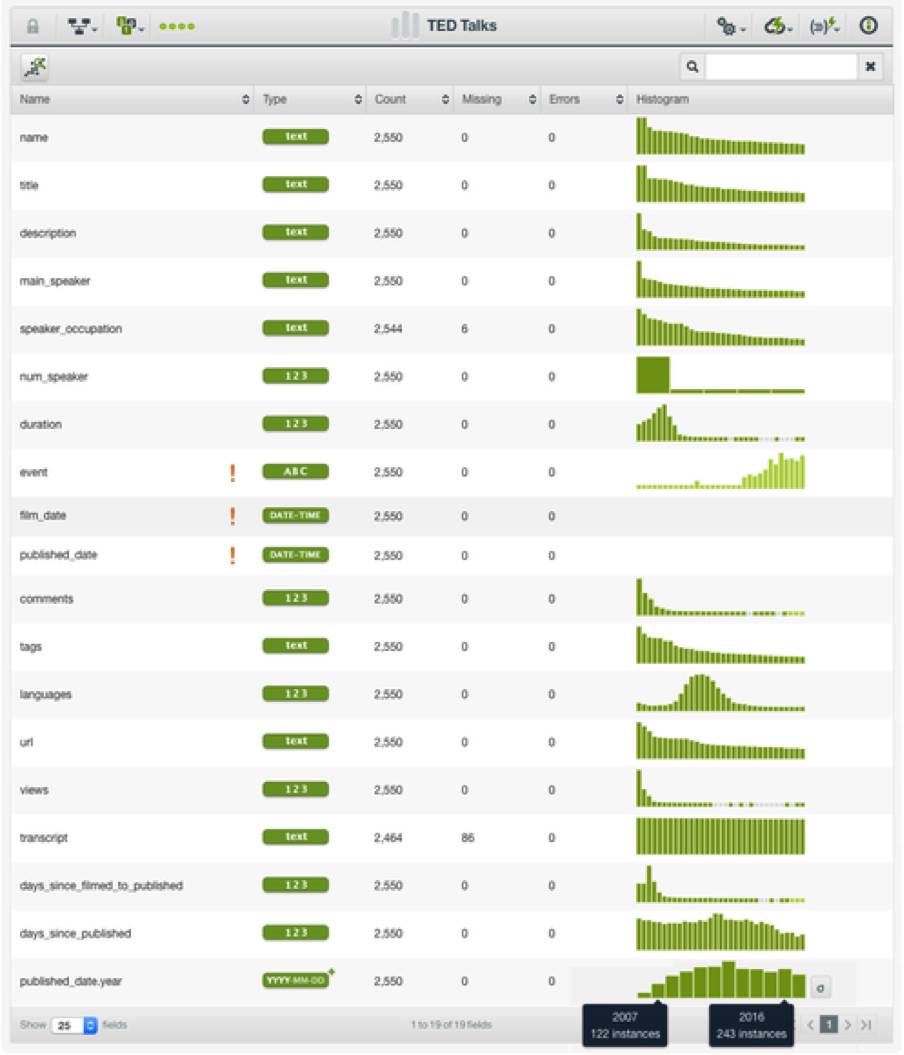
从文本字段中,我们可以检查标签云中的单词频率
标题中最常用的词语是“世界”、“生活”和“未来”。
数据涵盖的特征主要有两大类:
1.告诉我们演讲造成的影响(评论、演讲语言和观看次数[我们的目标字段]);
2.描述演讲本身特点(标题、内容介绍、字幕、演讲者、时长等)。
除了原有的特征外,我们还提炼出两个额外的特征:
视频创作和发布相差天数;
发布和数据收集(2017年9月21日)相差天数。
BigML的主题模型(Topic Models)解决方案最酷的地方在于大家不需要担心文本的预处理。 BigML特别之处在于能自动清理标点符号,统一大小写,排除停用词,并在主题模型创建过程中应用词干,非常方便。还可以通过预先配置主题模型微调设置,并且引入二元语法(bigrams)。
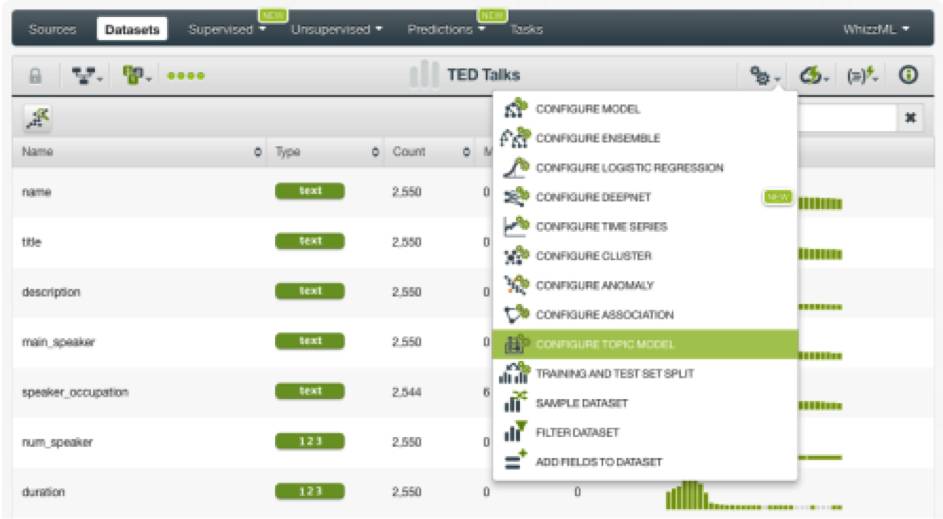
我们从建好的主题模型中可以看到,BigML在我们的TED演讲数据里发现了40个不同的主题,其中包括技术、教育、商业、宗教、政治和家庭等等。
