
主题: Low-Dimensional Hyperbolic Knowledge Graph Embeddings
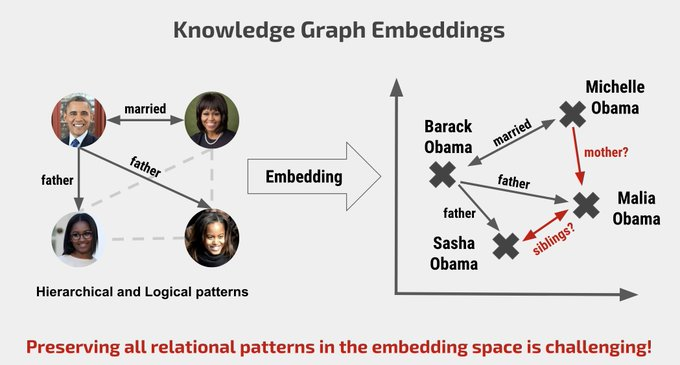
摘要: 知识图谱(KG)嵌入学习实体和关系的低维表示,以预测缺失的内容。 KG通常表现出必须保留在嵌入空间中的分层和逻辑模式。对于分层数据,双曲线嵌入方法已显示出对高保真和简约表示的希望。但是,现有的双曲线嵌入方法无法解决KG中的丰富逻辑模式。在这项工作中,我们介绍了一类双曲KG嵌入模型,该模型同时捕获层次结构和逻辑模式。我们的方法将双曲线反射和旋转结合在一起,以注意对复杂的关系模式进行建模。在标准KG基准上的实验结果表明,我们的方法在较低维度上的平均倒数排名(MRR)比以前的基于欧几里德和双曲线的方法提高了6.1%。此外,我们观察到,不同的几何变换捕获不同类型的关系,而基于注意力的变换则泛化为多个关系。在高维度上,我们的方法在WN18RR上产生了49.6%的最新技术水平,在YAGO3-10上产生了57.7%的最新技术水平。
成为VIP会员查看完整内容
相关内容
专知会员服务
60+阅读 · 2020年6月28日
专知会员服务
77+阅读 · 2020年6月14日
专知会员服务
78+阅读 · 2020年5月11日
专知会员服务
116+阅读 · 2019年12月30日
Arxiv
6+阅读 · 2019年8月17日


相关VIP内容
专知会员服务
60+阅读 · 2020年6月28日
专知会员服务
77+阅读 · 2020年6月14日
专知会员服务
78+阅读 · 2020年5月11日
专知会员服务
116+阅读 · 2019年12月30日
相关资讯
相关论文
Arxiv
6+阅读 · 2019年8月17日