斯坦福CS224W 图与机器学习5】Spectral Clustering
第五节主要介绍了谱聚类,也可用于上一节提到的社区划分,另外还扩展了基于motif的谱聚类,主要分成两个部分:
谱聚类算法
基于motif的谱聚类
谱聚类算法
Part1 问题定义
给定一个图 
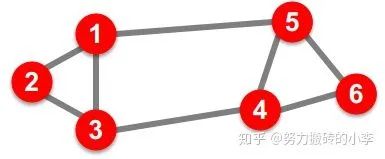
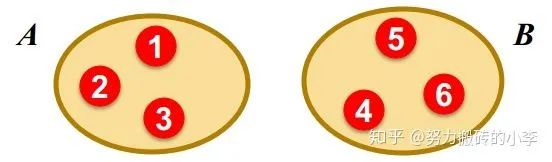
那么怎么定义一个“好”的划分?怎样快速找到这样的划分呢?
Part2 评价指标
上一节介绍的社区检测算法中,利用模块度作为评价指标来衡量社区划分的效果,而对于谱聚类,应该如何评价呢?
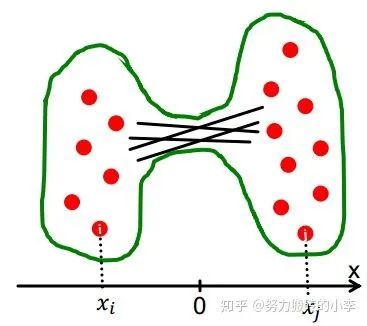
对于一个好的划分,一个很自然的想法,直觉上就是最大化组内连接数,最小化组间连接数
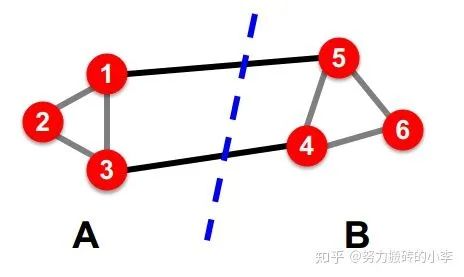
因此,利用“edge cut”来定义划分: 


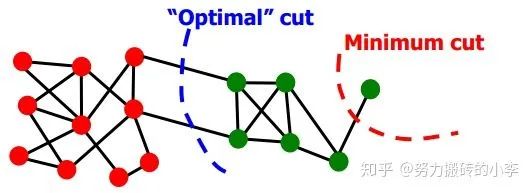
因此,考虑做归一化,评价指标为Conductance:

其中 
小结:可以利用Conductance作为谱聚类的评价指标
那么怎样快速找到划分呢?
Part3 谱图划分
先说结论,对于谱聚类,可以分为以下三步:
数据预处理:利用图的邻接矩阵A,度矩阵D,计算拉普拉斯矩阵
分解:计算拉普拉斯矩阵的特征值和特征向量,其中第二小特征值为
,对应的特征向量为
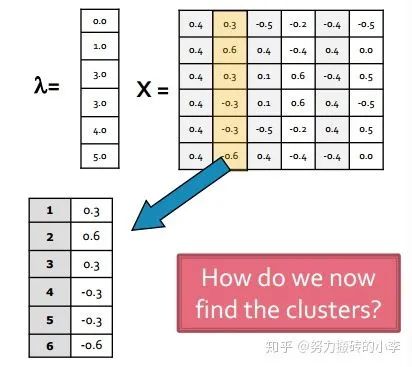
3. 分组:对上述特征向量 
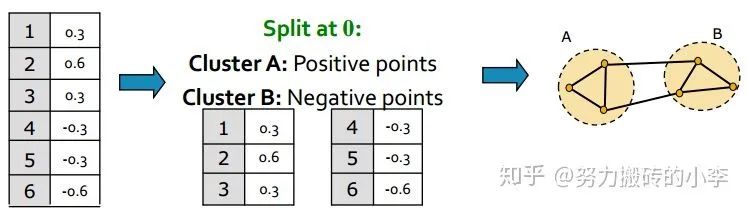
通过上述三个步骤,即可实现谱聚类。关于细节实现以及原理,有这样几个问题:
Q1:拉普拉斯矩阵有怎样的性质?
Q2:为什么是第二小特征值对应的特征向量?(为什么不是最小的?)
Q3:为什么用特征向量聚类来实现划分?这样的划分为什么是合理的?
Part3.1 拉普拉斯矩阵
拉普拉斯矩阵: 
所有特征值非负
, 即
是半正定的



证明:

