Uber发布的CoordConv遭深度质疑,“翻译个坐标也需要训练?”
圆栗子 编译自 blog.piekniewski.info
量子位 报道 | 公众号 QbitAI
前几天,Uber AI实验室发布了一篇非常瞩目的论文,说卷积神经网络 (CNN) 在一些很简单很直接的任务里面,会失守。
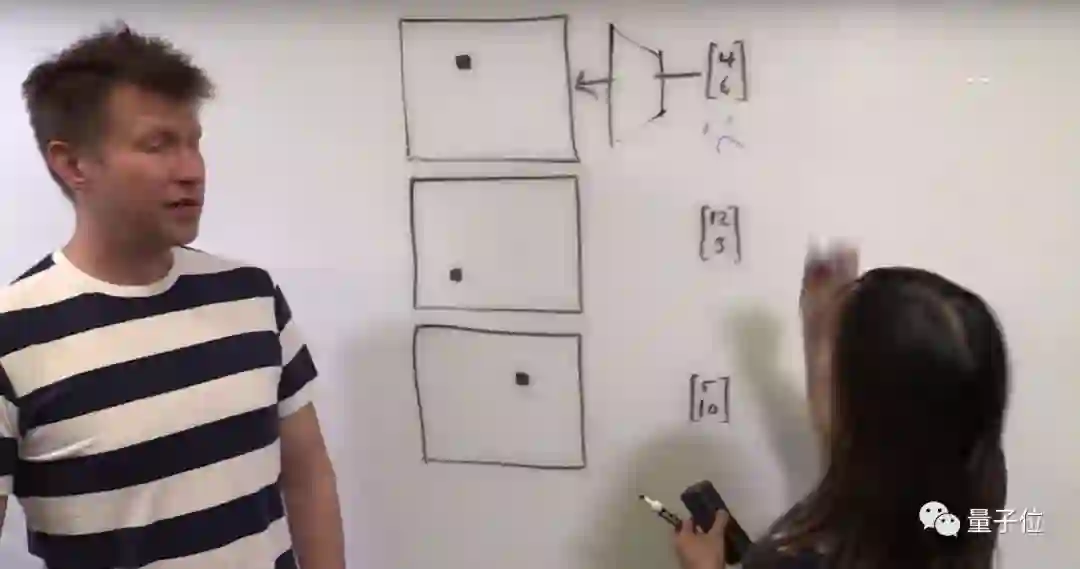
比如,一张白色图片,上面有个黑点。给CNN喂食这个点的 (i,j) 坐标,它就是画不出原来那幅图。
总结起来,监督渲染、监督坐标分类,以及监督回归,对CNN来说都是大难题。
于是,团队提出了CoordConv,来回收这些失陷的领土。
不过很快,这篇论文,和拯救CNN的主角CoordConv,就被一篇有点长的博文“鞭尸”了。
博客的主人Filip Piekniewski (暂称菲菲) 说,他给这项研究做了尸检。
加个特征,而已
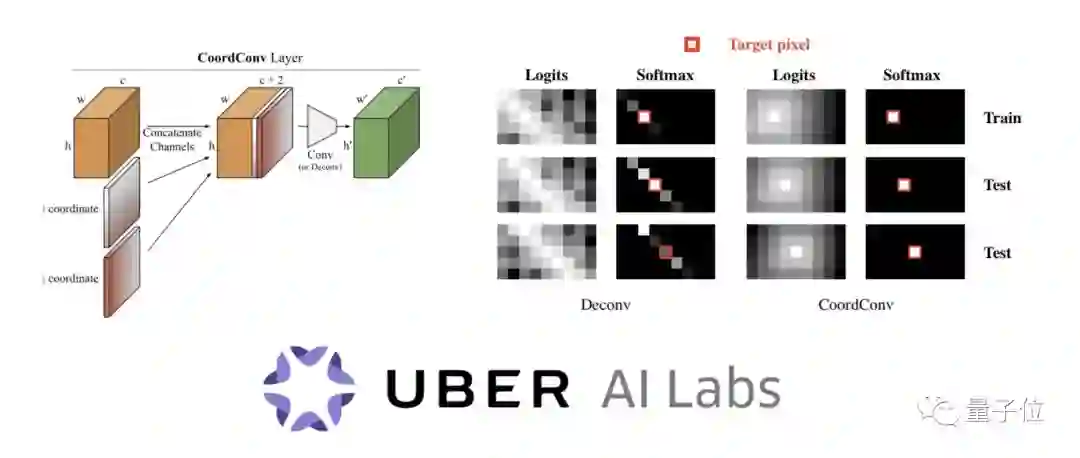
首先,关于 (上文白纸黑点) 定位问题,Uber团队发现,CNN不擅长把笛卡尔坐标 (i,j) 转换成独热像素空间 (One-Hot Pixel Space) 里的位置。
菲菲提到,CNN的结构,从福岛邦彦新认知机 (Neocognitron) 的年代开始,基本就设计成“忽略位置”的了。
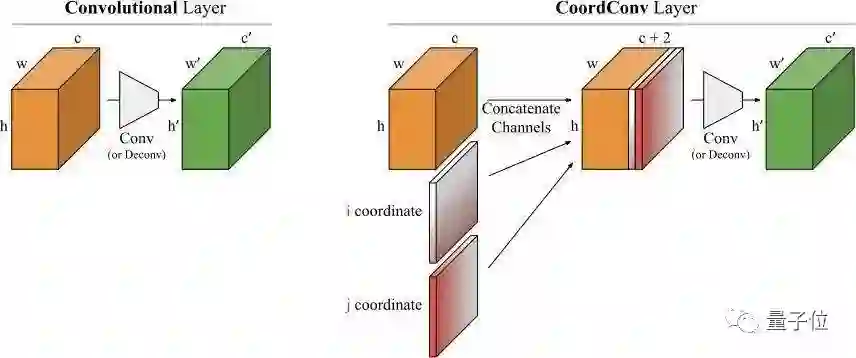
而CoordConv要做的,就在给神经网络的输入里,加上两个坐标通道,一个i一个j,明确告诉AI哪是哪。
果然很有道理啊。可是……
总感觉,随便一个小伙伴在实操的时候,都能对CNN做个类似的小加工,就是加个特征,解码起来更舒服嘛。
菲菲说,做计算机视觉的同行们,没有人会觉得加了几个特征就是不得了的事情。

△ 平平无奇
虽然,有一个非常火热纯学术辩题,就是一些学者认为,大家只应该用那些学习到的特征 (Learned Features) ,而经济实用派的选手们不同意。
从这个角度上来说,如今现在深度学习圈的人们,也开始认同特征工程 (Feature Engineering) 了,可以可以可以。
训练成果,啊这也需要训练?
加了一层坐标之后,团队就测试了一下神经网络的表现。
可爱的是,这里用的数据集名字叫“Not-So-Clevr”。

任务就是,用坐标生成独热图像,以及用独热图像生成坐标。
结果表明,神经网络的性能确实比没加那一层的时候,好了一些。
