赛尔原创@AAAI 2022 | 基于概率软逻辑的无偏时序常识知识推理
论文名称:Mitigating Reporting Bias in Semi-supervised Temporal Commonsense Inference with Probabilistic Soft Logic 论 文 作 者 : 蔡碧波,丁效,陈薄文,杜理,刘挺 原 创 作 者 : 蔡碧波 转 载 须 标 注 出 处 : 哈 工 大 S C I R
1. 简介
时序常识知识对于理解自然语言中的事件相关的时序概念十分重要。对于人而言,其可以轻易的理解文本中隐式的时序概念。例如,我们可以轻易的知道“洗个冷水澡可以很快的让你清醒过来”中的“很快”指的是若干秒钟,而“这个小乡村会很快成为一个国际大都市”中的“很快”指的是“若干年”。这是因为人们对事件发展的“持续时间”有着基本的概念,而这种时序常识知识却是当前的人工智能系统所欠缺的。具体的,对应于事件的不同的时序维度,时序常识知识也可以分为不同的类型,例如事件的持续时间、发生频率,典型的发生时间等等。
为了让模型能够掌握相关的时序常识知识以提高其在下游自然语言理解任务上的性能,前人的典型做法是,首先基于弱监督的方法(如模版匹配)从海量的自然语言文本中获取显式表达了时序常识的自然文本,然后基于富时序常识的自然文本来对预训练模型重新训练。例如对于自然文本,“我打了两个小时的篮球”,可以将其形式化为(事件,常识类型,文本值)的三元组,即(我打篮球,持续时间,两小时),针对该类型数据,可以为其设计特定的预训练方案,以达到为预训练模型注入时序常识的目的。
但是,通过弱监督方法获取的富时序常识的自然文本往往面临着“报告偏差(Reporting Bias)[1]”的问题。即,为了更高的沟通效率,习以为常的事情往往在文本中并不会显式的提及,而特殊情况往往在文本中被强调。例如,对于事件“起床”,其典型的持续时间应该是若干分钟,然而,我们几乎不会以口头或者书面的形式作类似“我今天花了1分钟的时间起床”的表达,反而是“我每天都得花1小时才能起床!”这样的特殊情况在日常生活中更为多见。因此,将这种含有偏差的时序常识知识注入预训练模型,会导致模型本身的偏差,其往往也不能在下游任务中有良好的性能表现。
2. 动机
为了应对报告偏差问题,前人工作中提出的一种方案是,可以利用在不同类型的时序常识知识之间的互补性。以下图为例:

图1 不同类型时序常识知识间的互补性
其中,第一句话阐明了事件“get up”与事件“brown the meat”在发生时间上的“包含关系”,即事件“gets up”在事件“brown the meat”发生的过程中发生,另外,第二句话告诉我们,事件“brown the meat”的“持续时间”约为“15分钟”,基于这两条事实,我们可以推理出“get up”的持续时间可能是小于“15分钟”的。因此,尽管在文本中我们往往观察到的表述是“我花了一个小时的时间才能起床”,我们依然有可能利用这种互补性,给出更准确的估计结果。除此之外,在“持续时间”维度与“发生频率”维度之间即存在着倒数关系,尽管文本中并未显式提及“brown the meat”的发生频率,我们依然可以估计出其发生频率应当慢于“每分钟一次”。
