【谷歌云AutoML Vision官方教程】手把手教会训练模型解决计算机视觉问题,准确率达94.5%

【2018 新智元 AI 技术峰会倒计时 1 天】
2018 年 3 月 29 日,北京举办的 2018 年中国 AI 开年盛典——新智元产业 · 跃迁 AI 技术峰会,邀请了微软全球技术院士、微软语音、自然语言和机器翻译团队负责人黄学东博士和微软全球杰出工程师张祺博士,解析语音和机器翻译最新突破和人机交互未来趋势,阐释微软 “行业 + AI” 在中国落地的战略布局!想近距离交流互动?点击文末阅读原文,马上参会!
抢票链接:http://www.huodongxing.com/event/8426451122400
爱奇艺直播:http://www.iqiyi.com/l_19rr3aqz3z.html
新智元编译
编译:小潘
【新智元导读】只要三张拉面图,就能识别出每碗拉面是在41家不同拉面店中的哪家制作出来。数据科学家Kenji Doi开发了一种拉面专家AI分类器,它能辨别出不同拉面之间的细微差异。这背后,是谷歌AutoML Vision提供的ML模型。

看下面的三碗拉面。你能相信机器学习(ML)模型能以95%的准确率识别出每碗拉面是在41家拉面店中的哪家制作的么?数据科学家Kenji Doi开发了一种拉面专家AI分类器,它能辨别出不同拉面之间的细微差异。

拉面Jiro是日本最受欢迎的连锁餐厅之一,因为它的配料、面条和汤的价格都很便宜。这个连锁餐厅在东京有41家分店,每家店都有基本相同的菜单。
正如你在照片中所看到的,对于一个刚刚接触拉面的人来说,几乎不可能知道每碗面的制作材料是什么,因为它们看起来几乎是一样的。你不相信自己可以通过看这些照片来辨别这些面到底属于41家餐馆的哪一家。
Kenji想知道深度学习是否能帮助解决这个问题。他从网络上收集了48,244张Jiro做的拉面的图片。在删除了不适合进行模型训练的照片之后(比如重复照片或没有拉面的照片),他为每个餐馆准备了大约1,170张照片,也就是48000张带有商店标签的照片。
当Kenji正在研究这个问题时,他了解到Google刚刚发布了AutoML Vision的alpha版本。
AutoML Vision允许用户在不具备设计ML模型的专业知识的情况下使用自己的图像定制ML模型。首先,你要做的就是上传图像文件进行模型训练,并确保上传数据具有正确的标签。一旦完成了定制模型的训练,您就可以轻松地将其应用到到可扩展的服务平台上,以便通过自动扩展拥有的资源来满足实际需求。整个过程是为那些不具备专业ML知识的非数据科学家设计的。
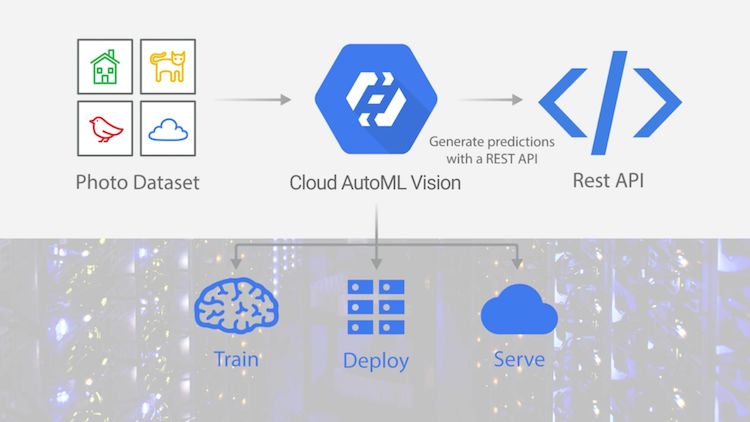
AutoML Vision训练、部署和服务自定义ML模型的过程
当Kenji获得了AutoML Vision的alpha版本后,他试了一下。他发现用带有商店标签的拉面照片作为数据集训练模型时,F值可以达到94.5%,其中精确率未94.8%,召回率为94.5%。
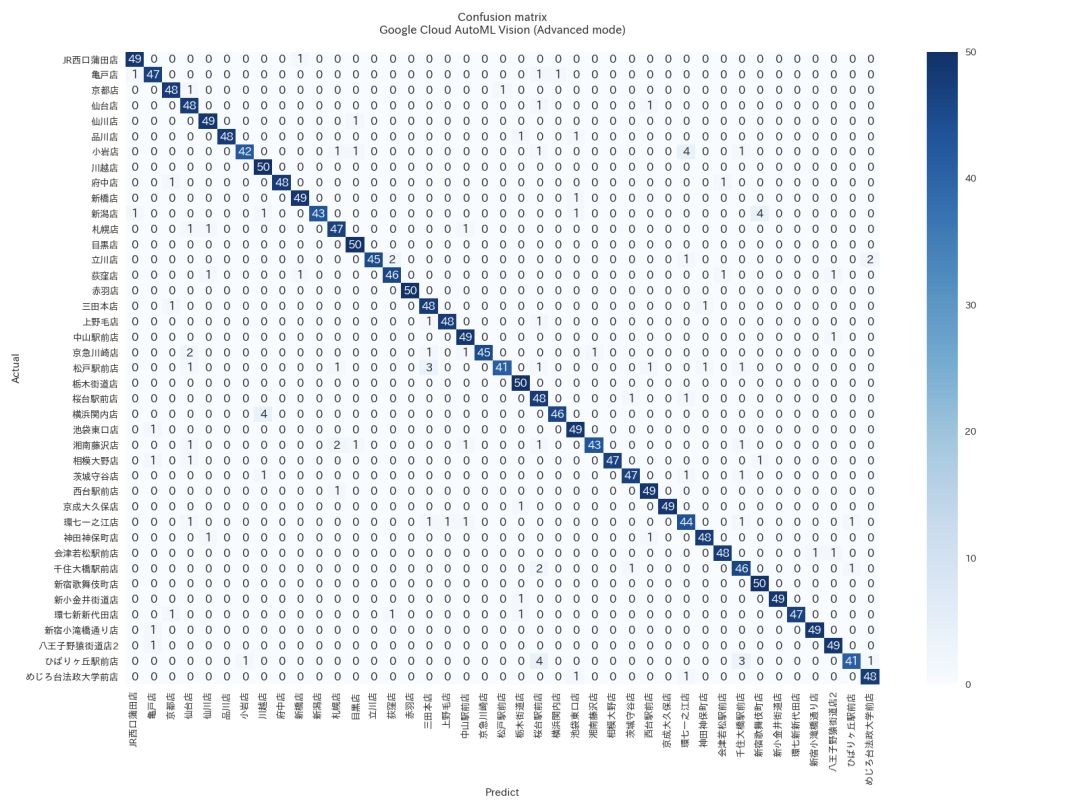
使用AutoML Vision(高级模式)的拉面店分类器的混淆矩阵
(行=实际店铺,栏=预测店铺)
通过观察上图的混淆矩阵,您可以看到AutoML Vision在每个测试样例中,仅仅对几个样本做出了错误的分类。
这怎么可能?每个照片使用AutoML检测区别是什么?Kenji想知道ML模型如何能准确地识别出拉面对应的商店。起初,他认为模型是在看碗,或桌子的颜色或形状。但是,正如你在上面的照片中所看到的,即使每个商店在他们的照片中使用了相同的碗和桌子设计,这个模型也非常准确。Kenji的新理论是,该模型精确地能够区分肉块和浇头的细微差别。他计划继续在AutoML上做实验,看看他的理论是否正确。
在尝试AutoML Vision之前,Kenji花了相当多的时间来为他的拉面分类项目建立自己的ML模型。他仔细地选择了一个通过Inception,ResNetSE-ResNeXt获得的一个集合模型,构建了一个数据增强设置,在超参数调优上耗费了很长的时间,如改变学习率等,并引入他积累的知识作为一个专家知识。
但是,通过AutoML Vision,Kenji发现他唯一需要做的就是上传图片并点击“训练”按钮,仅此而已。通过AutoML Vision,他不费吹灰之力就能够训练一个ML模型。