不过,如果这些人不要那么激动,坐下冷静冷静,可能就会发现,直接搭一个能把笛卡尔坐标和独热编码互相转换的神经网络,不就好了么?
菲菲有了这个想法,就自己写了一串代码——
1import scipy.signal as sp
2import numpy as np
3# Fix some image dimensions
4I_width = 100
5I_height = 70
6# Generate input image
7A=np.zeros((I_height,I_width))
8# Generate random test position
9pos_x = np.random.randint(0, I_width-1)
10pos_y = np.random.randint(0, I_height-1)
11# Put a pixel in a random test position
12A[pos_y, pos_x]=1
13# Create what will be the coordinate features
14X=np.zeros_like(A)
15Y=np.zeros_like(A)
16# Fill the X-coordinate value
17for x in range(I_width):
18 X[:,x] = x
19# Fill the Y-coordinate value
20for y in range(I_height):
21 Y[y,:] = y
22# Define the convolutional operators
23op1 = np.array([[0, 0, 0],
24 [0, -1, 0],
25 [0, 0, 0]])
26opx = np.array([[0, 0, 0],
27 [0, I_width, 0],
28 [0, 0, 0]])
29opy = np.array([[0, 0, 0],
30 [0, I_height, 0],
31 [0, 0, 0]])
32# Convolve to get the first feature map DY
33CA0 = sp.convolve2d(A, opy, mode='same')
34CY0 = sp.convolve2d(Y, op1, mode='same')
35DY=CA0+CY0
36# Convolve to get the second feature map DX
