论文浅尝 - ICLR 2020 | 用于文本推理的神经模块网络
论文笔记整理:邓淑敏,浙江大学在读博士,研究方向为低资源条件下知识图谱自动化构建关键技术研究。

论文链接:https://openreview.net/pdf?id=SygWvAVFPr
Demo链接: https://demo.allennlp.org/reading-comprehension
代码链接: https://nitishgupta.github.io/nmn-drop/
这篇文章解决的任务是复杂问题问答,比如回答“谁在第二节比赛中得到最高分?”类似的问题。解决这个任务需要:理解问题->在蕴含答案的文本中做信息抽取à符号推理,所以问题的难点也显而易见:(1)理解问句语义,将复杂问题拆分成简单问题;(2)文本理解,理解文本中实体、关系和事件等;(3)进行推理,比如判断大小,计数等。传统的方法比如语义解析,或者pipeline的模型,要么需要基于结构化或半结构化数据去做,要么在子任务中依赖更多的监督信号,这对复杂问题问答任务来说都很难实现。因此这篇文章提出用神经模块网络去解决这个问题,先将问题解析成logicalform,然后在文本中运行可执行的模块。这里的模块可看成用于推理的可学习的函数。

模块概览
复杂问题问答包含的推理可分为两大类:自然语言推理和符号推理。自然语言推理可以看成是文本信息抽取的过程,符号推理就是基于抽取出的结构化知识进行推理判断。这两大类推理中定义的模块如上图所示。
下面看一个用神经模块网络解复杂问题问答的例子。
第一步:将问题解析成logicalform。

将问题解析成logicalform
第二步:在蕴含答案的文本中执行模块。

模块运行的最终结果

执行第一个模块:find(),找出得分这个实体

执行第二个模块:find-num(),找出得分的数值

执行第三个模块:max-num(),找出最大的得分值

执行第四个模块:extract-argument(),找出得到最大得分的人,这个模块类似于事件抽取中的argumentextraction
那接下来的问题就在于,如何组合这些模块,以及如何学习出这些模块。组合这些模块目前主要用一些seq-to-seq的模型,至于学习这些模块,下面给出学习find()模块的示例。
问题的嵌入用Q表示,蕴含答案的文本嵌入用P表示,find(Q)->P,输入问句的tokens,输出蕴含答案的文本中和输入tokens相同或相似的token分布,如下图所示

find(Q)->P示例
具体做法就是先计算一个“问题-蕴含答案文本”的相似度矩阵
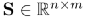
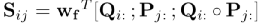
然后按行标准化S,得到“问题-蕴含答案文本”的权重矩阵
最后得到蕴含答案文本的token权重分布:
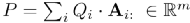
其他模块的做法这里就不赘述了,可以参见原文。
本文的实验用了DROP数据集(https://www.aclweb.org/anthology/N19-1246.pdf),实验结果如下
实体预测的实验结果比较


由于篇幅限制省略了一些细节,如果大家对这篇文章的工作感兴趣,可以阅读原文,也欢迎一起交流。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。