标记图像集的示例。借助AutoML Vision,您只需上传带有标签的图像即可开始使用
当使用AutoML Vision训练一个模型时,有两种模式任你选择:基本模式或高级模式。在基本模式下,AutoML Vision可以在18分钟之内完成Kenji的训练数据。在高级模式下用了将近24个小时。在这两种情况下,他都没有执行任何超参数调优、数据扩充或尝试不同的ML模型类型。一切都是自动化处理,不需要拥有相关的专业知识。
据Kenji说,“在基本模式下无法获得最优的准确性,但是可以在很短的时间内得到一个粗略的结果。而高级模式可以在用户不进行任何优化或具备任何学习技能的情况下获得最优的精度。这样看来,这个工具肯定会提高数据科学家的生产力。数据科学家们已经为我们的客户进行了太多的人工智能解答,因此,我们必须尽快将深度学习应用到PoCs上。有了AutoML Vision,数据科学家就不需要为了获得最优的模型结果花很长时间来培训和优化模型获。这意味着即使只有拥有限数量的数据科学家,企业也可以扩大他们的人工智能产业。”
他喜欢AutoML Vision还有因为其另外一个特点:“AutoML Vision太酷了,你可以在训练后使用它的在线预测功能。而这项任务对于数据科学家来说通常是特别耗时的,因为必须要将模型部署到生产服务环境中后,再对其进行管理。”
AutoML Vision在另一个不同的用例中也证明了它的能力:对产品进行品牌分类。Mercari是日本最受欢迎的销售APP之一,它在美国也受到越来越多人的青睐,它一直在尝试通过闪频的图片自动识别其品牌。

Mercari官网
在日本,Mercari推出了一款名为Mercari MAISONZ的新App,用于销售品牌商品。Mercari在这款应用中开发了自己的ML模型,在用户的图片上传界面中,该模型可以对12个主要品牌的商品进行分类。该模型使用了VGG16在TensorFlow上的迁移学习,准确率达到75%。

