行家 | 如何跨领域成为一位人工智能工程师?

作者/分享人 | 李嘉璇
《TensorFlow技术解析与实战》作者,InfoQ、51CTO、Oreilly Strata 等大会讲师,活跃于国内各大技术社区,知乎编程问题回答者。擅长研究深度学习框架的架构、源码分析及在不同领域的应用。有处理图像、社交文本数据情感分析、数据挖掘等深度学习实战经验,参与过基于深度学习的自动驾驶二维感知系统 Hackathon 竞赛, 曾任职百度研发工程师。现在研究 NLP、ChatBot,以及 TensorFlow 的性能优化及 FPGA 编译。
文章来源Gitchat,AI科技大本营合作发布
本场 Chat 内容主要包括:
人工智能的整体知识体系梳理。
人工智能/深度学习工程师的职业前景如何?
非相关专业有可能自学入门么?自学的方法和进阶体系如何构建?
在 Java/客户端/前端/iOS 已经工作8年,那进入这个新的领域,新手深度学习工程师有哪些门槛,怎么克服?
希望和大家理解 AI 的一些编程思路和模型,帮助梳理自我成长路线。
一、人工智能的整体知识体系梳理
AI 领域目前有哪些知识体系构成是怎么样的呢?也就是说真正成为一名深度学习工程师,我们在现有的工程师基础上,要做哪些方面的准备呢?
目前的深度学习的研究领域主要有以下3类人群。
学者。主要做深度学习的理论研究,研究如何设计一个“网络模型”,如何修改参数以及为什么这样修改效果会好。平时的工作主要是关注科研前沿和进行理论研究、模型实验等,对新技术、新理论很敏感。
算法改进者。这些人为了把现有的网络模型能够适配自己的应用,达到更好的效果,会对模型做出一些改进,把一些新算法改进应用到现有模型中。这类人主要是做一些基础的应用服务,如基础的语音识别服务、基础的人脸识别服务,为其他上层应用方提供优良的模型。
工业研究者。这类人群不会涉及太深的算法,主要掌握各种模型的网络结构和一些算法实现。他们更多地是阅读优秀论文,根据论文去复现成果,然后应用到自己所在的工业领域。这个层次的人也是现在深度学习研究的主流人群。
我详细目前大家的转型需求上来看,和大家最契合以及最匹配的,就是第二类和第三类人群,且以第三类人群居多。这就是深度学习工程师目前要做的主要工作。
从这个目标来看,我们从以下几个方面进行梳理。
框架
目前市面上的 DL 框架很多,例如 TensorFlow、Caffe、Pytorch 等,框架的性能优劣也有很多人在比较。我们仅从流行度上和转型者上手的难易程度上来看,建议大家首选 TensorFlow。下面是截至到今年3月份的框架流行度趋势图:
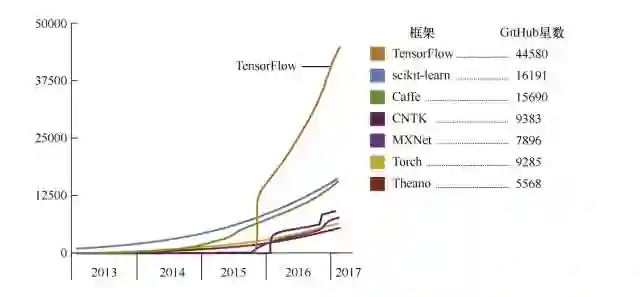
那么抛开特定的框架,从功能上讲,一个深度学习/机器学习的框架应该具有哪些功能呢?
Tensor 库是对 CPU/GPU 透明的,并且实现了很多操作(如切片、数组或矩阵操作等)。这里的透明是指,在不同设备上如何运行,都是框架帮用户去实现的,用户只需要指定在哪个设备上进行哪种运算即可。
有一个完全独立的代码库,用脚本语言(最理想的是 Python)来操作 Tensors,并且实现所有深度学习的内容,包括前向传播/反向传播、图形计算等。
可以轻松地共享预训练模型(如 Caffe 的模型及 TensorFlow 中的 slim 模块)。
没有编译过程。深度学习是朝着更大、更复杂的网络发展的,因此在复杂图算法中花费的时间会成倍增加。而且,进行编译的话会丢失可解释性和有效进行日志调试的能力。更多请参考《The Unreasonable Effectiveness of Recurrent Neural Networks》。
TensorFlow 提供了 Python、C++、Java 接口来构建用户的程序,而核心部分是用 C++ 实现的。
下图给出的是 TensorFlow 的系统架构,自底向上分为设备层和网络层、数据操作层、图计算层、API 层、应用层,其中设备层和网络层。
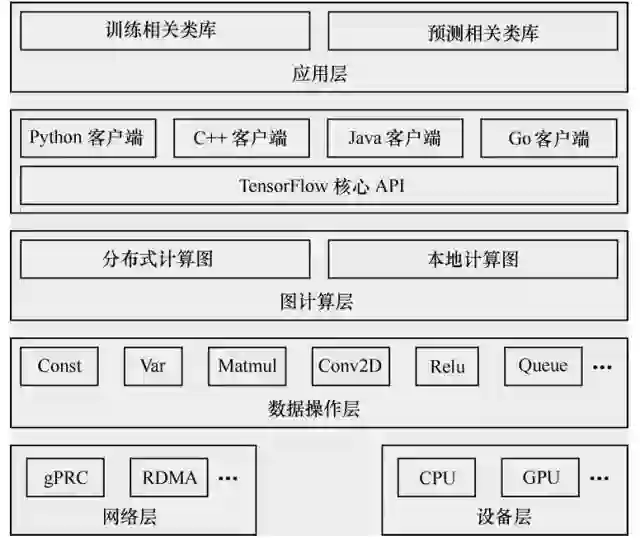
数据操作层、图计算层是 TensorFlow 的核心层。
下面就自底向上详细介绍一下 TensorFlow 的系统架构。最下层是网络通信层和设备管理层。网络通信层包括 gRPC(google Remote Procedure Call Protocol)和远程直接数据存取(Remote Direct Memory Access,RDMA),这都是在分布式计算时需要用到的。设备管理层包括 TensorFlow 分别在 CPU、GPU、FPGA 等设备上的实现,也就是对上层提供了一个统一的接口,使上层只需要处理卷积等逻辑,而不需要关心在硬件上的卷积的实现过程。
其上是数据操作层,主要包括卷积函数、激活函数等操作。再往上是图计算层,也是我们要了解的核心,包含本地计算图和分布式计算图的实现。再往上是 API 层和应用层。
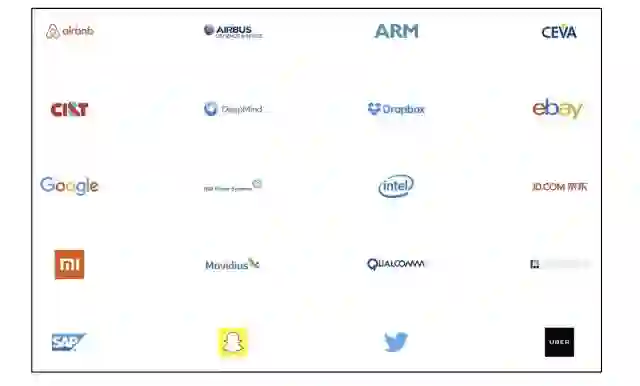
使用 TensorFlow 的公司有很多,除了谷歌在自己的产品线上使用 TensorFlow 外,国内的京东、小米、新浪、中兴等公司,以及国外的 Uber、eBay、Dropbox、Airbnb 等公司,都在尝试使用 TensorFlow。
论文
每周读懂一篇论文,每月实现或者读懂一篇论文的开源实现,是一个比较合理的学习节奏。
从工程上转型的人,之前缺乏论文阅读的习惯,可能一时半会读起来费力,加上英语的语言障碍,会很长时间徘徊在外面无法入门。
这里的一个好的建议就是:
先看和这篇论文主要思想相关的中文综述,中文博士论文,而后是英文综述。
通过中文综述,可以首先了解这个领域的基本名词、实验常用方法。否则直接从论文入手的话,作者站的高度和我们的水平不一致,很容易想当然的理解或者根本看不下去。因此,在阅读这篇文章之前,对于这篇文章中涉及到的基础知识,对应中文基础都理解透彻。
那么转型时期读哪些论文能尽快掌握精髓呢?我们以 CNN 的发展为例,来看:
卷积神经网络的发展过程如图所示。
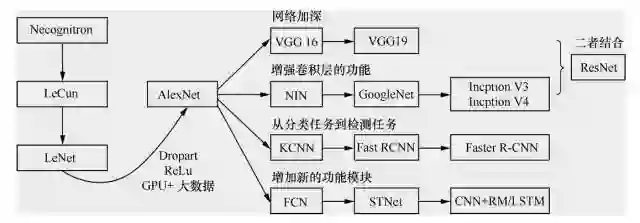