然而,前人工作是以隐式的方案来建模这种互补关系[2]。他们依赖于如下的假设:通过在同一个编码器中联合学习多种类型的时序常识知识,即可以隐式的捕捉到这种在不同类型知识之间的互补关系。然而,其仅仅以经典的掩码语言模型损失作为模型的优化目标,而并没有显式的对这种互补关系进行约束,所以这个假设可能并不成立。同时,这种不充分的建模方法也存在着不可解释的问题,限制了在下游任务中的应用。
为了解决这个问题,在本工作中,我们提出了一种基于神经符号的时序常识推理模型SLEER。不同于前人的纯数据驱动的训练思路,我们提出为模型增添额外的软逻辑正则模块,其可以以一种端到端的方法,使得模型能够掌握“互补关系”这种抽象知识,给出逻辑一致的推理结果,以达到减轻报告偏差的目的。其具体实现思路有如下两点:
-
将潜在的不同类型间的时序常识知识之间的约束关系以一阶逻辑的方式明确的表达出来。通过系统总结人所掌握的时序常识知识,我们将各个类型的时序常识之间的约束总结为下表。具体的,本文针对每一个类型的时序常识定义其相应的谓词及其论元,例如,持续时间类型对应的谓词为DUR。每个谓词都对应两个论元,分别是事件以及标签值。例如,原子式DUR( ,year )即代表事件 的持续时间为若干年。
表1 概率软逻辑规则
-
基于概率软逻辑(Probabilistic Soft Logic)的理论,将这些一阶逻辑关系的约束转化为模型的损失函数的一部分,且处处可微。概率软逻辑理论中,其认为原子式的真值可以是0到1之间的任意值,并且定义了由不同逻辑运算符组合原子式所得到的逻辑规则的真值的运算法则。而逻辑规则的真值,即代表了其成立与否的概率。在本文中,我们正是通过优化模型的预测结果使得其满足逻辑规则,使得模型给出逻辑一致的预测结果。

3. 实现方法
3.1 富时序常识的文本数据获取
仿照前人工作[2],也是为了进行公平比较,本文同样采用了基于弱监督的方式获取富时序常识的文本数据,并将其进行初步处理以获取模型的预训练数据。
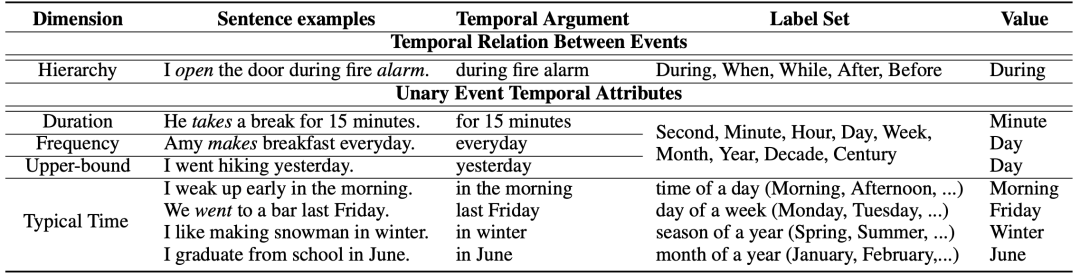
具体的,我们关注了5个类型的时序常识,即事件层级(Event Hierarchy),持续时间(Duration),频率(Frequency),典型发生时间(Typical Time)和持续时间上限(Duration Upper-bound)。其中,事件层级描述的是事件对之间的时序交叠、先后关系,其余的常识类型均描述的是单一事件的某一特定的维度的一元属性,其含义均与其字面意义相同。特别的,“持续时间上限”这一类型也对减轻报告偏差有着积极意义,例如,“我昨天去游泳了”,表明“游泳”这一事件的持续时间应当短于“一天”。
该文本数据随之被进一步处理为(事件上下文,常识类型,标签值)的三元组。这里,所谓的“标签值”指的是,对于每一种常识类型,都预定义了一系列的标签集,在文本中显式表达的时序数值会被归一到标签集中最邻近的时间单元中。例如,“15分钟”和“50秒”都会被归一化为“分钟”。下图展示了所有类型的数据的抽取和归一化的样例。在经过归一化后,学习事件相应的时序常识知识即可视为在给定标签集上的多类别分类任务。
表2 无监督抽取时序常识数据的样例
3.2 预训练方案
