论文浅尝 | ESimCSE:无监督句子表示对比学习的增强样本构建方法

笔记整理:高超尘,中国科学院信息工程研究所硕士
动机
对比学习在学习无监督句向量方面引起了广泛的关注。其中最受关注的无监督方法是unsup-SimCSE(Gao et al., EMNLP 2021)。Unsup-SimCSE使用Dropout作为数据增强方法,将相同的输入句子传递给BERT两次,获得两个对应的句向量来建立一对正例。由于BERT使用了位置嵌入,一个句子的长度信息通常会被编码到句向量中,在SimCSE中的每对正例实际上包含相同长度的信息。因此,用这些正对训练的unsup-SimCSE会存在“长度偏置”,倾向于认为长度相同的或相似的句子在语义上更为相似。通过统计观察,我们发现unsup-SimCSE确实存在这一现象,证明了我们的判断。为了解决这个问题,我们提出了一种改进方法ESimCSE(Enhanced Unsup-SimCSE):首先通过一个简单的单词重复操作对输入句子进行修改,然后将输入句及其修改后的句子分别输入到BERT,以得到长度不同的正对;此外,我们还从CV领域中引入动量对比,在不产生额外计算开销的同时,增加负对的数量。在STS数据集上的实验表明:ESimCSE相比于SimCSE有明显的性能提升,在BERT-base上平均提升了2.02%。
亮点
我们观察到,无监督SimCSE每个正例对之间的长度都是相同的,这可能会使学习过程产生偏置(Bias)。我们提出了一种简单而有效的“单词重复”方法来缓解这个问题。
概念及模型
最近,研究人员提出使用对比学习来更好地学习无监督的句子嵌入。对比学习的目的是通过正负例的对比使相似的句子在空间上的距离更近,不相似的句子在空间上的距离更远。对比学习通常使用各种数据增强方法为每个句子生成两个互为正例的句子表示,并与其他句子表示互为负例。在这些方法中,最具代表性的是SimCSE(Gao et al.,EMNLP 2021),它将dropout看成是构造正例对的一种数据增强方法,通过无监督训练取得了与之前有监督的训练方法相当的性能。具体来说,SimCSE在batch中组成N个句子,并将每个句子输入预先训练过的BERT两次,以得到两个不同的句子表示。这样,来自同一个句子的表示构成了一个“正对”,而来自两个不同句子的表示构成了一个“负对”。
使用dropout作为数据增强方法虽然简单而有效,但也存在一个明显的弱点。由于SimCSE模型是建立在Transformer上的,而Transformer通过位置向量编码一个句子的长度信息,在一个正对中,两个来自同一句子的表示会包含相同长度的信息。相反,在一个负对中,两个表示来源于不同的句子,通常会包含不同长度的信息。因此,正对和负对在长度信息上具有明显的差异,这可能会使模型将之作为区分二者的特征学习下来,造成“长度偏置”。在推理时,模型会容易为长度相同或者相似的句子对打出更高的分数,从而偏离真实分值。为了分析长度差异的影响,我们使用SimCSE模型对7个标准语义文本相似度数据集进行了评估。我们根据句子对的长度差异将STS数据集分为两组,第一组句子间的长度差异小于等于3,第二组的长度差异大于3。我们使用无监督SimCSE模型预测分数,并计算了每一组的模型预测和真实标签之间的相似性差异。如表1所示,我们观察到:当长度差为≤3时,7个数据集的平均相似度更大,验证了我们的“长度偏置”假设。数据集的比较细节参见表4。
表1 预测相似度和真实相似度的差异

为了缓解这一问题,对于每一对互为正例的句子,我们期望在不改变句子语义的情况下改变句子的长度。现有的改变句子长度的方法通常会采用随机插入或者随机删除的方法,但是在句子中插入随机选择的单词可能会引入额外的噪声,并扭曲句子的含义;从句子中删除关键词则会大幅改变它的语义。因此,我们提出了一种更安全的方法,称为“单词重复”,它随机重复一个句子中的一些单词。如表2所示,可以看出,单词重复的方法在改变句子长度的同时可以有效保留句子的语义。
表2 多种数据增强方法对比

我们的重复策略如下公式(1) 和公式(2) 所示:
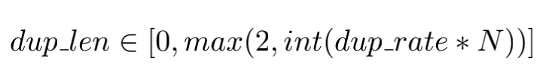
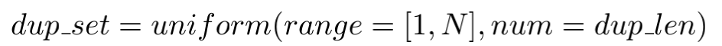
其中,dup_rate是一个重复比例的超参数,N为句子长度,之后会采样长度为dup_len的单词下标集合对原句进行采样。
除了对正例的改进之外,我们进一步探讨了如何优化负对的构造。由于对比学习是在正对和负对之间进行的,理论上讲,生成更多的负对,有利于更好地、更全面的的对比(SimCLR, Chen et al., ICML 2020)。因此,一个潜在的优化方向是通过生成更多的负对,鼓励模型走向更精细的学习。尽管增加batch-size可以帮助我们构造更多的负对,但是我们发现增大batch-size对SimCSE(Gao et al., EMNLP 2021)并不总是更好的选择,甚而会造成显著的性能下降。如图1所示。
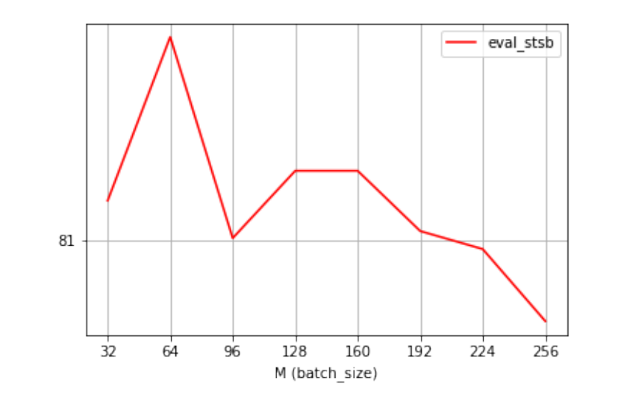
图1 随batch_size改变SimCSE性能的变化
对于unsup-SimCSE-BERT-base模型,最优batch-size大小为64,其他batch-size大小的变化都会带来性能的降低。值得注意的是,为了在扩展批量规模时,减轻GPU内存负担,以缓解性能下降的压力,CV领域中会引入MoCO(He et al., CVPR 2020)中的动量对比来实现这一目标。同样,我们也将这种方法引入到了SimCSE中。具体的动量更新策略如下公式所示:
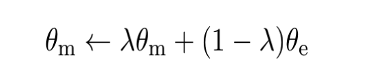
在引入更多的负例之后,我们将损失函数由公式
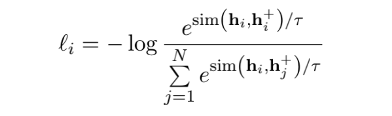
改为公式
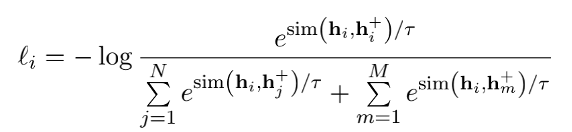
经过两个方法的改进,形成了如图2所示的Esimcse结构图:
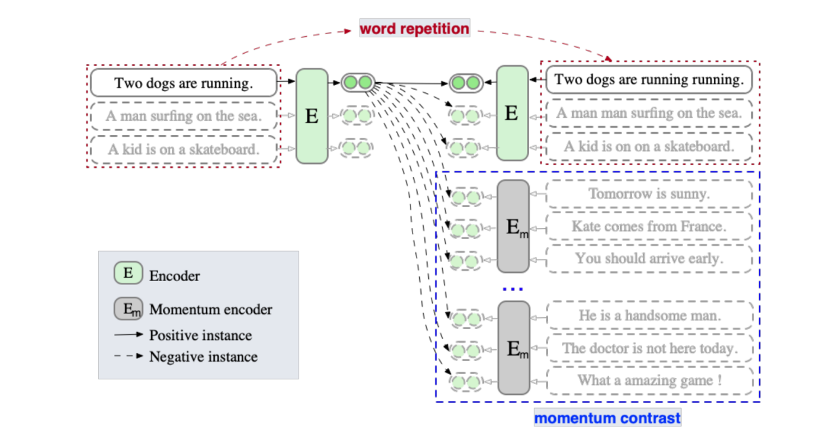
图2 EsimCSE结构图
实验
为了进行公平的比较,我们主要沿用了SimCSE的实验设置。我们使用从英语维基百科中随机抽取的100万个句子来进行训练,并利用文本相似度任务来衡量句子表示能力,在7个标准语义文本相似度(STS)数据集上进行了实验。所有的实验都是在Nvidia 3090 GPU上进行的。
表3 在标准语义评估数据集上的性能对比
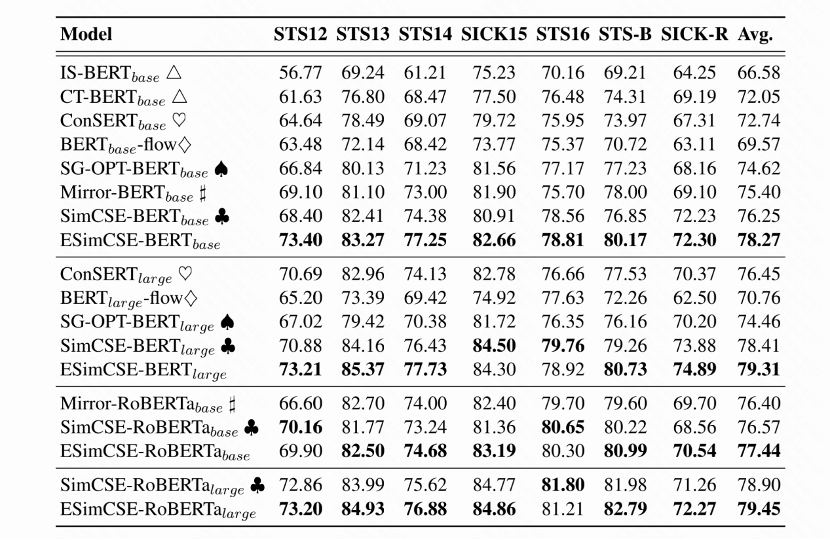
表3显示了模型在7个语义文本相似度(STS)测试集上的性能。我们主要选择SimCSE进行比较,并和我们的方法共享相同的设置。从表格可以看出,相比SimCSE,ESimCSE改进了不同模型设置下语义文本任务的性能,在BERT-base上最多有两个点的提升。
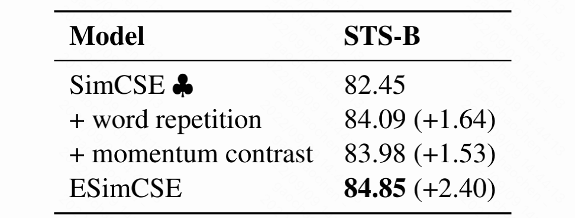
在消融试验中,我们探索了当只使用单词重复或动量对比时,可以给SimCSE带来的改进。如表4所示,无论是单词重复还是动量对比,都可以带来改进。这意味着所提出的两种增强正对和负对的方法都是有效的。此外,这两个模块可以叠加(ESimCSE)来获得进一步的性能提升。
表4 改进点之间的消融实验
我们进一步探讨了ESimCSE上句子对的相似性与长度差之间的关系,并与SimCSE进行了比较。因为STS12-STS16数据集没有训练集和验证集,所以我们在每个数据集的测试集上评估模型。我们根据句子对的长度差是否为≤3,将每个STS测试集分为两组。然后,我们计算了每一组的模型预测和真实分数之间的相似性差异。如表5所示:
表5 ESimCSE和SimCSE在多个数据集上的偏置(bias)对比
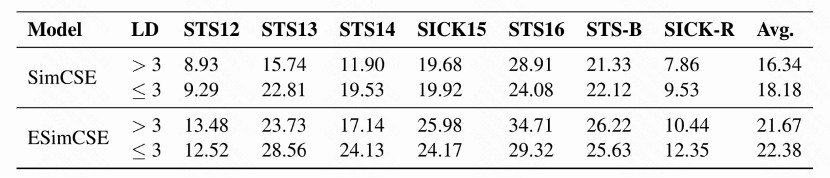
结果表明:ESimCSE显著降低了>3和≤3之间的平均相似度差距,从1.84降低到0.71,有效缓解了我们在引言中提到的长度偏差问题。
结论
本文提出了构造unsup-SimCSE的正负对的优化方法,称为ESimCSE。通过实验,ESimCSE在语义文本相似性任务上取得了明显的性能改进。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。

