开发 | CNN 那么多网络有何区别?看这里了解 CNN 发展历程
AI科技评论按:本文原载于知乎, AI科技评论获作者授权转载。
深度学习算法最近变得越来越流行和越来越有用的算法,然而深度学习或者深度神经网络的成功得益于层出不穷的神经网络模型架构。这篇文章当中作者回顾了从 1998 年开始,近 18 年来深度神经网络的架构发展情况。
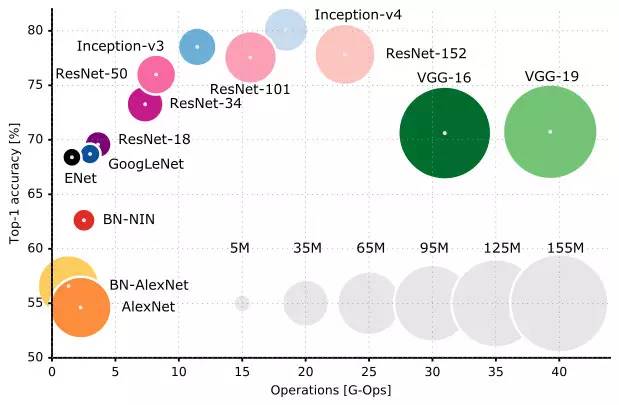
图中的坐标轴我们可以看出横坐标是操作的复杂度,纵坐标是精度。模型设计一开始的时候模型权重越多模型越大,其精度越高,后来出现了 resNet、GoogleNet、Inception 等网络架构之后,在取得相同或者更高精度之下,其权重参数不断下降。值得注意的是,并不是意味着横坐标越往右,它的运算时间越大。在这里并没有对时间进行统计,而是对模型参数和网络的精度进行了纵横对比。
其中有几个网络作者觉得是必学非常值得学习和经典的:AlexNet、LeNet、GoogLeNet、VGG-16、NiN。
如果你想了解更多关于深度神经网络的架构及其对应的应用,不妨看一下这篇综述 An Analysis of Deep Neural Network Models for Practical Applications。
LeNet5
1998 年。LeCun 乐春大神发布了 LeNet 网络架构,从而揭开了深度学习的神秘面纱。从 1998 年开始,深度学习这一领域就开始不断地被人们所熟知,也是因为这个网络架构,不断地推动着深度学习这一领域。当然啦,为什么不叫 LeNet 而叫 LeNet5 呢,因为 Yann LeCun 经过了很多次反复的试验之后的结果,同时也因为有 5 个卷基层因此以 lenet5 命名!
lenet5 架构是一个开创性的工作,因为图像的特征是分布在整个图像当中的,并且学习参数利用卷积在相同参数的多个位置中提取相似特性的一种有效方法。回归到 1998 年当时没有 GPU 来帮助训练,甚至 CPU 速度都非常慢。因此,对比使用每个像素作为一个单独的输入的多层神经网络,Lenet5 能够节省参数和计算是一个关键的优势。lenet5 论文中提到,全卷积不应该被放在第一层,因为图像中有着高度的空间相关性,并利用图像各个像素作为单独的输入特征不会利用这些相关性。因此有了 CNN 的三个特性了:1. 局部感知、2. 下采样、3. 权值共享。
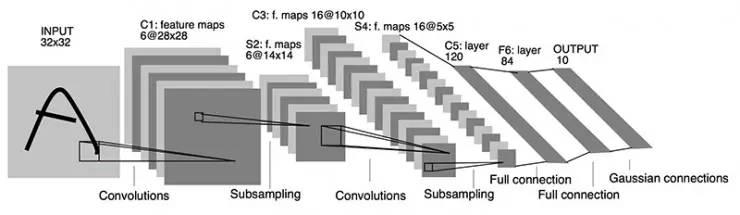
LeNet5 小结:
卷积神经网络使用 3 层架构:卷积、下采样、非线性激活函数
使用卷积提取图像空间特征
下采样使用了图像平均稀疏性
