如何入门并成为一名出色的算法工程师?

上周,极客 Live 邀请到了链家网资深算法专家刑无刀、MacTalk 池建强来做分享,主题为:“如何入门并成为一名出色的算法工程师?”
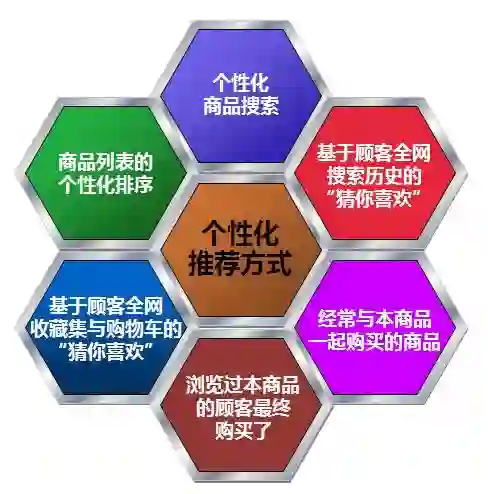
他们从 7 大块方向进行了谈论与扩展:
现推荐系统存在哪些误区?
我是怎样和算法结缘并深耕 8 年?
推荐算法相关学习方法及资料推荐
优秀算法工程师的成长路径是怎样的?
企业喜欢招聘怎样的算法工程师?
介绍及对比推荐算法领域常用的工具及模型
实施推荐系统时遇到的几大问题
现将视频整理成文字,分享给大家。
池建强:麻烦无刀老师给大家解读下,推荐系统最主要的是按用户的点击率去做的推荐算法吗?
刑无刀:这个肯定不是用历史点击率来去排序的,不然新的东西不能得到点击、暴光的机会。不过,最终还是会形成马太效应,就是不管你怎么设置个性化,怎么做算法,你会发现趋势跟热门的趋势会一致的。
一般会在热门趋势的基础上做个性化推荐。实际上,这种买啥推啥的推荐,在业界是有共识的,这样做,确实效果好。
池建强:有时候,系统需要经过很多次测试,才能知道这个用户是否对这个东西感兴趣,但现实中没有这么多机会的,你给用户推荐了两次他不感兴趣的东西,他可能就撤了。那,这种情况下,你怎么去做推荐?
刑无刀:这种情况确实难。如何真正搞清楚用户讨厌什么,喜欢什么,以前我们可能会有些辅助,比如跟产品打配合,他们会做用户调研,或者说通过一些活跃度比较高的用户,去找到这些感兴趣和不感兴趣的点。
但说实话,这算是特征工程的范畴:找到一些有效的特征,哪怕做各种很多人肉的工作。
刑无刀:刚才有人问,国外的推荐系统和亚马逊的推荐系统有什么区别及差距?
我觉得最重要的差别是思维模式上的区别,在做任何策略,或者是做一些尝试的时候,他们首先会想到这个东西怎么去量化,这个效果要定什么指标去评价它。量化,这个很重要。他们基本上会把所有东西都量化下来,然后才开始去思考这件事情怎么做。更多开源的东西,大多数人都可以获取得到,差距并不是特别大,但实际上为什么最后的效果千差万别?
其实,就是大家拿到一样的锤子,如何去用这个锤子?有的人是用砸,有的人是用推等等。就拿锤子这个例子,再说的深入一点。
首先你得看看,你要面对什么样的钉子,你面对什么样的问题。你得定义钉子砸进去的深度,其次是定义钉子的颗数,这是首先要考虑的事情。 我现在链家也是,告诉身边的同事,首先要想清楚怎么定义它,怎么量化它。因为你不量化它,你就没办法优化;没办法优化它,你就没办法控制它。 有人跟我说,我今天尝试了这个算法,效果很好,我就问他,你这个效果好,到底是指什么?是指准确率好,还是指 IUC,还是指什么?
所以,最基本也是最重要的,你得有个量化的标准。 这一点,是我觉得国内外做推荐系统最大的区别。
池建强:评分数据做推荐,为什么大家对评分数据这么关注?
刑无刀:因为大概 10 年前,Netflix 搞了一个瓜分百万美元的推荐算法比赛,他们开放出来的是评分数据,后来在这个基础上延伸了很多推荐算法,都是基于评分数据做得。但实际上有个问题,现实的产品评分数据很难收集。你看到有几个产品能收集到非常好的评分数据,国内最著名的可能是豆瓣的评分系统,用户看完之后还给你评分。这就是一个路径非常深的事情。
产品上收集评分数据是很难的。首先,得让大家去看,花时间花钱去看,这个就有一定难度了,有一定转化率的损失。转化之后,还要用户再回去评个分,那这整个事情得到的评分数据就很少。国内现在做推荐的,就不要太指望评分数据,应该把影视反馈用好,应该把那些用户行为用好。
因为这部分数据,
一是用户在无意识的情况下产生,并不是那么有意识的,更能反映他的兴趣;
二是数据量也非常大;
三是现在很多新的推荐算法,他们都会更关注这种非评分数据。
影视反映的这种数据,我的专栏里有过详细分享,可以去看看。

池建强:你主要用什么编程语言?
刑无刀:C++ 和 Python。我自己的编程母语是 C++,我唯一系统学过的语言就是 C++,之后用的其他编程,都是因为项目需要。Python 的话,确实很方便,库也多,写起来门槛也低,学起来也快。尤其在人工智能这方面,开源的项目,你不用 Python 来写,也不会有人用。
刑无刀:生活所迫。我在实验室的时候就做 NLP,但我并不知道这是什么。后来,我的老师、师兄才跟我说,我们要做事情就是让计算机去理解语言。读完研后,我只会干这个。当时比较流行的是 MFC,做界面开发。说实话,做界面开发,我不太好掌握,而且当时像 MFC 这种非常庞杂的开源框架,它不开源,这种编程框架,我觉得还是有点抵触的。
所以,我只能去投算法类的岗位。七、八年前,算法很不好找工作,也就非常大的公司会招人,比如百度这种非常顶级的互联网公司也只有一个比较小的团队在做算法,市面上没有人去讨论这个东西,没有人知道人工智能,没有人知道推荐系统,甚至没有人知道数据挖掘。
算法在这几年是比较热,也是比较难的一个职业。它并不是说入门门槛特别低,比如说你去写一套界面也好,或者写一套刑无刀 TL 也好,或者做个 IOS,或者做安卓,可能学一学、做做业务就好。但是,算法对数学要求会比较高。
数学和英语是非常重要的。
至于学习书单,在我的专栏最后会出一篇文章,把我写专栏时所参考的论文分门别类地列出来。大家可以关注下。

刑无刀:在 2014 年的时候,我曾经在五道口的一个算法培训班上了半年的课,就是给那些想转行做算法工程师的人讲课,当时也是讲推荐系统。现在回头看,我当时讲的课还是比较浅的,但我发现我们班的学员很努力,课上讲的东西他们都能够吃透。可他们出去找工作的时候,还是会有问题,是什么问题呢?
宏观问题,他们还是脱不开自己以前写功能、写界面的那些编程思维,比如说我所见过的算法工程师,还是不太喜欢用 IDE 去写程序,用 VI 去写程序的人居多。VI 或者 VIM 都可以。
为什么会用这种方式?
我觉得因为 它会让你养成用快捷键,最后形成这种习惯:鼠标是多余的,这时候你写程序会快。
还有一个就是,因为算法的底层东西都是 C++、Python 之类的,C++,其实是在 IDE 里面开发、保管的,但 IDE 对 C++ 的包管理不是那么好。你用 VIM 或者用 VI 这种方式去写会更简单直接一些。
还有算法本身,代码没有那么复杂,你把特征准备好了,输进去,它就吐出一个概率,可能就是一两行代码。这种代码你很少去用 ID,有点像高射炮打蚊子,杀鸡用牛刀。
总结下:多写程序,多看数据。
把体系化的算法,你都会自己去实现一遍。 实现一遍之后,你会非常胸有成竹说这个算法都能干什么事情,都能解决什么问题,你在面对实际问题的时候,你才能把这个东西很好地组合起来。这就是要多写程序,把算法都实现了,不仅是要看懂,还得要实现。
多看数据,就是会发现很多问题、很多规律,会让你做事情是事半功倍的,会解决很多实际的业务问题,你会有成就感,你会不断地再驱使你不断再去学习。
真正算法的东西,书在市面上都有,随便买一本经典的书,然后把上面的算法都实现一遍。
刑无刀:我觉得我跟我的同期人相比,努力程度是一样的,只不过,我有两个方式来检验:我是不是真的懂了这个东西。
第一个是,我是否能把这个东西给别人讲懂,如果能,那我就觉得我是真的懂了。比如,写《推荐系统 36 式》这个专栏的时候,有些地方我写不出来,那肯定就是我不懂,我能写出来一定是我懂了。
第二个就是,用代码把这个算法实现下,哪怕是写一个很简单的代码,你不用考虑性能,不用考虑什么数据量,你只需要把它的逻辑写清楚,然后用自己构造的很小数据去测试。
算法工程师的成长路径是一个升级打怪的过程,并且要不断的去增长建设。
因为升级打怪过程中,你遇到的怪可能会越来越厉害,那么你原来的武艺可能打不过这个怪,就需要提升自己,工作是个很好的成长方式。在完成需求的基础上,想一想如何提高效果,比如,我有几个东西要组合起来去调用,几个组合?谁先谁后?不同的组合就有不同的响应时间,这个过程中,就要你去想办法得到最好的最少的响应时间,这就是一个非常典型的优化问题。推荐系统、机器学习里面,全都是这种优化问题,都可以用算法去解决。
一旦把它量化了,你就会想办法去优化它,优化就会用到算法。
如果你想成为一个算法工程师,应该具备这样的思维及意识的。当你已经成为一个算法工程师之后,你要想办法,不断地盯着那个指标,那个量化的目标。
如果你是一个算法新人,我建议还是多去听一听业界的会议,这些会议有些是收费的,有些是免费的。我个人觉得比较好的是一些公司组织的沙龙及小型的会议,可以参加去长长见识,看看别的公司在用什么,别的公司在解决什么问题。
然后,就是关注一些比较勤奋的人的博客,哪怕他讲得这个东西不是很好,但是他会把这个东西带到你的面前来,是你原来不知道的。
最后一个就是看书。我是建议工程师多看书,盯住比较经典的书,再加上稍微跟一些最新的东西,看看新的东西跟经典的有哪些不一样的地方。
但主要精力,得花在比较困难的事情上。一旦变成自己的,可能很长一段时间都非常受益。
池建强:你挑选一个算法工程师,你会有什么样的要求?