所有的主题如下圆圈图所示,每个圆圈代表一个主题。圆圈的大小表示数据集中该主题的重要性,相关主题在图中位置更为接近。每个主题圆圈都包含术语的概率分布。如果将鼠标悬停在某个主题上,可以看到该主题内频率排名前20的术语及其概率。
BigML还提供了另一个可视化工具,大家可以看到横条显示的每个主题中的所有高频术语。也可以在下图中看到两个视图,或者也可以由此查看模型。
BigML主题模型是潜在狄利克雷分配模型(Latent Dirichlet allocation
,LDA)的优化实现。LDA是主题建模中最流行的概率学方法之一。
现在,我们想要对TED演讲数据做同样处理。要计算每个TED 演讲的主题概率,我们首先要使用一键操作菜单中的批量主题分布(Batch Topic Distribution)选项。然后,选择TED演讲数据集。与此同时,还要确保“通过主题分布创建新数据集”的选项已启用。
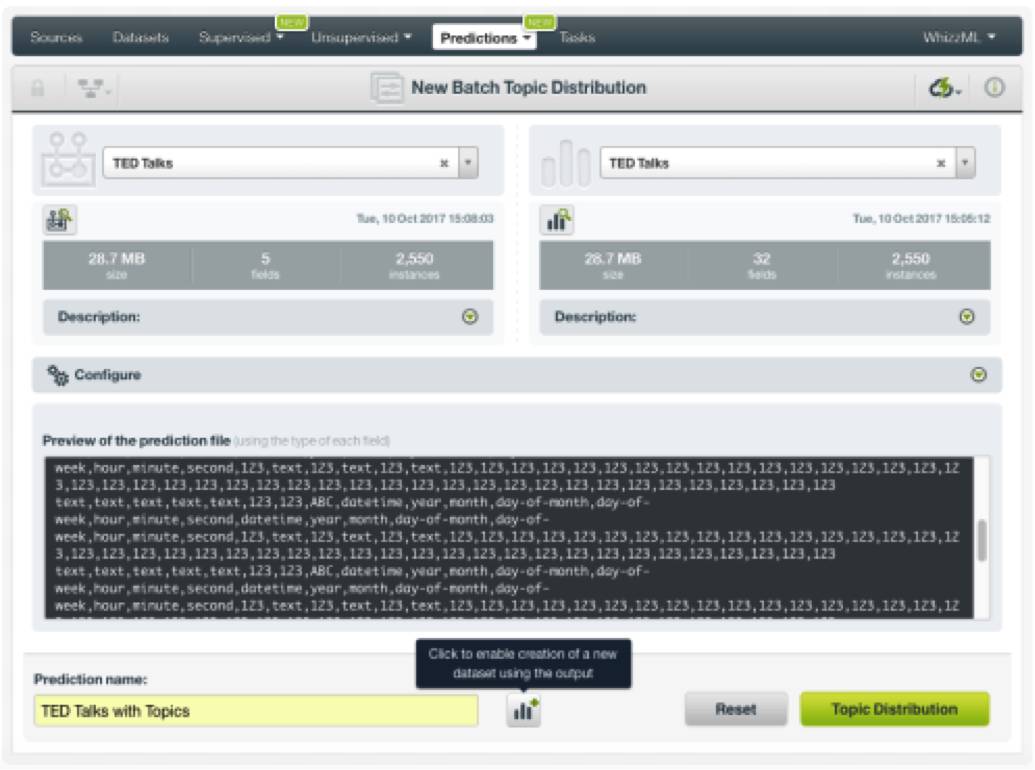
