EMNLP 2022 | RAPO: 基于自适应排序学习的双语词典归纳


收录会议:
论文链接:
代码链接:

基于不同语言间词向量空间的同构性假设 [1],以前的方法 [2] 往往使用线性变换作为映射函数来保持空间的同构关系,并在此基础上通过增加正交限制 [3]、正则化词向量 [4]、迭代扩充词典 [5] 等方式来提高单词翻译的准确率。

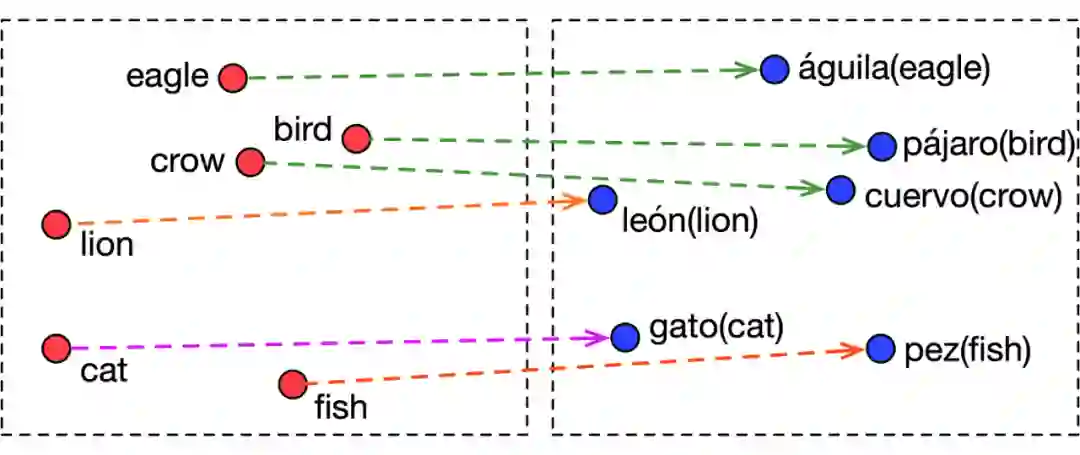
▲ 图1:部分单词(英语与西班牙语)在词向量空间的映射关系
但实际上,我们认为 BLI 本质上是一个排序的问题,而不是上述训练目标定义的回归问题。因为 BLI 的目标是:对于每一个源语言中的词,寻找目标语言中置信度最高的 k 个候选词。也就是说,映射函数实际上应当具备辨别正确翻译与错误翻译之间的相对顺序的能力。以前的工作使用的目标函数只关注正例(互为翻译的单词对)之间的距离,没有明确地提供重要的排序信息,导致不能有效的提高模型的判别能力。