所以拉普拉斯矩阵是半正定矩阵,上述三个性质均成立。另外一方面,由于 


Part3.2 第二小特征值意义
首先,给出一个结论:对于任意对称矩阵M,有 


证明:不妨限制特征向量 







由于当 


Part3.3 特征值&谱聚类
上述两个部分有什么意义呢?由上述两个部分,我们得到了两个结论:

(把part3.2中M替换为拉普拉斯矩阵L)
为了满足上面两式,我们需要限制两个条件:
x是单位向量:
,由于在拉普拉斯矩阵中,最小特征值为0,对应的特征向量为
,则有



现在回到谱聚类问题中,由于 


为什么不是利用 
通过上述三个部分,就简单解释了谱图聚类三个步骤的意义~
再补充一些提到的其他问题:
可以证明,如果将图G划分为A和B两个部分,且
那么对于评价指标conductance
:
,有
,即我们找到的这种划分标准是conductance的下界




证明:另 

假设 

上述方法中,是划分为两类,那么怎样划分为k类呢?
方法一:Recursive bi-partitioning 递归利用二分算法,将图划分为多类
方法二:聚类多个特征向量,选择k个特征向量,对这k个特征向量利用聚类方法(如k-means)将其聚为k类
基于motif的谱聚类
第三节中有介绍到motif,将图拆解为一个个子图来重新看待网络,motif给了网络一个新的定义方式,可以考虑从motif的角度(而不是上述边的角度)出发来进行谱图聚类,来捕捉图的角色信息。
Motif Conductance
类比edge cut和conductance,针对motif可以如下定义:
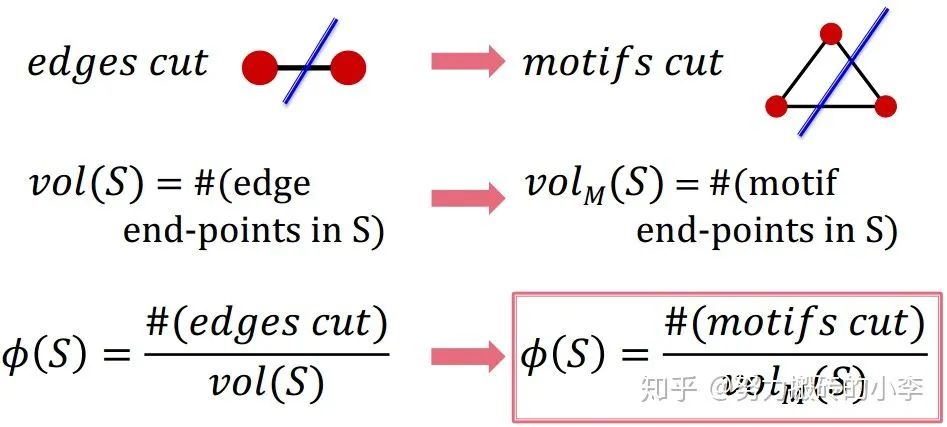
所以问题就变成了,给定motif M和图G,如何找到划分节点S,使motif conductance最小。(找到最小motif conductance为np问题,下面方法为近似算法)
Motif Spectral Clustering
类比上文谱图聚类,基于motif的聚类也分为三步:
数据预处理:
出现在motif M的次数,如下图所示,基于motif对图边权重进行重新定义,每个边权重为出现过的motif次数。

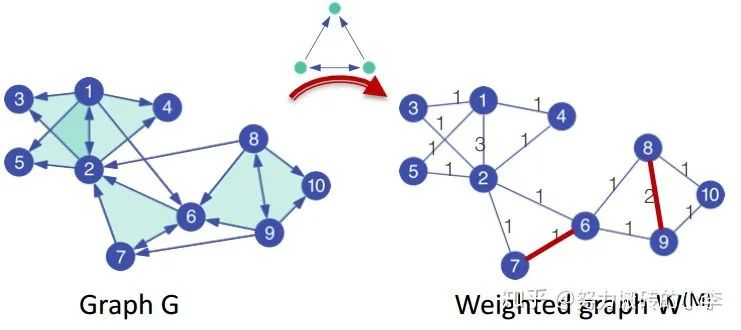
2. 分解:类似于标准的谱图聚类方法,计算拉普拉斯矩阵和对应的特征值特征向量(不过是基于新的图