如下图所示,本文提出的SLEER模型包含两个模块,即一个多任务的编码器和一个软逻辑正则的模块。对于给定的输入事件,多任务编码器给出其各个类型的时序常识在预定义标签集上的分布结果;而软逻辑正则模块对多任务编码器的输出结果进行约束,通过端到端的优化方式,使其能够给出逻辑一致的推理结果。
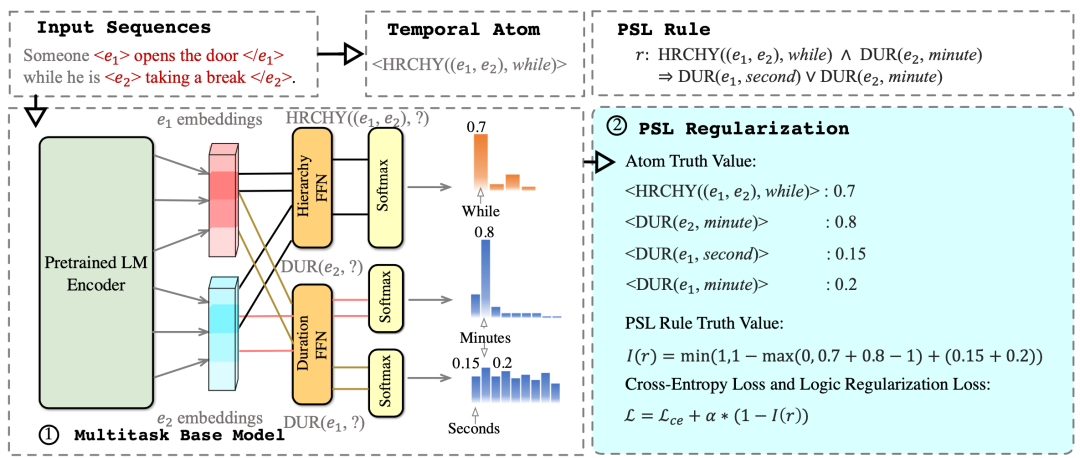
图2 SLEER模型架构
多任务编码器 多任务编码模型包含了一个公共的事件编码器(由预训练语言模型实现),和五个任务特定的输出层,其中,每个输出层对应于一个特定类型的时序常识。对于事件层级类型的自然文本,我们将输入句中的包含在相应标签集中的关键词(即when,while,before,after, during)替换为[MASK],并将该掩码对应的隐层表示作为后续输出层的输入;而对于其他的维度,我们则直接在预处理阶段,去除了文本中的时序知识相关的表述,并将事件的触发词位置所对应的隐层表示作为事件的表示,输入后续的输出层。所有的输出层的输出结果均为在相应类型时序常识的标签集上的分布,并以交叉熵损失进行优化。我们将这部分损失函数统称为 。
软逻辑规则 本文系统的总结了各种时序常识规则,并将其以一阶逻辑的语言进行表达,以充分的建模在不同类型时序常识知识间的互补关系。这里我们以一个运行例子来概述逻辑规则的表达方法。
若事件1在事件2发生的过程中发生,则事件1的持续时间短于事件2
对如上的以自然语言表达的规则,我们可以将其转化为如下的一阶逻辑规则,即:

这里的三个公式从左到右依次代表,事件1事件2在发生时序上为“包含关系”(即事件1在事件2发生过程中发生);事件2的持续时间为“若干分钟”;事件1的持续时间应短于“若干分钟”。在概率软逻辑理论中,将前两者称作为原子式(Atom formulae),其真值可以直接由上述的多任务编码器给出(即在对应维度的对应标签上的预测概率);而最后一项为复杂式(Complex formulae),其可以拆分为若干原子式由逻辑或运算符进行逻辑组合,即,
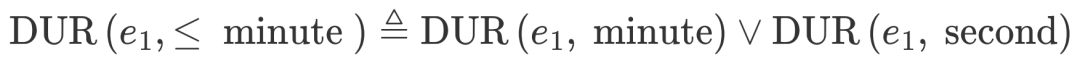
特殊的,一阶逻辑规则本身也可以视作是一种复杂式(逻辑蕴含也是一种特定的逻辑运算符)。
软逻辑理论的一个重要内容即是给出复杂式的真值计算方法。在下表中,给出了将原子式通过逻辑运算符进行逻辑组合时,对应于Łukasiewicz t-norm的软真值的计算过程[3]。
表3 Łukasiewicz t-norm软真值计算公式

通过迭代的运用这些计算规则,即可计算出上述所有包括逻辑规则本身在内的复杂式被满足的分数(即软真值)。
软逻辑约束模块 为了达到使得模型的预测分布与逻辑约束相一致的目标,本文进而将上述的一阶逻辑约束关系转化为处处可微的损失函数。具体的,给定一条训练数据,我们首先收集与该训练数据相关的所有逻辑规则,表示为
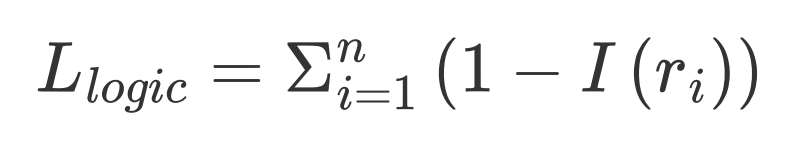
最后的模型的总的损失函数即由下式给出,其中 为超参数。
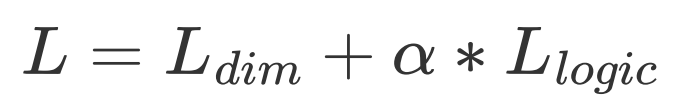
4. 实验结果