正如ML模型预测的那样,用户上传图片界面显示了品牌名称
而当Mercari在AutoML Vision的高级模式下尝试用5000个训练来进行训练,它达到了91.3%的准确率。这比他们现有的模型高出了15%。
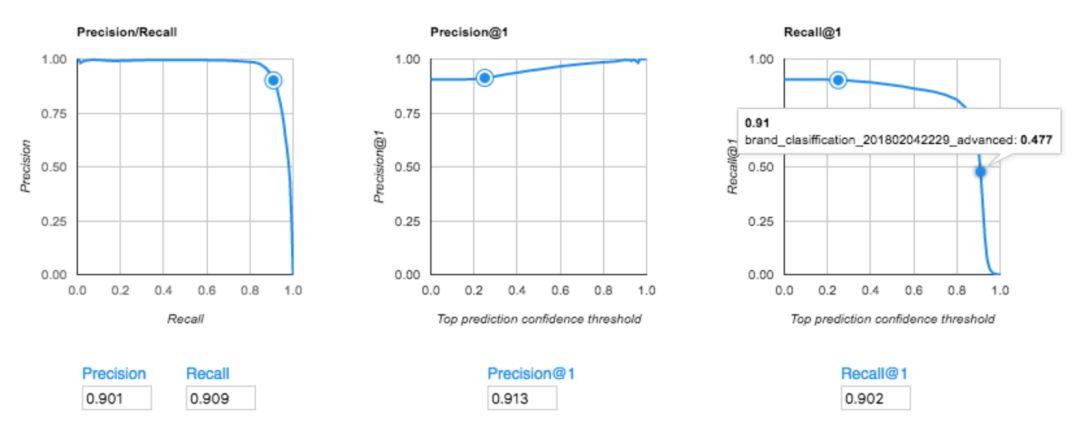
Mercari的AutoML Vision模型(高级模式)的准确性分数(精确度/召回率)
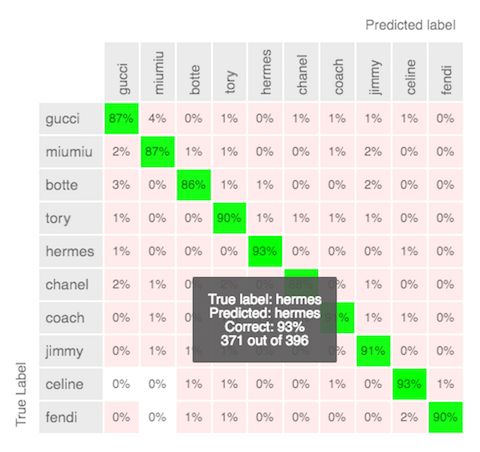
Mercari的AutoML Vision模型的混淆矩阵(高级模式)
Mercari的数据科学家Shuhei Fujiwara对这个结果感到非常惊讶,他说:“我无法想象谷歌是如何做到如此高精度的!”
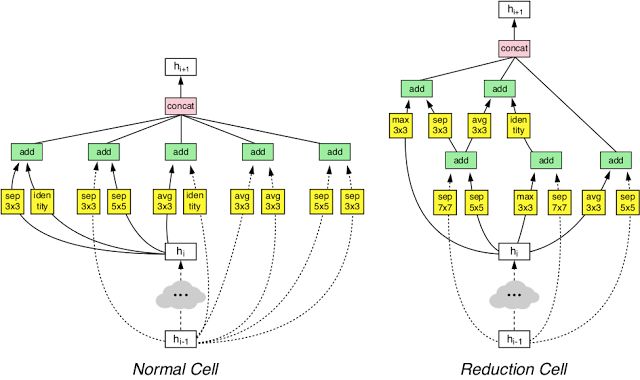
用于大规模图像分类和对象检测的AutoML
高级模式里面,除了转移学习还有什么呢?实际上,其中还包括谷歌的学习技术,特别是NASNet。
NASNet使用ML来优化ML:元级ML模型试图为特定的训练数据集获得最佳的深度学习模型。这才是高级模式的秘密,它代表了谷歌的“人工智能”哲学。这项技术可以让用户在不用长时间学习人工智能的情况下,充分地利用最先进的深度学习能力。
Shuhei还很喜欢这项服务的用户界面。“它很容易使用,你不需要对超参数优化做任何的人工处理,而且在UI上的一个混淆矩阵也为用户来带了方便,因为它可以帮助用户快速检查模型的准确性。该服务还允许你将最耗时的人工标记工作交给谷歌。因此,我们正在等待公测版本取代现有的自动化版本,这样就可以将其部署到生产环境中了。”
正如我们在这两个例子中所看到的,AutoML Vision已经开始在现实用例中体现它的价值了。要了解更多信息,请访问AutoML Vision的产品页面:
https://cloud.google.com/automl/
【2018 新智元 AI 技术峰会倒计时 1 天】
点击阅读原文查看嘉宾与日程
峰会门票火热抢购,抢票链接:
http://www.huodongxing.com/event/8426451122400
【扫一扫或点击阅读原文抢购大会门票】