3. 分组:利用Sweep procedure方法,对第二小的特征值对应的特征向量x的元素从小到达排列得到 

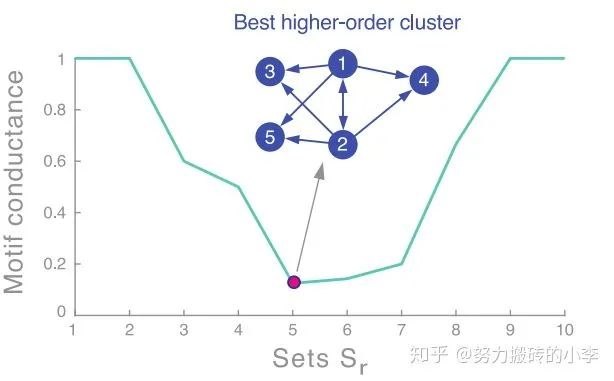
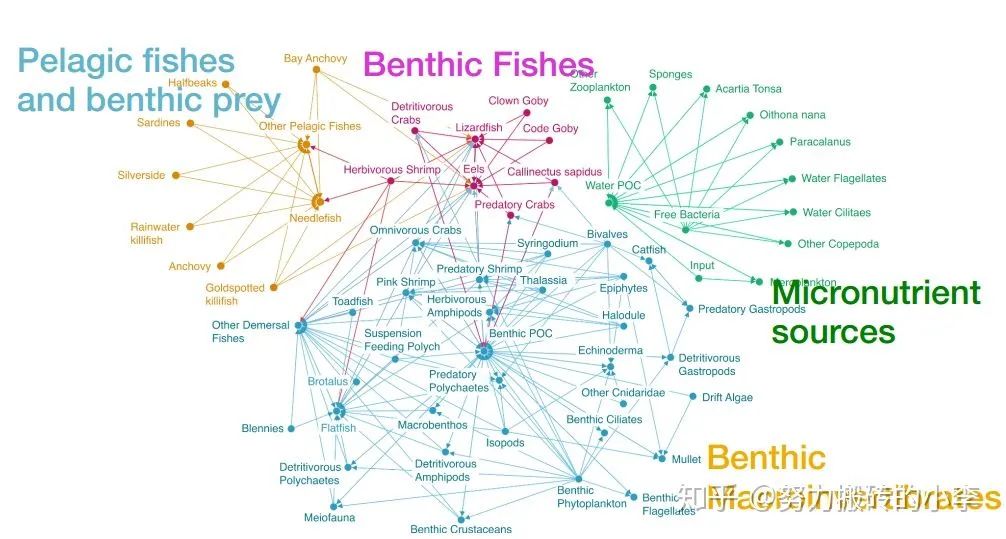
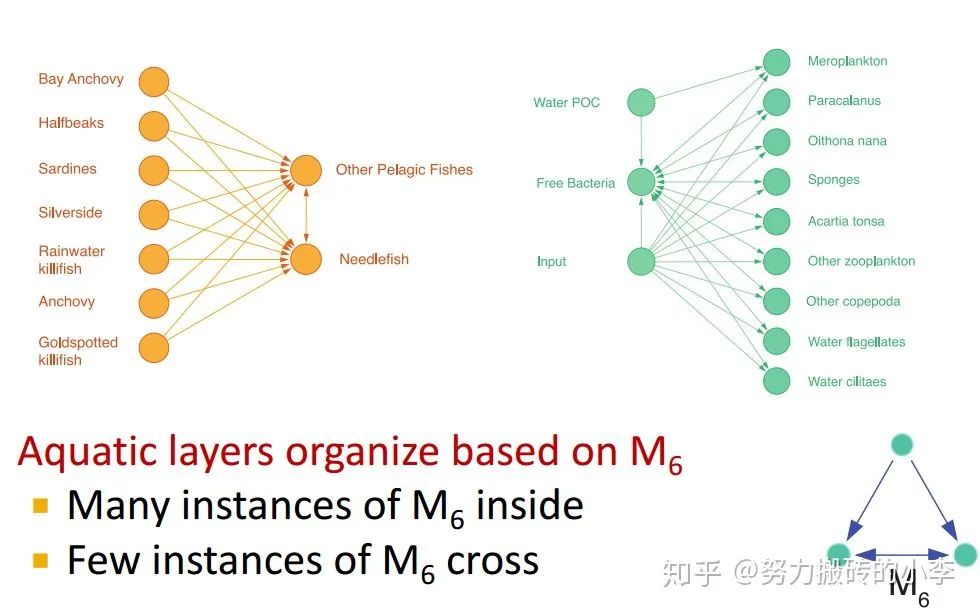
下图是食物链网络中基于右下角motif的谱图聚类结果。可以看出,基于motif的聚类在每一类结果中捕捉了特定的motif的结构,在每一类内部有较多的给定motif,而类与类之间这种motif较少。
系列文章:


