CIIS2018 演讲实录丨李武军:大数据机器学习
此次小编为大家整理的是来自南京大学计算机科学与技术系李武军主题为《大数据机器学习》的精彩演讲。

李武军
南京大学计算机科学与技术系
以下内容根据速记进行整理
经过李武军本人校对
我主要介绍我们研究组在大数据机器学习方面的一些进展。近年来人工智能快速发展的三个要素:大数据,机器学习和计算能力。大数据机器学习研究面向大数据的机器学习技术,可以为人工智能提供核心的理论与技术支撑。
大数据最重要的特点是数据量大,数据量大在存储、计算和通信方面都对现有机器学习系统带来挑战。我们研究组近年来从哈希学习和分布式随机学习两个方向探索大数据机器学习技术,来解决相应的挑战。
1. 哈希学习
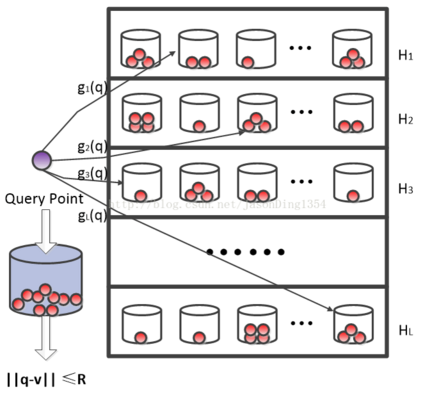
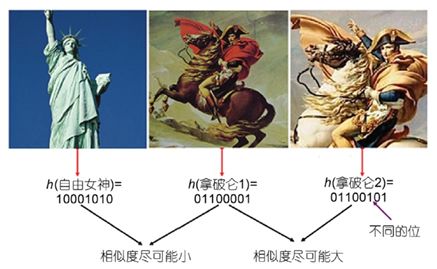
哈希学习最初是用于大数据中的最近邻检索任务,近年来被推广到其他多种机器学习任务,这个在后面我会简单提一下。在最近邻检索任务中,给定一个查询样本,系统需要从数据库中检索出跟查询样本最相似的一个或多个样本。当数据库中的样本数特别大的时候,最近邻检索会面临维度灾难、内存消耗大、检索速度慢等挑战。哈希学习可以用来解决上述挑战。哈希学习的基本思想是从数据中学习一个哈希函数,该哈希函数可以将样本从原始空间映射到海明空间。在海明空间中,每个样本被表示成一个二进制串(也叫哈希码),该哈希码表示尽可能地保持原始空间中的相似度。
哈希学习能实现降维,解决维度灾难问题。同时,哈希学习也可以减小内存消耗。假设数据库中有一亿个样本,每个样本用512维的单精度浮点数表示,所有样本需要约200GB的内存空间。但如果每个样本用128位的二进制哈希码表示,一亿个样本只需要1.6GB的内存空间。此外,基于哈希码表示,可以构建倒排索引,实现常数或者次线性复杂度的快速检索。即使有些场景需要对数据库中的所有样本进行遍历检索,基于哈希码表示的检索也会比原始表示快很多。因此,哈希学习也能解决检索速度问题。
哈希学习中的关键问题是怎样从训练数据中学习到好的哈希函数。如果学习到的哈希函数不能很好地保持原始空间的相似度,基于哈希码表示将得不到好的检索效果。根据训练数据中是否包含监督信息,哈希学习可以分为非监督哈希学习、监督哈希学习和半监督哈希学习。根据训练数据是否是多模态,哈希学习可以分为单模态哈希学习和多模态哈希学习。根据模型是否利用深度学习进行特征学习,哈希学习可以分为非深度哈希学习和深度哈希学习。我们研究组从2011年开始研究哈希学习,对多种不同的哈希学习场景都进行了系统地研究,发表了10余篇论文,这些论文被国内外研究者广泛引用。我们是国内最早研究哈希学习的研究者之一,在2011年我们刚开始研究哈希学习的时候,哈希学习相关的论文在国际上都很少。最近几年哈希学习已经发展成为国际上热门的研究方向,每年有大量的论文发表。同时,很多企业也开始采用哈希学习来解决实际生产系统中面临的大数据挑战。
因为报告时间有限,我只简要介绍我们研究组最近在深度哈希学习方面的两个工作。第一个是深度监督哈希学习方法DPSH。在DPSH中,训练数据包含成对的数据样本和样本对是否相似的监督信息,我们设计了一个将深度特征学习和哈希函数学习整合到统一框架的深度哈希学习模型。实验结果表明,DPSH取得了比其他方法更好的效果。下面是DPSH检索效果的展示,最左边的一列是查询样本,右边是检索到的前15个相似样本,红色框表示错误(不相似)的样本。可以看出,检索效果很不错。

另一个工作是多模态深度哈希学习方法DCMH。多模态应用很常见,例如,给定一张图片,需要给图片打文字标签,或者给定一段文字描述,需要检索相关的图片。在DCMH中,每个模态能进行自动特征学习,同时多个模态的自动特征学习和哈希函数学习被整合到一个统一框架,实现端到端的多模态深度哈希学习。实验结果表明,DCMH取得了比其他方法更好的效果。
除了最近邻检索任务,哈希学习还能用于其他多种机器学习任务,包括分类、聚类、推荐等。哈希学习也可以用作其他机器学习任务的数据预处理,也就是说,哈希学习得到的二进制表示可以作为样本新的特征表示,被其他机器学习任务进一步处理。我们发现,在有些应用中,二进制特征表示的表达能力已经足够强,也比传统实值表示更鲁棒。此外,哈希学习也可以用来加速深度神经网络的训练和推断。2017年底,Science发表的一项研究工作发现,果蝇的嗅觉系统识别不同气味是通过局部敏感哈希(LSH)来实现的。作者猜测,LSH可能是脑计算的通用原理。哈希学习是LSH的更高级版本,我在想,哈希学习是否是高级动物和人类脑计算的通用原理?如果这个能够被验证,将给人工智能和认知科学带来变革性突破。
我们2015年在《科学通报》上发表了一篇介绍哈希学习现状与趋势的文章。另外,我们也整理了哈希学习相关的论文、数据和代码。这些在我个人主页上都能下载。
2. 分布式随机学习
很多机器学习模型都可以形式化成目标函数为累积求和(或求均值)的优化问题。这些模型既包括常用的浅层学习模型,也包括常用的深度学习模型。该目标函数非常通用,如果我们能够设计有效的方法来快速优化该目标函数,我们就能解决很多常用机器学习问题的效率问题。
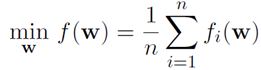
当训练数据量特别大的时候,很多优化算法会很慢。现在常用的优化算法是梯度下降方法,既包括全梯度方法,也包括随机梯度下降方法。最近出现了随机梯度下降的改进方法(例如SVRG等),把全梯度方法和随机梯度下降方法结合在一起,在很多任务上取得了比全梯度和随机梯度下降方法更好的效果。随机梯度下降及其改进方法在很多任务上比全梯度方法效率更高、泛化能力更强。因此,在大数据机器学习领域,随机梯度下降及其改进方法变得越来越流行。另外,最近也出现了随机坐标下降方法。我们把随机梯度下降、随机坐标下降、以及它们的改进方法统称为随机学习方法。我这个报告主要关注基于随机梯度下降及其改进方法的随机学习方法。
传统的单机随机学习方法在面临大数据的时候,速度可能还是太慢。在很多应用中(尤其是工业级应用中),数据量大到必须借助集群来分布式存储。也有很多应用为了保护隐私,数据本来就是分布式存储在多台机器或设备上,不能集中收集和存储数据。对于这些场景,必须设计基于多机集群的分布式随机学习算法。相对于单机随机学习,分布式随机学习可以更容易地解决存储和计算挑战,但通信开销是分布式随机学习面临的一个重要挑战。如果算法设计不合理,机器数越多,通信开销越大,分布式随机学习算法的速度反而会更慢。
我们研究组从2012年开始研究基于多机集群的分布式机器学习,发表了多篇相关论文。在该报告中,我主要介绍我们最近在分布式随机学习方面的两个工作,一个是面向凸问题的SCOPE算法,另一个是面向非凸问题(例如深度学习)的QESGD算法。如果机器学习问题的目标函数是凸函数,我们称之为凸问题。如果机器学习问题的目标函数是非凸函数,我们称之为非凸问题。