激活函数采用了 tanh 或者 sigmoid 函数
多层神经网络(MLP)作为最后的分类器
层之间使用稀疏连接矩阵,以避免大的计算成本
总的来说 LeNet5 架构把人们带入深度学习领域,值得致敬。从 2010 年开始近几年的神经网络架构大多数都是基于 LeNet 的三大特性。
GAP
从 1998 年 2010 年这 10 年当中,神经网络的发展却变得非常缓慢,就连人工智能领域的大牛吴恩达教授在 2003 年的公开课花了 2 节课的时间讲解 SVM 的推导,而对于神经网络只用了不到 20 分钟带过。在 2012 年 coresea 新的人工智能公开课上面反而 SVM 用了不到一节课的时间讲解,神经网络却用了 2 节课的时间进行算法介绍,可见科学家们对神经网络越来越重视。并且随着 CPU 和 GPU 的速度不断提升之下,带来了性能上的飞跃、也带来存储上的飞跃,让深度神经网络变得更加可算,于是从 2010 年开启了深度学习的大门。
Dan Ciresan Net
2010 年 Dan Claudiu Ciresan 和 Jurgen Schmidhuber 发表了一个 GPU 神经网络。论文里面证明了使用 NVIDIA GTX 280 GPU 之后能够处理高达 9 层的神经网络。
从此之后,Nvidia 公司的股价开始不断攀升,深度学习也越来越为人们所熟知。
AlexNet
2012 年,Alex Krizhevsky 发表了 AlexNet,相对比 LeNet 它的网络层次更加深,从 LeNet 的 5 层到 AlexNet 的 7 层,更重要的是 AlexNet 还赢得了 2012 年的 ImageNet 竞赛的第一。AlexNet 不仅比 LeNet 的神经网络层数更多更深,并且可以学习更复杂的图像高维特征。
AlexNet 小结:
使用 ReLU 函数作为激活函数,降低了 Sigmoid 类函数的计算量
利用 dropout 技术在训练期间选择性地剪掉某些神经元,避免模型过度拟合
引入 max-pooling 技术
利用双 GPU NVIDIA GTX 580 显著减少训练时间
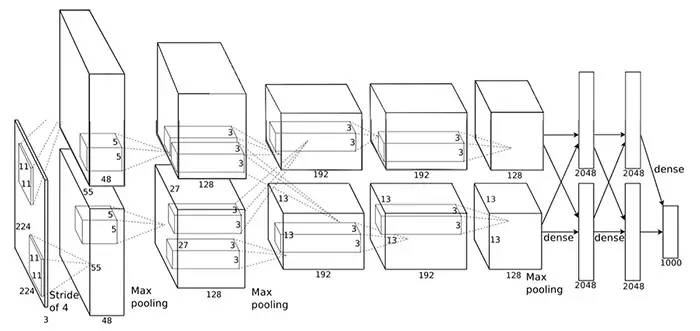
随着 GPU 提供越来越强悍的性能,同时允许超过 10x 倍数的训练增长时间,于是可以处理越来越大的图片和越来越庞大的数据集。暴风雨来临了,AlexNet 的成功开始了一场小革命,卷积神经网络 CNN 现在是深度学习的主力,于是有人称 “网络越复杂处理的任务越厉害”。
Network-in-network