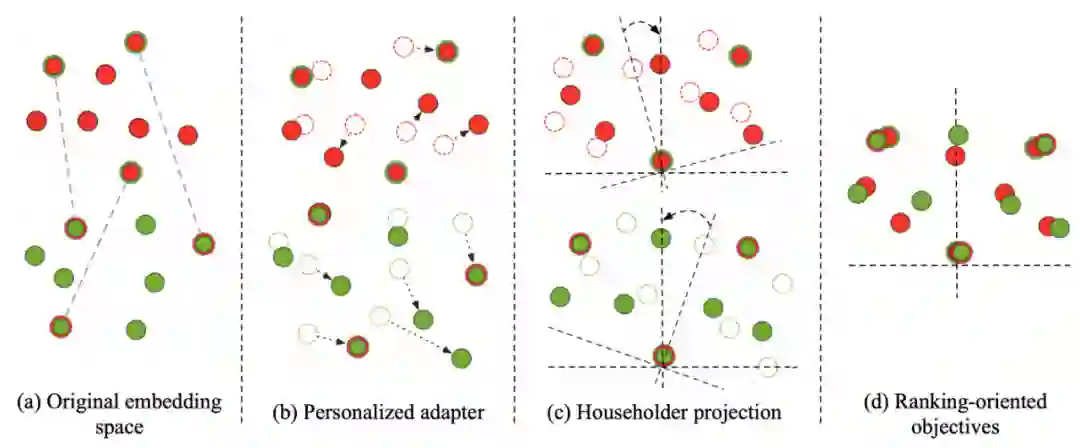
▲ 图2:RAPO进行双语词典归纳的主要步骤
1. 首先,个性化适配器(Personalized adapter)基于单语词向量和种子词典,利用单词上下文语义信息(Contextual semantic information)为每个词生成个性化偏移,使得原本的词向量被校准到更合适的位置;
2. 接着,Householder 投影(Householder projection)将两个校准后的词向量空间正交地映射到一个共享的隐空间,并在模型优化中保持映射的正交性;
3. 最后,我们为模型制定了基于排序的学习目标(Ranking-oriented objective)以及有效的负采样策略,使得 RAPO 可以具备更强的正负例的区分能力,进而提升 BLI 任务的表现。
由于不同语料库词频分布的偏差和词向量的不平衡训练,我们希望为每个单词提供自适应的个性化映射函数。目前相关工作一般基于人为假设定义一系列的后处理规则(post-processing)[6],根据每个单词在种子词典中的最近邻,对其映射方向进行微调。但这种基于人工假设的后处理方法可能并不可靠,并且不能保证适用于针对不同语言的翻译任务。
因此,我们设计了一种新颖的可学习的个性化适配器。它可以为每个单词自适应的学习到与任务相关的个性化偏移,并且能够通过梯度下降进行训练,从而将词向量调整到与下游任务更契合的位置。
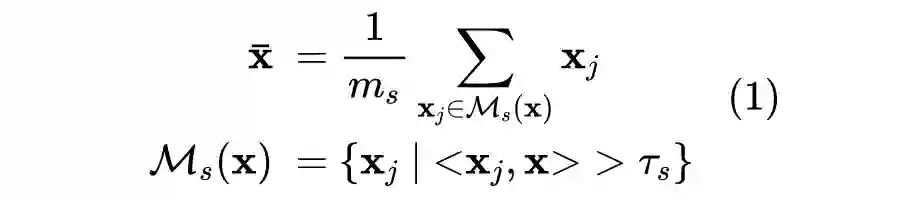
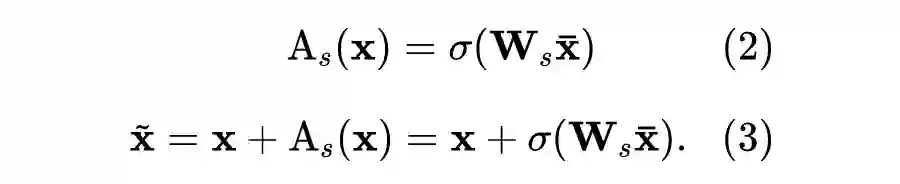
得到校准的词向量后,我们还需要设计理想的映射函数,将它们映射到共享的隐空间中。以前的工作已经证明了正交变换 [2] 作为一种“保距映射“,可以更好的保证词向量空间的结构信息不被破坏,从而更好的将少量的种子词典中的对齐知识迁移到其他单词上。
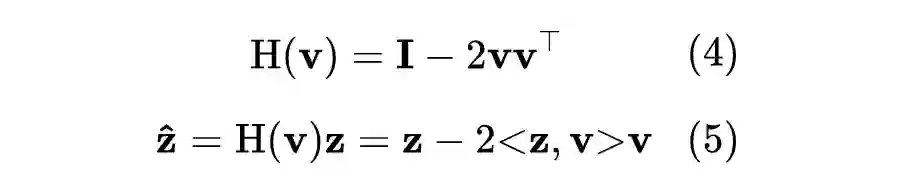
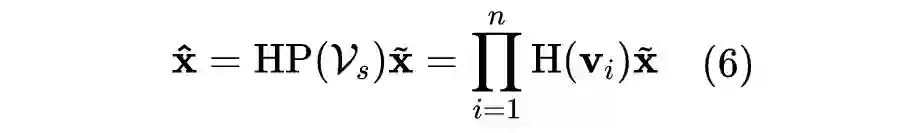
以前的工作使用的目标函数只关注正例(种子词典提供的单词对)之间的距离,没有明确地提供重要的排序信号,导致模型对候选词的排序能力没有被充分学习。实际上,BLI 更像是一个排序任务,因为我们希望为每个单词选择置信度最高的几个词作为翻译结果的候选集。因此,不同于之前基于回归学习目标的工作,我们提出了一种基于排序的损失函数来优化模型参数。
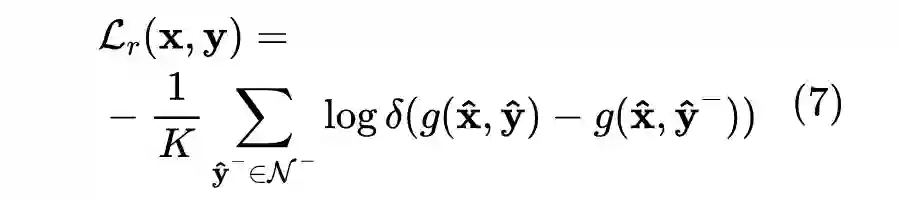
其中,关于负例的选择,我们采用了随机负采样和动态困难负例采样的混合方式,来同时保证训练的稳定性和排序的效果。
我们还额外添加了均方误差损失(Mean Squared Error Loss,MSE loss),要求模型在具有判断相对顺序的能力的同时,最小化正例之间的距离。
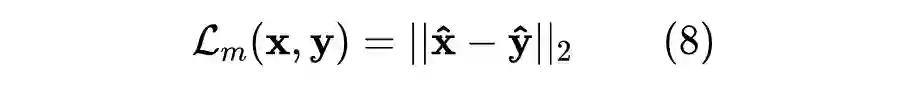
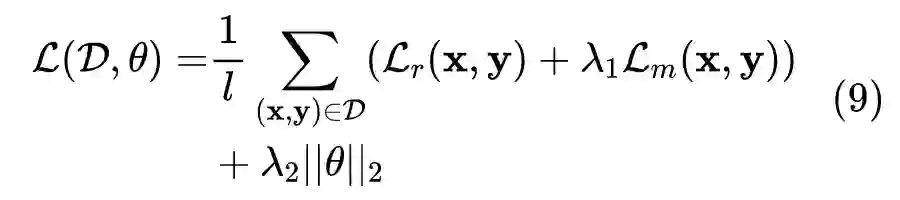