为了更好的评估模型的性能,本文中进行了两个类型的实验。其一为内部任务评价(Intrinsic Evaluation),我们以zero-shot的方式,评估当将我们的模型作为一种离线的知识库时,预测事件的时序属性的准确度。其任务形式即为事件的时序属性预测,是一种分类任务,即给定目标事件和相应的时序常识类型,模型给出其在对应的标签集上的时序分布。其二为外部任务评价(Extrinsic Evaluation),我们评估当该模型作为一种广义上的预训练模型的性能。即根据特定的下游任务,我们为模型添加特定的任务分类层,并在下游任务的训练集上进行微调,观察其在测试集上的性能表现。
4.1 实验数据集与评价方式
在内部任务评价中,其具体任务均为针对给定事件的特定类型的时序属性预测。仿照前人工作,我们使用“平均距离”作为评价指标,即预测结果与真实标签的距离。这是由于在不同的时间单元之间,其有着不同的相对距离。例如,若事件的真实持续时间为“若干分钟”,则预测为“若干天”应当比预测为“若干小时”的错误程度更高。具体的,规定相邻时间单元的距离为1,于是Dist(hour,day)=1,Dist(second, day)=3,依此类推。
我们将所使用的4个数据集的统计信息总结如下:
表4 数据集统计信息
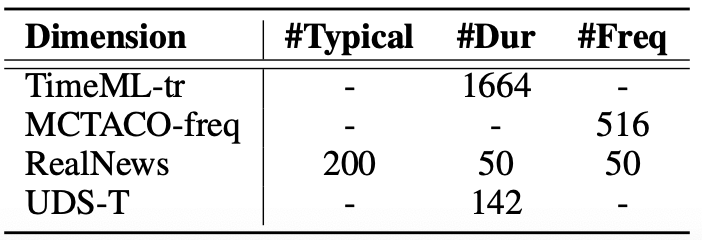
注意,RealNews和UDS-T为在前人工作[2]中所标注的数据集,但是其数据规模过小,难以从统计意义给出良好的模型性能的评估。为此,在现有的两个时序常识数据集基础上,我们进行了筛选及数据样例的修改,使之变为可用于内部任务评价的数据类型。例如,对于一条问答数据,我们将其问题转化为一条陈述语句,将正确答案对应的时间概念归一化为一个标签值,即可完成数据类型的转化。如下表所示。经此方法,我们获得了10倍于RealNews和UDS-T规模的评测数据集。
表5 构造新的时序属性推理数据
| Question | Correct Answer | Question to Statement | Correct answer to time unit |
|---|---|---|---|
| How often do they sleep during the day? | Every-day ✓ | they sleep during the day | 1 / day |
在外部任务评价中,我们引入两个数据集。分别是TimeML和MCTACO。
TimeML TimeML[4]数据集是目前使用最为广泛的预测事件持续时间的数据集之一,其任务是针对给定的事件,预测其持续时间是长于一天还是短于一天。我们使用预测准确率(Accuracy)作为评价指标。
MCTACO MCTACO[5]是一个关于时序常识的问答数据集。其涵盖了5个类型的时序常识的问题,其中3种为本文所关心的事件的时序属性,即持续时间、发生频率和典型发生时间,另外两种是事件的顺序和不变性(Stationary)。我们仅仅使用上述的三种时时序属性类型的问题评测数据。这是由于本文的关注点正是在于减轻从大规模文本中学习到的事件时间属性的报告偏差问题,而另外两种类型的知识并不在考虑之列。我们使用EM(Exact Match,即将一个多项选择问题完全答对方为1)和F1值作为评测指标。
4.2 基线方法