刑无刀:我今天上午面试了一个哈工大的本科生,他真的非常好,比很多研究生博士生都好,他好在哪?
他好在,他对他所做的业务非常熟悉,可以庖丁解牛一样给你分解出来。他分解出来之后,他还能详细地说,我这个东西的问题是什么?我是怎么把问题量化的,之后我拿什么方式去让这个问题变得更轻一点。他会去找很多方法,首先他能够对自己的业务有非常深刻的认识,同时他还能用非常量化的方式去把自己的问题定义出来,接着还能去学习这些算法类的东西,把这些问题解决了。
他在这方面做得非常好。所以说,跟是不是本科生没有关系,还是看自己的努力。
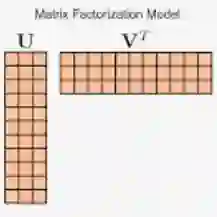
刑无刀:曾经在 ResysChina 公号上一篇文章:推荐算法老司机给的十条经验。这个老司机,是当年组织这个推荐比赛的人,他给的这十条经验,其中有一条说,模型上把矩阵分解这个模型吃透,能解决很多问题。
关于矩阵分解,我的专栏里面大概花三篇时间来讲解这个矩阵分解。
它有这么几个好处:
第一它有协同过滤的作用。因为它本身就是用户和物品之间的关系矩阵去做的,能用协同过滤的地方,你就肯定能用矩阵分解。而且用矩阵分解,就不要再用协同过滤了。
第二它有监督学习的优势。因为矩阵分解里面的每个元素,相当于给你标注数据,这个标注数据就有监督学习的优势。
第三矩阵分解本身分解出来的隐向量。
第四矩阵分析本身比较健壮,不太容易被人攻击。在下周的专栏里,有一篇专门将如何防止推荐系统被攻击。
工具的话,我个人用的工具基本都是 C++ 写的,C++、Python 这一类工具用的会比较多一些,比如能单机解决的事情,不要搞什么分布式了。这也是我自己的理念,我基本上用分布式的时候很少,因为大多数时候,数据量都没有大到要用到分布式、要去用 Spark。
池建强:那真正要上一套系统的时候,我们一般需要注意什么样的问题,或者你有什么经验或者坑分享给大家?
刑无刀:上一个推荐系统,首先就是要去跟业务方约定好,看什么指标,怎么看效果。 上了推荐系统之后,去网上搜用户的抱怨或者夸奖,通过这种方式来验证自己的推荐系统好不好,这是非常糟糕的。因为大部分用户是沉默的,好和不好,用户是不说的。
然后,上线之后,当时推荐系统怎么也着也是个软件系统,是个服务。你把服务那套要求加在它身上完全不为过,比如响应时间啊,都该怎么做就怎么做。原来是怎么测试软件产品,都原样测试下,只是效果这个东西,要通过线上去对比测试去看。
在线下,还有一些比较细微的地方。推荐系统背后都是有些机器学模型的,这个模型背后会有参数,有些规则,这些都是以配置文件的形式存在的。这个东西会定期更新的,代码版本的回滚非常成熟,数据版本的回滚不太好做。
很麻烦,我当时用的那套配置是那套模型,我要回滚到出现问题的时候,代码是可以很快的,Github 这个系统做得很好。你再回滚回去,需要复现推荐系统,当时的那个情况,你很可能复现不出来,因为你的数据没有回滚过去。
池建强:算法用 Python 开发了一套特征后,后端用 Java 开发了,两端对接很费力,这个怎么办?
刑无刀:现在有些团队是在这个上面很困惑,我以前也困惑过,我请教了一些人,分享下他们的做法,以及我们自己尝试的有几种做法。
第一个大家都用 RPC 去交互,它是多语言的,你写的东西是 C++,别人的服务是 Java,那它支持 Java,也支持 C++,你在你这边生成一个 C++ 的接口,你给他生成一个 Java 的接口,照样可以用。
第二个双方就约定好就用 ITP 去调用。我们现在就是这种方式。
第三个模型用一些标准的协议。用一些标准的协议把它存下来,我在某篇专栏里讲了这个东西,常用的 PML 文件这种东西,这种东西有点像 XML 这种方式。
最后,无刀老师专栏的书单论文,会在专栏的最后一期分享给大家,有兴趣的,可以扫码或点击阅读原文,订阅此专栏《推荐系统 36 式》。