实验与分析
我们在 MUSE 数据集中的 20 个翻译任务上对模型进行了评估。如表 1 和表 2 所示,无论是监督学习(仅利用给定种子词典训练模型)还是半监督学习(迭代进行训练模型和利用模型扩充词典的步骤来提高模型效果)的场景下,RAPO 都在大多数的翻译任务上都达到了最好的结果,体现出了 RAPO 的高效性与泛化性。
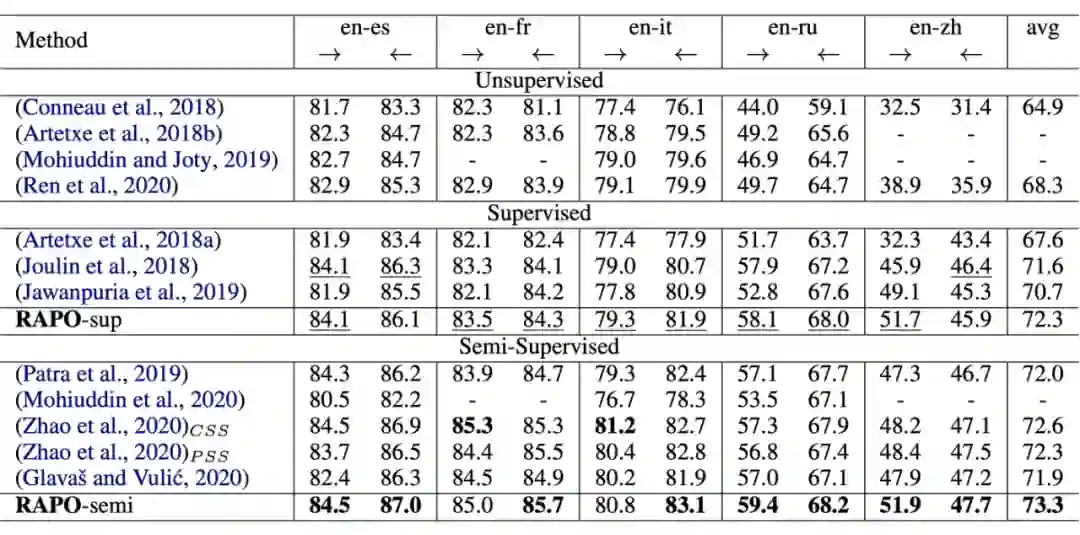
▲ 表1:在5个资源丰富的语言对上的Top1翻译准确度评估