创建批量主题分布时,我们可以得到新增了数字字段的新数据集。新数据集包含:针对每个TED演讲的各个主题出现的概率。这些字段将替换掉字幕、标题、内容介绍和标签,作为输入值来帮助我们预测观看次数。
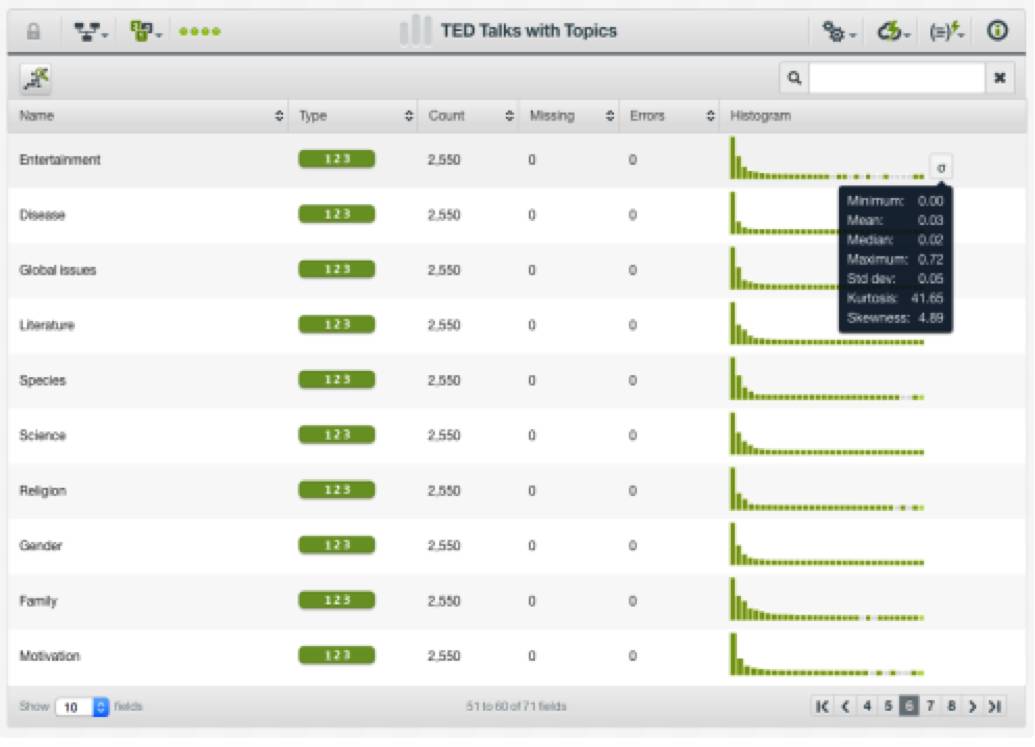
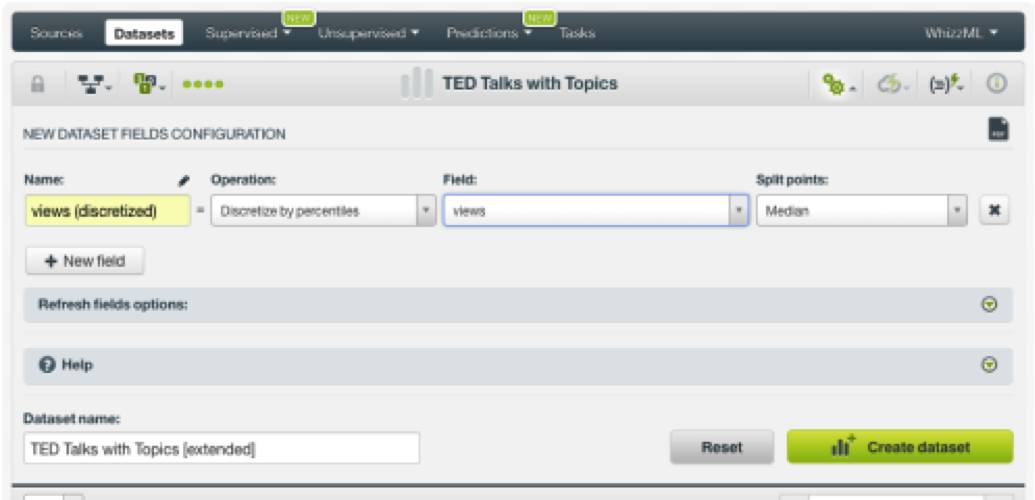
随后,我们点击按钮来创建一个新的数据集。
这个数据集包含一个类别新字段,其中的值作为两个类别体现。
观看次数低于中值的演讲(观看次数小于100万)属于类别一;
观看次数高于中值的演讲(观看次数大于100万)属于类别二。
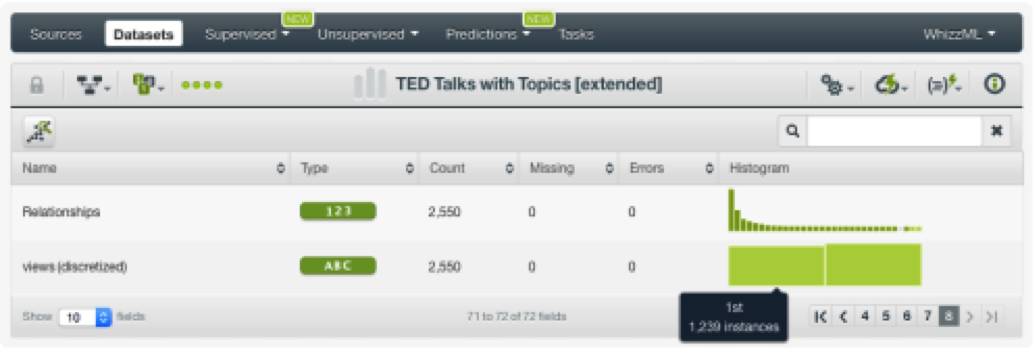
在创建我们的分类模型之前,我们需要将我们的数据集分成两个子集:
一个子集包括80%的数据,用于训练;
另一个子集包括剩下的20%的数据,用于测试。
这是为了确保我们的模型能够很好地推广出以前模型从未见过的数据。在BigML中,我们可以使用一键操作菜单中的相应选项来轻松完成这一步,如下图所示。
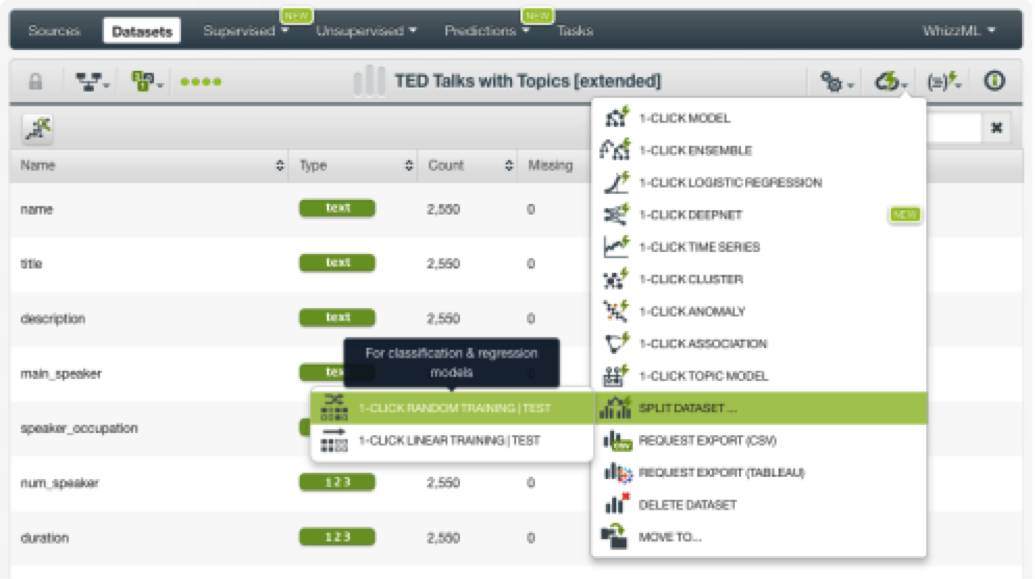
我们接着用原数据集中80%的数据,来创建预测模型。
为了比较不同的算法的结果,我们创建了一个单一决策树模型,一个集成模型 (随机决策森林),一个逻辑回归模型,以及BigML新增的Deepnet模型(现在很流行的深度神经网络的优化实现)。
我们可以从数据集菜单中轻松创建这些模型。BigML自动选择数据集中的最后一个字段作为目标字段。在这个数据集中目标字段选择的是观看次数(已经转化为类别)。我们不需要对其进行单独配置,就可以使用一键操作菜单轻松创建我们的模型了。
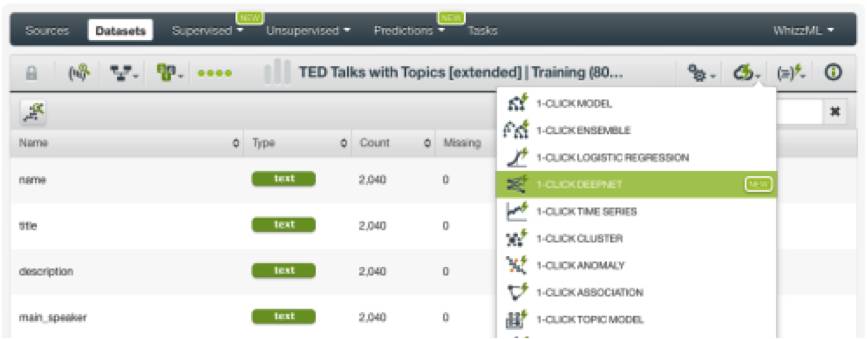
一键Deepnet使用一个名为“结构建议”(Structure Suggestion)的自动参数优化选项。除了一键Deepnet之外,我们还可以通过配置另一个名为“网络搜索”(Network Search)的自动参数优化选项来创建另一个Deepnet。BigML提供这个独特的自动参数优化功能,能帮助大家省略手动调整Deepnet参数这项既困难又耗时的工作。(开心)