2013 年年尾,Min Lin 提出了在卷积后面再跟一个 1x1 的卷积核对图像进行卷积,这就是 Network-in-network 的核心思想了。NiN 在每次卷积完之后使用,目的是为了在进入下一层的时候合并更多的特征参数。同样 NiN 层也是违背 LeNet 的设计原则(浅层网络使用大的卷积核),但却有效地合并卷积特征,减少网络参数、同样的内存可以存储更大的网络。
根据 Min Lin 的 NiN 论文,他们说这个 “网络的网络”(NIN)能够提高 CNN 的局部感知区域。例如没有 NiN 的当前卷积是这样的:3x3 256 [conv] -> [maxpooling],当增加了 NiN 之后的卷积是这样的:3x3 256 [conv] -> 1x1 256 [conv] -> [maxpooling]。
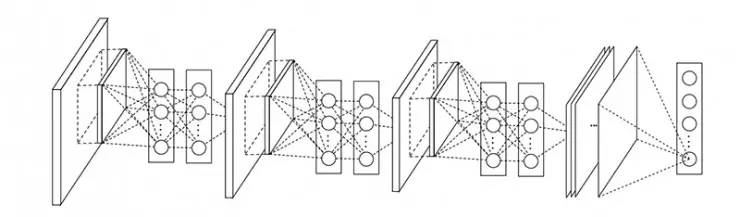
MLP 多层感知的厉害之处就在于它把卷积特征结合起来成为一个更复杂的组合,这个思想将会在后面 ResNet 和 Inception 中用到。
VGG
2014 年是个绽放年,出了两篇重要的论文:VGG、GoogLeNet。
来自牛津大学的 VGG网络是第一个在每个卷积层使用更小的 3×3 卷积核对图像进行卷积,并把这些小的卷积核排列起来作为一个卷积序列。通俗点来讲就是对原始图像进行 3×3 卷积,然后再进行 3×3 卷积,连续使用小的卷积核对图像进行多次卷积。
或许很多人看到这里也很困惑为什么使用那么小的卷积核对图像进行卷积,并且还是使用连续的小卷积核?VGG 一开始提出的时候刚好与 LeNet 的设计原则相违背,因为 LeNet 相信大的卷积核能够捕获图像当中相似的特征(权值共享)。AlexNet 在浅层网络开始的时候也是使用 9×9、11×11 卷积核,并且尽量在浅层网络的时候避免使用 1×1 的卷积核。但是 VGG 的神奇之处就是在于使用多个 3×3 卷积核可以模仿较大卷积核那样对图像进行局部感知。后来多个小的卷积核串联这一思想被 GoogleNet 和 ResNet 等吸收。
从下图我们可以看出来,VGG 使用多个 3x3 卷积来对高维特征进行提取。因为如果使用较大的卷积核,参数就会大量地增加、运算时间也会成倍的提升。例如 3x3 的卷积核只有 9 个权值参数,使用 7*7 的卷积核权值参数就会增加到 49 个。因为缺乏一个模型去对大量的参数进行归一化、约减,或者说是限制大规模的参数出现,因此训练核数更大的卷积网络就变得非常困难了。
VGG 相信如果使用大的卷积核将会造成很大的时间浪费,减少的卷积核能够减少参数,节省运算开销。虽然训练的时间变长了,但是总体来说预测的时间和参数都是减少的了。
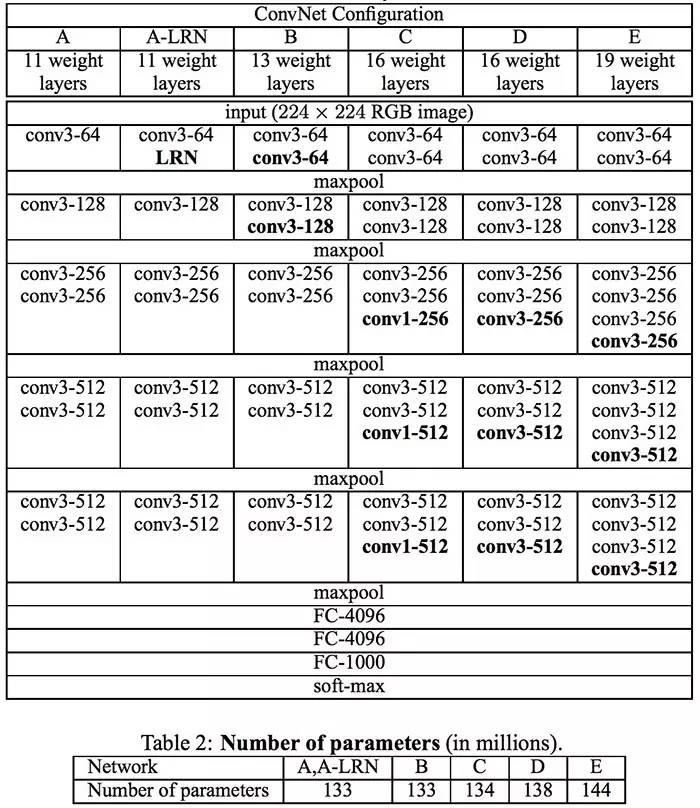