卷积神经网络发展的起点是神经认知机(neocognitron)模型,当时已经出现了卷积结构。第一个卷积神经网络模型诞生于1989年,其发明人是 LeCun。学习卷积神经网络的读本是 Lecun的论文,在这篇论文里面较为详尽地解释了什么是卷积神经网络,并且阐述了为什么要卷积,为什么要降采样,径向基函数(radial basis function,RBF)怎么用,等等。
1998年 LeCun 提出了 LeNet,但随后卷积神经网络的锋芒逐渐被 SVM 等手工设计的特征的分类器盖过。随着 ReLU 和 Dropout 的提出,以及GPU和大数据带来的历史机遇,卷积神经网络在2012年迎来了历史性突破—AlexNet。
如图所示,AlexNet 之后卷积神经网络的演化过程主要有4个方向的演化:
一个是网络加深;
二是增强卷积层的功能;
三是从分类任务到检测任务;
四是增加新的功能模块。
如上图,分别找到各个阶段的几个网络的论文,理解他们的结构和特点之后,在 TensorFlow Models 下,都有对这几个网络的实现。
对着代码理解,并亲自运行。随后在自己的数据集上做一做 finetune,会对今后工业界进行深度学习网络的开发流程有个直观的认识。
下面就简单讲述各个阶段的几个网络的结构及特点。
网络加深
LeNet
LeNet 的论文详见:
http://vision.stanford.edu/cs598_spring07/papers/Lecun98.pdf
LeNet包含的组件如下。
输入层:32×32
卷积层:3个
降采样层:2个
全连接层:1个
输出层(高斯连接):10个类别(数字0~9的概率)
LeNet的网络结构如图所示

下面就介绍一下各个层的用途及意义。
输入层。输入图像尺寸为32×32。这要比MNIST数据集中的字母(28×28)还大,即对图像做了预处理 reshape 操作。这样做的目的是希望潜在的明显特征,如笔画断续、角点,能够出现在最高层特征监测卷积核的中心。
卷积层(C1, C3, C5)。卷积运算的主要目的是使原信号特征增强,并且降低噪音。在一个可视化的在线演示示例中,我们可以看出不同的卷积核输出特征映射的不同,如图所示。
下采样层(S2, S4)。下采样层主要是想降低网络训练参数及模型的过拟合程度。通常有以下两种方式。
最大池化(max pooling):在选中区域中找最大的值作为采样后的值。
平均值池化(mean pooling):把选中的区域中的平均值作为采样后的值。
全连接层(F6)。F6是全连接层,计算输入向量和权重向量的点积,再加上一个偏置。随后将其传递给sigmoid函数,产生单元i的一个状态。
输出层。输出层由欧式径向基函数(Euclidean radial basis function)单元组成,每个类别(数字的0~9)对应一个径向基函数单元,每个单元有84个输入。也就是说,每个输出 RBF 单元计算输入向量和该类别标记向量之间的欧式距离。距离越远,RBF 输出越大。
经过测试,采用 LeNet,6万张原始图片的数据集,错误率能够降低到0.95%;54万张人工处理的失真数据集合并上6万张原始图片的数据集,错误率能够降低到0.8%。
接着,历史转折发生在2012年,Geoffrey Hinton 和他的学生 Alex Krizhevsky 在 ImageNet 竞赛中一举夺得图像分类的冠军,刷新了图像分类的记录,通过比赛回应了对卷积方法的质疑。比赛中他们所用网络称为 AlexNet。