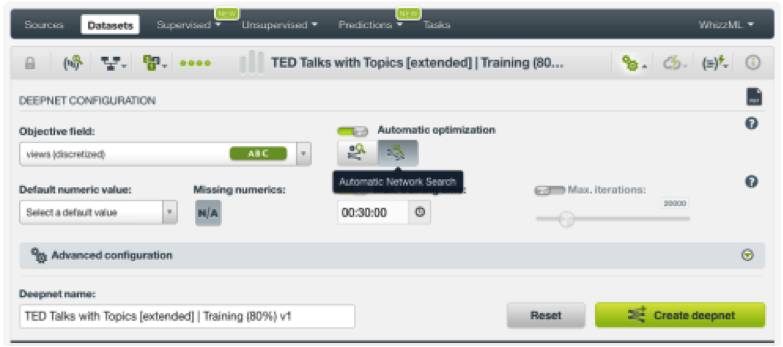
经过一些迭代后,我们注意到与演讲者相关的特征对观看次数没有影响。因此,我们去掉了相应的字段。“事件”字段似乎会造成过拟合,所以我们把“事件”字段也移除了。最后,模型输入的自变量字段为: 主题、演讲发表年份、演讲时长,以及我们计算的演讲发布日期到数据收集日期(2017年9月21日)天数。
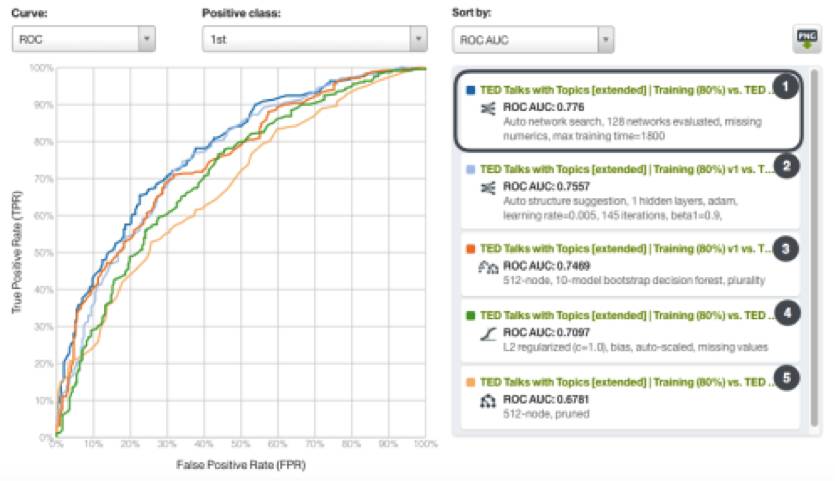
用这些选定特征创建了所有的模型之后,我们需要用之前剩余的20%的数据来评估每个模型的表现。BigML评估比较工具可以同时分析几个模型的结果,利用这个工具,我们可以轻松的比较几个模型的表现。
如下图所示,结果AUC(Area under the curve,曲线下面积
)最高的模型获胜。
获胜者(AUC为0.776)是使用自动参数化选项“网络搜索”的Deepnet;
表现第二好的模型是另一个使用自动选项“结构建议”的Deepnet,它的AUC值是0.7557。
第三名的是集成模型(AUC为0.7469);
第四名是逻辑回归模型(AUC为0.7097);