37CA1 = sp.convolve2d(A, opx, mode='same')
38CX0 = sp.convolve2d(X, op1, mode='same')
39DX=CA1+CX0
40# Apply half rectifying nonlinearity
41DX[np.where(DX<0)]=0
42DY[np.where(DY<0)]=0
43# Subtract from a constant (extra layer with a bias unit)
44result_y=I_height-DY.sum()
45result_x=I_width-DX.sum()
46# Check the result
47assert(pos_x == int(result_x))
48assert(pos_y == int(result_y))
49print result_x
50print result_y
一个卷积层,一个非线性激活,一个加和,一个减法。解决战斗。
他说,这种事情,就别花时间训练了。
100个GPU
论文主体结束之后,正片才开始。
Appendix里面,有这样一个表格。
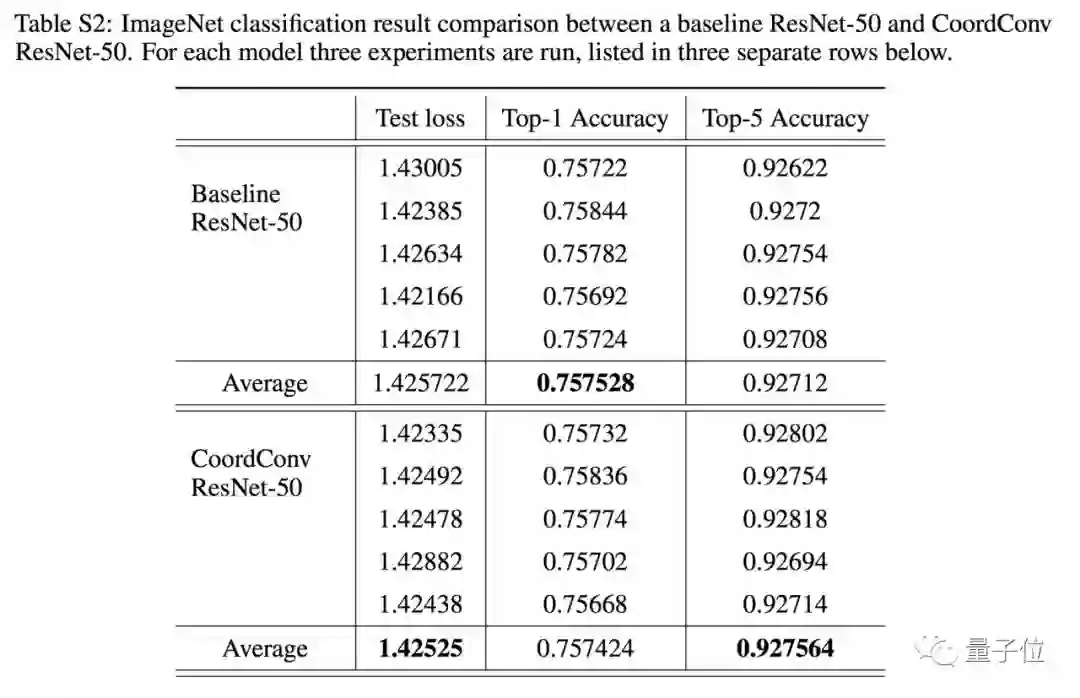
Uber团队拿他们的坐标特征,在ImageNet上搞了一下。
具体做法是,加在了ResNet-50的第一层。
菲菲觉得,这样玩应该没什么X用,因为ImageNet里的类别,根本不是位置的函数。就算开始有这样的偏见,训练中的数据扩增也会把它抹掉了。
令人惊喜的是,研究人员用了100个GPU来训练这个改进之后的神经网络。
结果是,到了小数点后第三位,他们终于获得了微弱的安慰奖。

菲菲说,如果有一万台GPU,大概也是可以用上的,无限风光,在险峰嘛。
真有那么壕的话,不想做点更有意义的训练么?
请开始你的表演
菲菲的嘲讽熔成一句话——
这样的作品,还有人叫好,真让人难过。
那么,你怎么看?
— 完 —
活动报名

实习生招聘
量子位正在招募活动运营实习生,策划执行AI明星公司CEO、高管等参与的线上/线下活动,有机会与AI行业大牛直接交流。工作地点在北京中关村。简历欢迎投递到quxin@qbitai.com
具体细节,请在量子位公众号(QbitAI)对话界面,回复“实习生”三个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态



