如何成为一名推荐系统工程师
转自:人工智能头条
推荐系统工程师技能树
掌握核心原理的技能
数学:微积分,统计学,线性代数
周边学科:信息论基础
推荐算法:CF,LR,SVM,FM,FTRL,GBDT,RF,SVD,RBM,RNN,LSTM,RL
数据挖掘:分类,聚类,回归,降维,特征选择,模型评价
实现系统检验想法的技能:
操作系统:Linux
编程语言:Python/R, Java/C++/C,sql,shell
RPC框架:thrift, Dubbo,gRPC
web服务:tornado, django, flask
数据存储:redis, hbase, cassandra, mongodb, mysql, hdfs,hive, kafka, elasticsearch
机器学习/深度学习:Spark MLib,GraphLab/GraphCHI,Angel,MXNet,TensorFlow,Caffe, Xgboost,VW,libxxx
文本处理:Word2vec,Fasttext,Gensim,NLTK
矩阵分解:Spark ALS,GraphCHI,implicit,qmf,libfm
相似计算:kgraph, annoy,nmslib, GraphCHI, columnSimilarities(spark.RowMatrix)
实时计算:Spark Streaming, Storm,Samza
为效果负责的技能
熟悉常见离线效果指标:准确率,召回率,AUC,基尼系数
能够定义产品效果指标:点击率,留存率,转换率,观看完整率
会做对比试验并分析实验结果:指标数据可视化
知道常见推荐产品的区别:Feed流推荐,相关推荐,TopN推荐,个性化推送
其他软技能
英文阅读;读顶级会议的论文、一流公司和行业前辈的经典论文和技术博客,在Quora和Stack Overflow上和人交流探讨;
代码阅读;能阅读开源代码,从中学习优秀项目对经典算法的实现;
沟通表达;能够和其他岗位的人员沟通交流,讲明白所负责模块的原理和方法,能听懂非技术人员的要求和思维,能分别真需求和伪需求并且能达成一致。
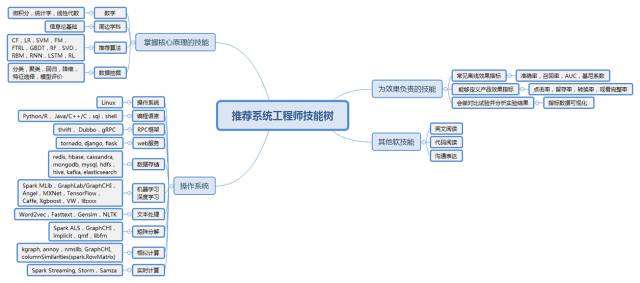
图1 推荐系统工程师技能树
推荐系统工程师成长路线图
《Item-based collaborative filtering recommendation algorithms》这篇文章发表于2001年,在Google学术上显示,其被引用次数已经是6599了,可见其给推荐系统带来的影响之大。
经过20多年的发展,item-based已经成为推荐系统的标配,而推荐系统已经成为互联网产品的标配。很多产品甚至在第一版就要被投资人或者创始人要求必须“个性化”,可见,推荐系统已经飞入寻常百姓家,作为推荐系统工程师的成长也要比从前更容易,要知道我刚工作时,即使跟同为研发工程师的其他人如PHP工程师(绝无黑的意思,是真的)说“我是做推荐的”,他们也一脸茫然,不知道“推荐”为什么是一个工程师岗位。
如今纵然“大数据”, “AI”,这些词每天360度无死角轰炸我们,让我们很容易浮躁异常焦虑不堪,但不得不承认,这是作为推荐系统工程师的一个好时代。
推荐系统工程师和正常码农们相比,无需把PM们扔过来的需求给像素级实现,从而堆码成山;和机器学习研究员相比,又无需沉迷数学推导,憋出一个漂亮自洽的模型,一统学术界的争论;和数据分析师相比,也不需绘制漂亮的图表,做出酷炫的PPT能给CEO汇报,走上人生巅峰。
那推荐系统工程师的定位是什么呢?为什么需要前面提到的那些技能呢?容我结合自身经历来一一解答。我把推荐系统工程师的技能分为四个维度:
掌握核心原理的技能,是一种知其所以然的基础技能;
动手能力:实现系统,检验想法,都需要扎实的工程能力;
为效果负责的能力:这是推荐系统工程师和其他工种的最大区别;
软技能:任何工程师都需要自我成长,需要团队协作。
英文阅读:读顶级会议的论文、一流公司和行业前辈的经典论文和技术博客,在Quora和Stack Overflow上和人交流探讨;
代码阅读:能阅读开源代码,从中学习优秀项目对经典算法的实现;
沟通表达:能够和其他岗位的人员沟通交流,讲明白所负责模块的原理和方法,能听懂非技术人员的要求和思维,能分别真伪需求并且能达成一致。
掌握最最基础的原理
托开源的福气,现在有很多开箱即用的工具让我们很容易搭建起一个推荐系统。但是浮沙上面筑不起高塔,基础知识必须要有,否则就会在行业里面,被一轮轮概念旋风吹得找不着北。所有基础里面,最最基础的当然就是数学了。
能够看懂一些经典论文对于实现系统非常有帮助:从基本假设到形式化定义,从推导到算法流程,从实验设计到结果分析。这些要求我们对于微积分有基本的知识,有了基本的微积分知识才能看懂梯度下降等基本的优化方法。
概率和统计知识给我们建立起一个推荐系统工程师最基本的三观:不要以是非绝对的眼光看待事物,要有用不确定性思维去思考产品中的每一个事件,因为实现推荐系统,并不是像实现界面上一个按钮的响应事件那样明确可检验。大数据构建了一个高维的数据空间,从数据到推荐目标基本上都可以用矩阵的角度去形式化,比如常见的推荐算法:协同过滤、矩阵分解。
而机器学习算法,如果用矩阵运算角度去看,会让我们更加能够理解“向量化计算”和传统软件工程里面的循环之间的巨大差异。高维向量之间的点积,矩阵之间的运算,如果用向量化方式实现比用循环方式实现,高效不少。建立这样的思维模式,也需要学好线性代数。
原文链接:
https://m.weibo.cn/1402400261/4175682756483267