最后一名是单一决策树模型(AUC为0.6781)。
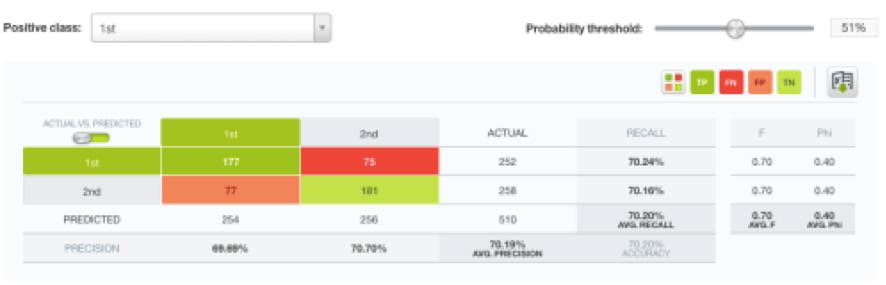
让我们看到表现最好的Deepnet模型的混淆矩阵中,对于目标字段的两个类别我们的预测都达到了70%的精度。
通常情况下,深度神经网络的预测很难分析。因此,BigML提供了一些工具来让大家能更容易理解模型预测得到某个特定值从而何来。
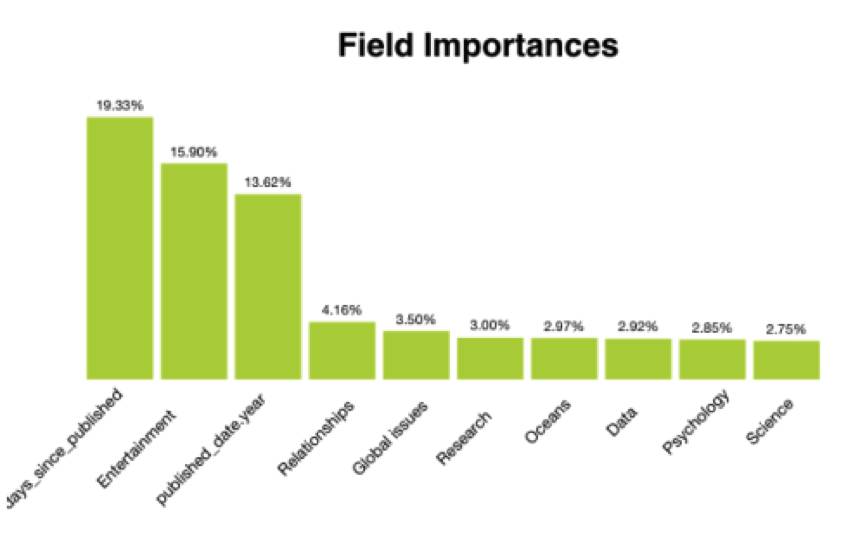
图表标题:特征的重要性
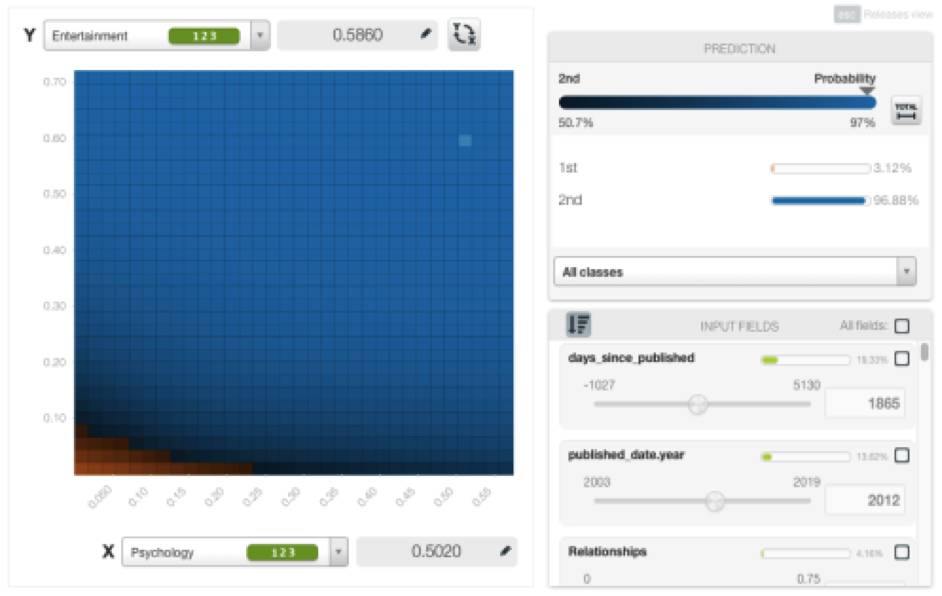
经Deepnet模型的分析之后,我们得知演讲主题与观看次数相关,并且还可以用来预测观看次数。但是演讲主题究竟是如何影响预测值的呢?心理学相比科学而言,受众观看的次数是多还是少呢?为了回答这个问题,BigML提供了一个”部分相关图”(Partial Dependence Plot)视图,在这个视图中我们可以分析输入字段来看对目标字段的边际影响。下文举出了一些例子(如果您有时间可以尝试这个可视化工具)。