GoogLeNet
2014 年,在 google 工作的 Christian Szegedy 为了找到一个深度神经网络结构能够有效地减少计算资源,于是有了这个 GoogleNet 了(也叫做 Inception V1)。
从 2014 年尾到现在,深度学习模型在图像内容分类方面和视频分类方面有了极大的应用。在这之前,很多一开始对深度学习和神经网络都保持怀疑态度的人,现在都涌入深度学习的这个领域,理由很简单,因为深度学习不再是海市蜃楼,而是变得越来越接地气。就连 google 等互联网巨头都已经在深度学习领域布局,成立了各种各样的额人工智能实验室。
Christian 在思考如何才能够减少深度神经网络的计算量,同时获得比较好的性能的框架。即使不能两全其美,退而求其次能够保持在相同的计算成本下,能够有更好的性能提升这样的框架也行。于是后面 Christian 和他的 team 在 google 想出了这个模型:
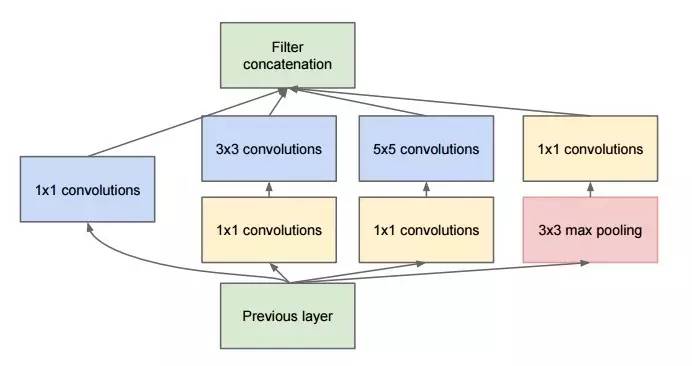
其乍一看基本上是 1×1,3×3 和 5×5 卷积核的并行合并。但是,最重要的是使用了 1×1 卷积核(NiN)来减少后续并行操作的特征数量。这个思想现在叫做 “bottleneck layer”。
Bottleneck layer
受 NiN 的启发,googleNet 的 Bottleneck layer 减少了特征的数量,从而减少了每一层的操作复杂度,因此可以加快推理时间。在将数据传递到下一层卷积之前,特征的数量减少了 4 左右。因此这种设计架构因为大量节省计算成本而名声大噪。
让我们详细研究一下这个 Bottleneck layer。假设输入时 256 个 feature map 进来,256 个 feature map 输出,假设 Inception 层只执行 3x3 的卷积,那么这就需要这行 (256x256) x (3x3) 次卷积左右(大约 589,000 次计算操作)。再假设这次 589,000 次计算操作在 google 的服务器上面用了 0.5ms 的时间,计算开销还是很大的。现在 Bottleneck layer 的思想是先来减少特征的数量,我们首先执行 256 -> 64 1×1 卷积,然后在所有 Bottleneck layer 的分支上对 64 大小的 feature map 进行卷积,最后再 64 -> 256 1x1 卷积。 操作量是:
256×64 × 1×1 = 16,000s
64×64 × 3×3 = 36,000s
64×256 × 1×1 = 16,000s
总共约 70,000,而我们以前有近 600,000。几乎减少 10 倍的操作!