AlexNet
AlexNet 在2012年的 ImageNet 图像分类竞赛中,Top-5错误率为15.3%;2011年的冠军是采用基于传统浅层模型方法,Top-5错误率为25.8%。AlexNet 也远远超过2012年竞赛的第二名,错误率为26.2%。AlexNet 的论文详见 Alex Krizhevsky、Ilya Sutskever 和 Geoffrey E.Hinton 的《ImageNet Classification with Deep Convolutional Neural Networks》。
AlexNet 的结构如图所示。图中明确显示了两个 GPU 之间的职责划分:一个 GPU 运行图中顶部的层次部分,另一个 GPU 运行图中底部的层次部分。GPU 之间仅在某些层互相通信。
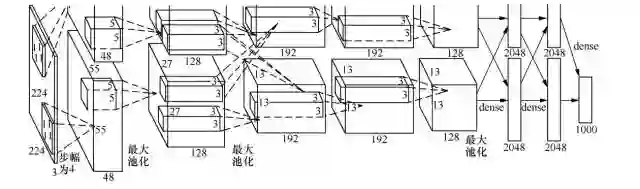
AlexNet 由5个卷积层、5个池化层、3个全连接层,大约5000万个可调参数组成。最后一个全连接层的输出被送到一个1000维的 softmax 层,产生一个覆盖1000类标记的分布。
AlexNet 之所以能够成功,让深度学习卷积的方法重回到人们视野,原因在于使用了如下方法。
防止过拟合:Dropout、数据增强(data augmentation)。
非线性激活函数:ReLU。
大数据训练:120万(百万级)ImageNet图像数据。
GPU 实现、LRN(local responce normalization)规范化层的使用。
要学习如此多的参数,并且防止过拟合,可以采用两种方法:数据增强和 Dropout。
数据增强:增加训练数据是避免过拟合的好方法,并且能提升算法的准确率。当训练数据有限的时候,可以通过一些变换从已有的训练数据集中生成一些新数据,来扩大训练数据量。通常采用的变形方式以下几种,具体效果如图所示。
水平翻转图像(又称反射变化,flip)。
从原始图像(大小为256×256)随机地平移变换(crop)出一些图像(如大小为224×224)。
给图像增加一些随机的光照(又称光照、彩色变换、颜色抖动)。
Dropout。AlexNet 做的是以0.5的概率将每个隐层神经元的输出设置为0。以这种方式被抑制的神经元既不参与前向传播,也不参与反向传播。因此,每次输入一个样本,就相当于该神经网络尝试了一个新结构,但是所有这些结构之间共享权重。因为神经元不能依赖于其他神经元而存在,所以这种技术降低了神经元复杂的互适应关系。因此,网络需要被迫学习更为健壮的特征,这些特征在结合其他神经元的一些不同随机子集时很有用。如果没有 Dropout,我们的网络会表现出大量的过拟合。Dropout 使收敛所需的迭代次数大致增加了一倍。
Alex 用非线性激活函数 relu 代替了 sigmoid,发现得到的 SGD 的收敛速度会比 sigmoid/tanh 快很多。单个 GTX 580 GPU 只有3 GB 内存,因此在其上训练的数据规模有限。从 AlexNet 结构图可以看出,它将网络分布在两个 GPU 上,并且能够直接从另一个 GPU 的内存中读出和写入,不需要通过主机内存,极大地增加了训练的规模。
增强卷积层的功能
VGGNet