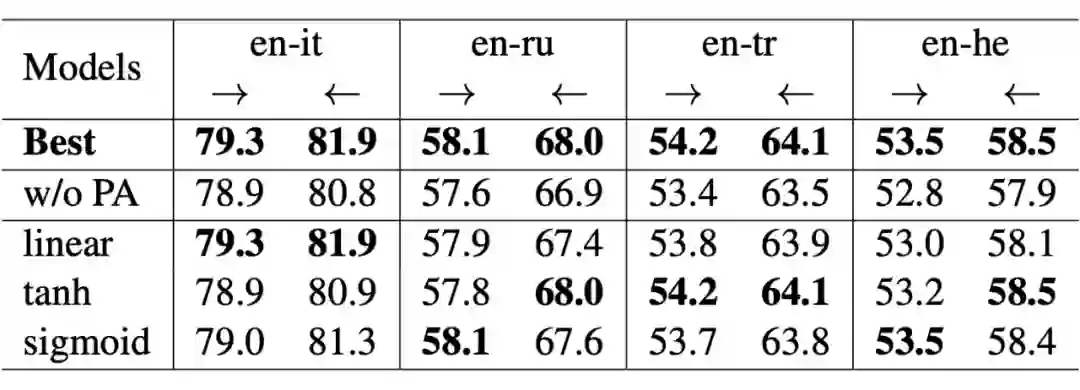
我们针对所提出个性化适配器、Householder 投影、基于排序的学习目标,在几个翻译任务上进行了消融实验,来验证不同组件对整个模型的影响。实验结果分别如表 3、表 4、表 5 所示。
不同的语言最合适的激活函数是不同的,这可能是因为不同语言间同构程度不同,例如:英语和意大利语(en-it)为同系语言,词向量空间同构性可能更强,适合线性激活函数来减小对词向量空间结构的改变;而英语和土耳其语(en-tr)同构性较差,则需要使用表达能力更强的非线性激活函数。
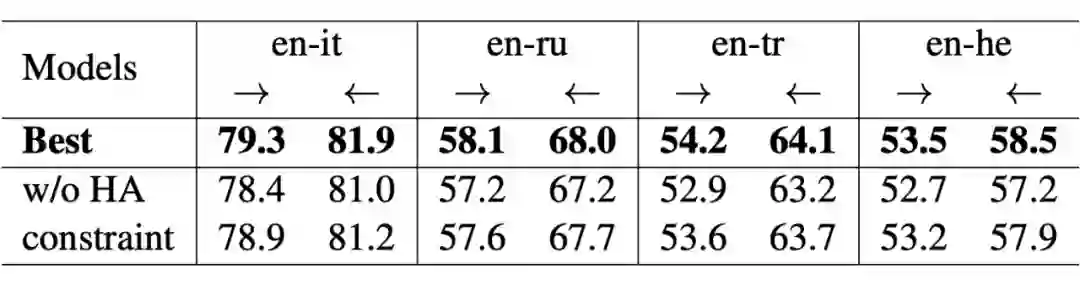
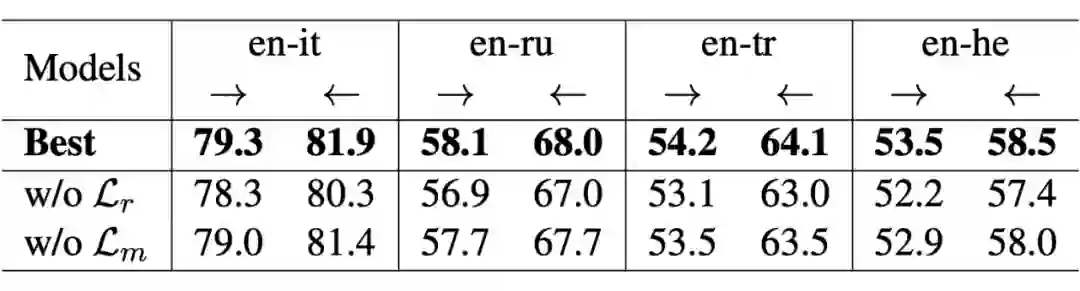
▲ 表5:关于损失函数的消融实验


参考文献
[1] Tomás Mikolov, Quoc V. Le, and Ilya Sutskever. 2013. Exploiting similarities among languages for machine translation. CoRR, abs/1309.4168.
[2] Chao Xing, Dong Wang, Chao Liu, and Yiye Lin. 2015. Normalized word embedding and orthogonal transform for bilingual word translation. In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 1006–1011, Denver, Colorado. Association for Computational Linguistics.
[3] Alexis Conneau, Guillaume Lample, Marc’Aurelio Ranzato, Ludovic Denoyer, and Hervé Jégou. 2018. Word translation without parallel data. In 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings.
[4] Mikel Artetxe, Gorka Labaka, and Eneko Agirre. 2018a. Generalizing and improving bilingual word embedding mappings with a multi-step framework of linear transformations. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, (AAAI18), the 30th innovative Applications of Artificial Intelligence (IAAI-18), and the 8th AAAI Symposium on Educational Advances in Artificial Intelligence (EAAI-18), New Orleans, Louisiana, USA, February 2-7, 2018, pages 5012–5019.
[5] Xu Zhao, Zihao Wang, Hao Wu, and Yong Zhang. 2020. Semi-supervised bilingual lexicon induction with two-way interaction. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2973–2984, Online. Association for Computational Linguistics.
[6] Goran Glavaš and Ivan Vulic. 2020. Non-linear instance-based cross-lingual mapping for non-isomorphic embedding spaces. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7548–7555, Online. Association for Computational Linguistic.
[7] Shuo Ren, Shujie Liu, Ming Zhou, and Shuai Ma. 2020. A graph-based coarse-to-fine method for unsupervised bilingual lexicon induction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 3476–3485, Online. Association for Computational Linguistics.
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧