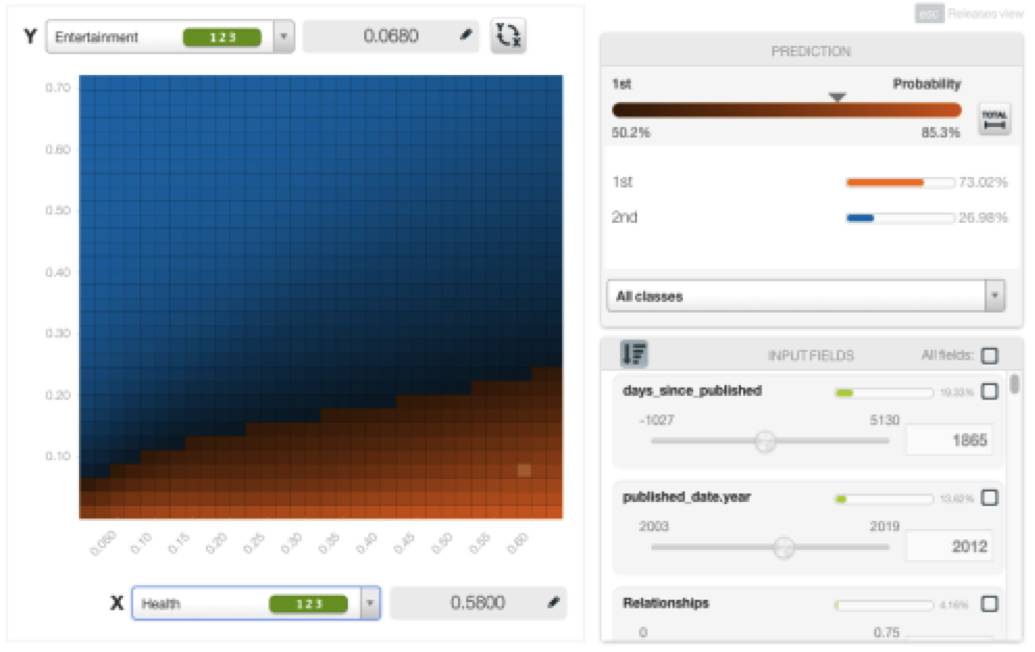
举例来说,请看下图中“娱乐”和“心理”这两个主题的组合如何对观看次数产生积极的影响。
这两个主题中的概率较高的演讲,被预测得到的观看次数为第二类(蓝色),即观看次数超过100万。
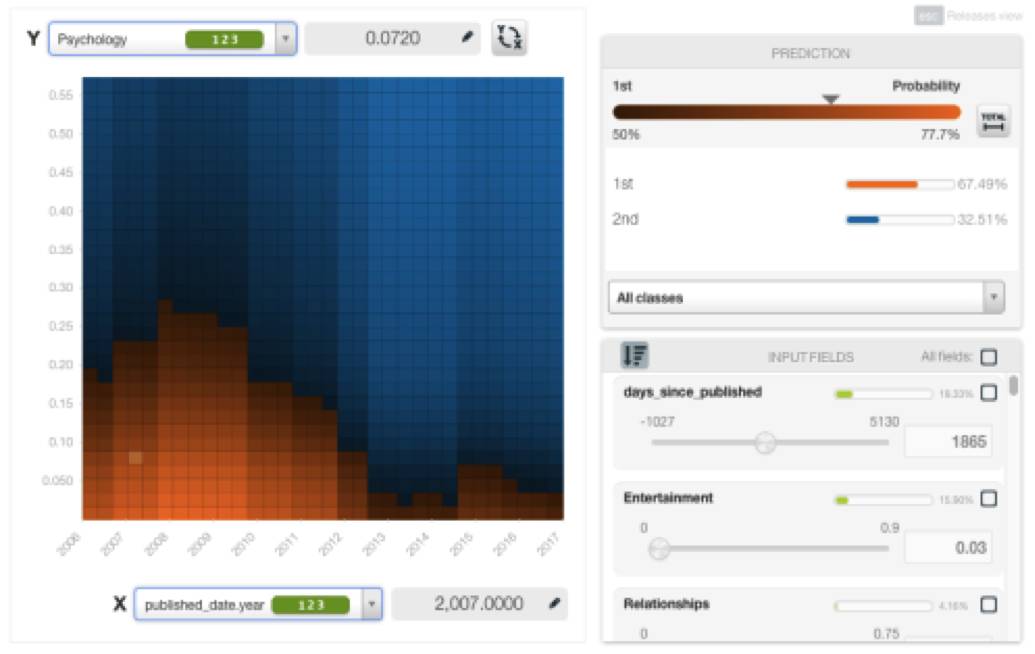
我们也可以看到一些主题的热度随着时间而改变。
如下图所示,2012年至2017年期间,心理学主题超过100万次观看的概率逐年增加。
总而言之,我们发现演讲主题对观看次数有着显著性的影响。在分析每个主题对预测值的影响之后,我们观察到:
关于娱乐、启发等“积极”的话题,观看次数较高的可能性更大;
疾病、全球性问题,战争等“负面”的主题观看次数较少的可能性更大;
以个人为中心的主题:如心理学或人际关系等的关注度在过去几年中有所增加;
更广泛的社会问题:如健康或发展等的关注度则有所下降。
TED始于1984年,它最初是以技术、教育和设计为主题而举办的系列会议。可以说TED演讲的本质目的就是使知识民主化。如今,TED每年会举办超过200多场演讲,内容涵盖几十个不同的主题。尽管有人士批评过,TED演讲不应该把复杂的思想仅近缩减为20分钟的自传式启发式故事来表达,但是它对我们社会中知识传播的巨大影响仍是不容置疑的。
原文链接:
https://dzone.com/articles/predicting-ted-talks-popularity?edition=334723&utm_source=Daily%20Digest&utm_medium=email&utm_campaign=Daily%20Digest%202017-10-24
课程推荐
数据科学实训营第4期
报名优惠倒计时第5天!
如果,你正在求职、跳槽、研究,需快速提升实战技能
如果,你渴望大展身手,搏一席之地
如果,你想在数据时代掌握主动权
那么,你需要实训营助你一臂之力!
扫描海报二维码,获取成长机会!

志愿者介绍
回复“志愿者”加入我们


往期精彩文章
点击图片阅读
FinTech创业的两大势力,以及他们各有千秋的数据应用模式 | TCFA纽约年会直击