VGGNet 可以看成是加深版本的 AlexNet,参见 Karen Simonyan 和 Andrew Zisserman 的论文《Very Deep Convolutional Networks for Large-Scale Visual Recognition》。
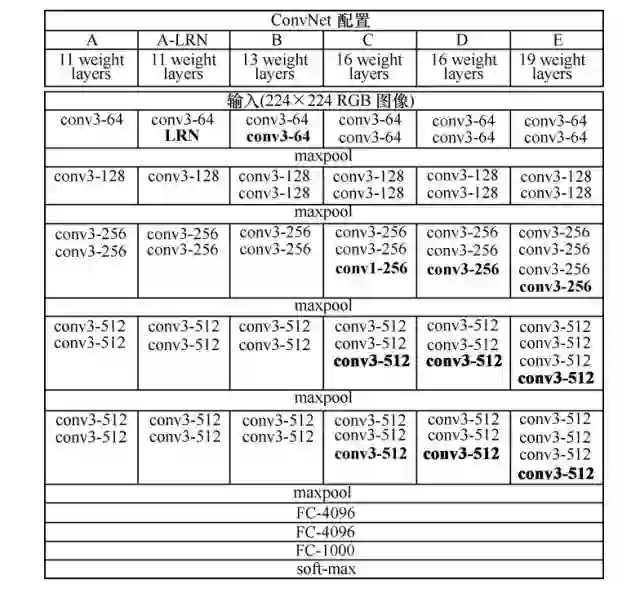
VGGNet 和下文中要提到的 GoogLeNet 是2014年 ImageNet 竞赛的第二名和第一名,Top-5错误率分别为7.32%和6.66%。VGGNet 也是5个卷积组、2层全连接图像特征、1层全连接分类特征,可以看作和 AlexNet 一样总共8个部分。根据前5个卷积组,VGGNet 论文中给出了 A~E 这5种配置,如图所示。卷积层数从8(A 配置)到16(E 配置)递增。VGGNet 不同于 AlexNet 的地方是:VGGNet 使用的层更多,通常有16~19层,而 AlexNet 只有8层。
GoogLeNet
提到 GoogleNet,我们首先要说起 NIN(Network in Network)的思想(详见 Min Lin 和 Qiang Chen 和 Shuicheng Yan 的论文《Network In Network》),它对传统的卷积方法做了两点改进:将原来的线性卷积层(linear convolution layer)变为多层感知卷积层(multilayer perceptron);将全连接层的改进为全局平均池化。这使得卷积神经网络向另一个演化分支—增强卷积模块的功能的方向演化,2014年诞生了 GoogLeNet(即 Inception V1)。谷歌公司提出的 GoogLeNet 是2014年 ILSVRC 挑战赛的冠军,它将 Top-5的错误率降低到了6.67%。GoogLeNet 的更多内容详见 Christian Szegedy 和 Wei Liu 等人的论文《Going Deeper with Convolutions》。
GoogLeNet 的主要思想是围绕“深度”和“宽度”去实现的。
深度。层数更深,论文中采用了22层。为了避免梯度消失问题,GoogLeNet 巧妙地在不同深度处增加了两个损失函数来避免反向传播时梯度消失的现象。
宽度。增加了多种大小的卷积核,如1×1、3×3、5×5,但并没有将这些全都用在特征映射上,都结合起来的特征映射厚度将会很大。但是采用了图6-11右侧所示的降维的 Inception 模型,在3×3、5×5卷积前,和最大池化后都分别加上了1×1的卷积核,起到了降低特征映射厚度的作用。
未完待续……
精选福利
AI科技大本营读者群正在招募,回复“读者群”,添加小助手邀你入群。
回复“深度学习”,一文囊括30篇深度学习精华文章。
回复“机器学习”,一文推荐30篇机器学习优质文章。
回复“访谈”,查看吴喜之、周志华、杨强、蚂蚁金服漆远、今日头条李磊的独家访谈实录。
回复“资源”,一文梳理机器学习,深度学习,神经网络等各方面的资源。
回复“视频”,5分钟的视频带你轻松入门人工智能。
回复“程序员”,带你了解别人家的程序员如何学好AI。
回复“数据”,帮你弄清楚人工智能与数据科学之前的关系。
回复“课程”,跟我一起免费学习:谷歌大脑深度学习&Fast.ai最实战深度学习&David Silver深度强化学习。