SCOPE算法可以用于基于MapReduce的主从架构(例如Spark)或者参数服务器架构。在这两个分布式架构中,数据被分布存储在多台称为Worker的机器上,模型参数被存储在称为Master或者Server的机器上(可以有多个Server)。已有的分布式随机学习算法大都基于小批量(mini-batch)随机梯度下降的思想,每轮迭代(epoch)的通信开销跟样本数成正比,通常是很大的。此外,已有算法的收敛率大都是次线性(比线性收敛率慢),需要迭代的轮数通常很大。SCOPE算法设计了一种本地学习(local learning)策略,每个Worker基于自己本地的数据学习(更新)很多轮后再跟Master或者Server进行通信。每轮迭代(epoch)只需要常数的通信开销,该开销一般很小。此外,SCOPE算法具有线性收敛率,所需迭代的轮数也很少。因此,相比于已有算法,SCOPE算法不仅通信开销小很多,而且收敛速度更快。在Spark平台(MapReduce架构)上的实验表明,SCOPE算法取得了比已有方法更好的性能。例如,在分类器logistic regression (LR)上的实验表明,SCOPE算法比Spark平台官网提供的机器学习包MLlib快很多倍(具体倍数决定于收敛精度)。另外,在参数服务器上的实验表明,SCOPE算法比现在企业界和学术界常用的算法和平台快数十倍甚至上百倍。SCOPE算法可以用于光滑的目标函数(例如LR),也可以通过proximal策略用于非光滑的目标函数(例如Lasso)。这里我只介绍基本思想,SCOPE算法中较深的理论分析,包括数据划分如何影响收敛率以及如何保证本地学习策略的收敛性等,可以查阅我们的论文。
在分布式机器学习(包括分布式随机学习)中,不同机器间需要传递(通信)模型参数和梯度,这些参数和梯度通常基于64位或者32位浮点数表示。一种减小通信开销的策略是对参数或者梯度进行量化,例如,将每个浮点数量化成4位或者8位的低位宽表示。已有量化方法大都是量化梯度,而且在量化过程中会引入额外的方差,导致算法收敛率的下降。我们设计了一种新的量化方法QESGD,用来量化模型参数。同时,QESGD能够减小量化方差,避免算法收敛率的下降。我们从理论上证明了QESGD的收敛性。在基于卷积神经网络的图像识别和基于循环神经网络的自然语言处理这两个常用的深度学习任务上,基于8位量化表示的QESGD相对于基于32位浮点数表示的分布式深度学习算法基本没有精度损失,但通信开销显著降低了。QESGD也取得了比其他量化方法更好的性能。
3. 平台与系统
我们研究组自主研发了大数据机器学习平台LIBBLE,部分功能已经开源,访问地址为 http://www.libble.ml/。LIBBLE面向Spark、参数服务器、非中心化架构等不同平台提供了不同的版本,既支持浅层学习模型,也支持深度学习模型。部分功能比当前学术界和企业界广泛采用的机器学习平台快数十倍甚至上百倍。
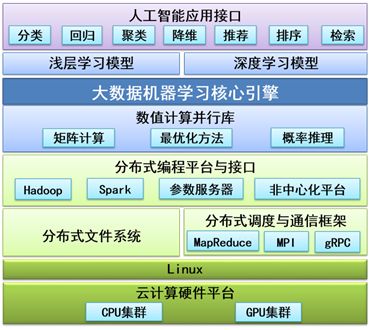
此外,LIBBLE平台还支持交互式界面操作,用户只需要通过浏览器进行拖拽式操作就可以完成机器学习任务。
4. 总结
大数据机器学习为人工智能提供核心的理论与技术支撑,但大数据机器学习面临存储、计算和通信等全方位挑战。哈希学习和分布式随机学习是实现大数据机器学习的两种常用技术。哈希学习可以实现数据压缩和快速检索,也可以实现大数据的分类、聚类、推荐等,并有可能成为一种通用的计算模式。凸问题的分布式随机学习可以采用本地学习策略来降低通信开销,但如何保证本地学习策略的收敛性和提升本地学习策略的收敛率是算法设计的关键。非凸问题的分布式随机学习可以通过对参数和梯度进行量化来降低通信开销,但如何减小量化方差是算法设计需要考虑的重要因素。哈希学习与分布式随机学习也能实现融合。例如,我们可以基于哈希码表示来降低分布式随机学习的存储和通信开销,也可以基于分布式随机学习来利用更大规模的数据训练得到一个更好的哈希函数。
CAAI原创 丨 作者李武军
未经授权严禁转载及翻译
如需转载合作请向学会或本人申请
转发请注明转自中国人工智能学会