本文将以下方法作为基线模型:
BERT和RoBERTa 我们报告了包括BERT-base和RoBERTa-base在内的预训练模型在相应数据集上的结果
TacoLM[2] 这是一个基于BERT-base实现的时序知识增强的预训练语言模型,是首个探索了在不同类型时序常识知识之间互补性的工作,但是我们认为其隐式的建模这种互补关系的方式存在着不充分和不可解释的问题,这也限制了模型的性能。
4.3 内部任务评价结果
表6 内部任务实验结果

在两个规模较大的数据集,即TimeML-tr和MCTACO-freq数据上,我们的SLEER模型取得了显著优于基线模型的方法。而在另外的两个较小规模的数据集RealNews和UDS-T数据集上,可以获得与最优基线方法接近的性能。
4.4 外部任务评价结果
表7 外部任务实验结果
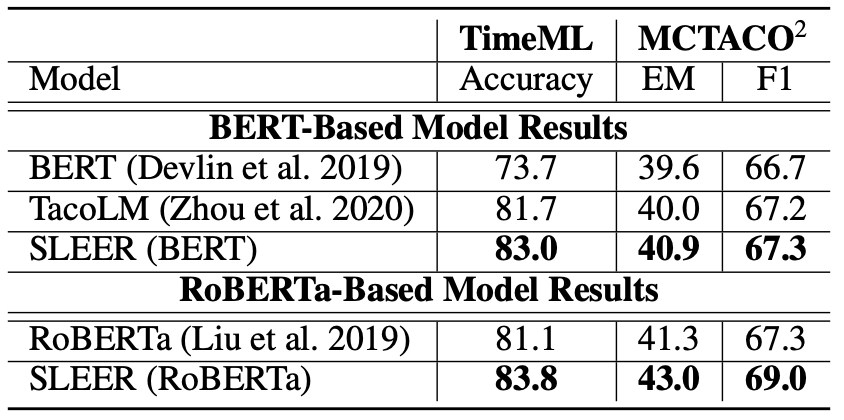
在两个外部任务评价数据集中,我们的SLEER模型均可以产生优于基线模型的结果。值得一提的是,尽管RoBERTa在训练时采用了更大的训练数据,SLEER模型依然可以在其基础上取得进一步的提升,这进一步证实了报告偏差问题的存在性---由于部分时序常识知识在文中并没有出现或是呈现出有偏的分布,仅仅依靠训练数据的堆砌是难以解决的。
4. 结论
在本文中,我们探究了如何减轻在基于大规模文本训练拥有时序常识知识的模型时存在的报告偏差问题。本文提出了一种神经符合结合的推理模型,其通过为模型增添额外的软逻辑正则模块,使得模型能够掌握“互补关系”这种抽象知识,给出逻辑一致的推理结果。我们在内部任务和外部任务上相较于基线方法的实验结果的提升证实了我们方法的有效性。同时,我们的发现也指出,在后续的研究中,应当对在自然文本表达中的报告偏差问题予以重视,如何从自然文本获取无偏的常识知识依然任重道远。
[1] Gordon J and Van Durme B. Reporting bias and knowledge acquisition. AKBC 2013.
[2] Zhou B, Ning Q, Khashabi D, et al. Temporal Common Sense Acquisition with Minimal Supervision. ACL 2020.
[3] Li T, Gupta V, Mehta M, et al. A Logic-Driven Framework for Consistency of Neural Models. EMNLP 2019.
[4] Pan F, Mulkar R, and Hobbs J R. Extending TimeML with Typical Durations of Events. ARTE 2006
[5] Zhou B, Khashabi D, Ning Q, et al. “Going on a vacation” takes longer than “Going for a walk”: A Study of Temporal Commonsense Understanding. EMNLP 2019.
本期责任编辑:刘 铭
理解语言,认知社会
以中文技术,助民族复兴