虽然我们做的操作较少,但我们并没有失去这一层特征。实际上,Bottleneck layer 已经在 ImageNet 数据集上表现非常出色,并且也将在稍后的架构例如 ResNet 中使用到。
成功的原因是输入特征是相关的,因此可以通过适当地与 1x1 卷积组合来去除冗余。然后,在卷积具有较少数目的特征之后,它们可以再次扩展并作用于下一层输入。
Inception V3
Christian 的团队确实很厉害,2015 年 2 月他们又发表了新的文章关于在 googleNet 中加入一个 Batch-normalized 层。Batch-normalized 层归一化计算图层输出处所有特征图的平均值和标准差,并使用这些值对其响应进行归一化。这对应于 “白化” 数据非常有效,并且使得所有神经层具有相同范围并且具有零均值的响应。这有助于训练,因为下一层不必学习输入数据中的偏移,并且可以专注于如何最好地组合特征。
2015 年 12 月,他们发布了一个新版本的 GoogLeNet(Inception V3) 模块和相应的架构,并且更好地解释了原来的 GoogLeNet 架构,GoogLeNet 原始思想:
通过构建平衡深度和宽度的网络,最大化网络的信息流。在进入 pooling 层之前增加 feature maps
当网络层数深度增加时,特征的数量或层的宽度也相对应地增加
在每一层使用宽度增加以增加下一层之前的特征的组合
只使用 3x3 卷积
因此最后的模型就变成这样了:
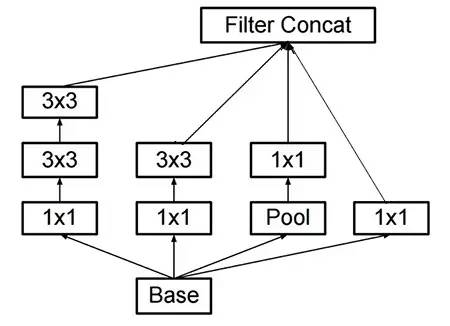
网络架构最后还是跟 GoogleNet 一样使用 pooling 层 + softmax 层作为最后的分类器。
ResNet
2015 年 12 月 ResNet发表了,时间上大概与 Inception v3 网络一起发表的。其中 ResNet 的一个重要的思想是:输出的是两个连续的卷积层,并且输入时绕到下一层去。这句话不太好理解可以看下图。
但在这里,他们绕过两层,并且大规模地在网络中应用这中模型。在 2 层之后绕过是一个关键,因为绕过单层的话实践上表明并没有太多的帮助,然而绕过 2 层可以看做是在网络中的一个小分类器!看上去好像没什么感觉,但这是很致命的一种架构,因为通过这种架构最后实现了神经网络超过 1000 层。傻了吧,之前我们使用 LeNet 只是 5 层,AlexNet 也最多不过 7 层。
该层首先使用 1x1 卷积然后输出原来特征数的 1/4,然后使用 3×3 的卷积核,然后再次使用 1x1 的卷积核但是这次输出的特征数为原来输入的大小。如果原来输入的是 256 个特征,输出的也是 256 个特征,但是这样就像 Bottleneck Layer 那样说的大量地减少了计算量,但是却保留了丰富的高维特征信息。
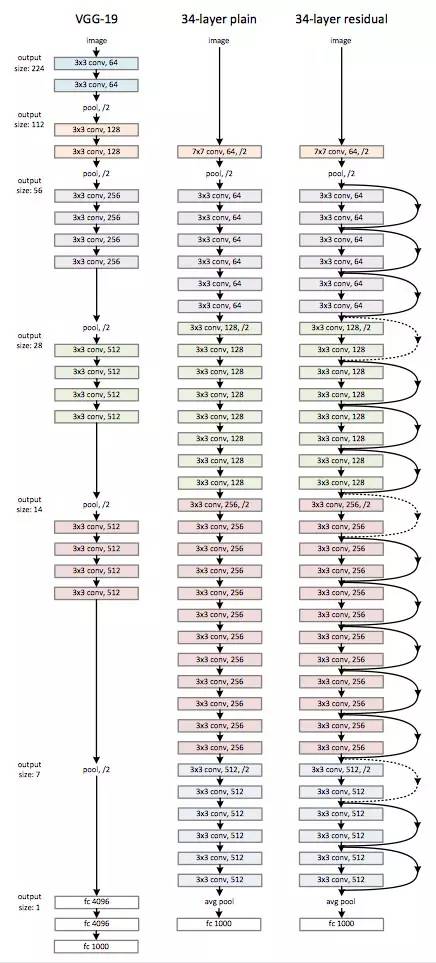
ResNet 一开始的时候是使用一个 7x7 大小的卷积核,然后跟一个 pooling 层。当然啦,最后的分类器跟 GoogleNet 一样是一个 pooling 层加上一个 softmax 作为分类器。下图左边是 VGG19 拥有 190 万个参数,右图是 34 层的 ResNet 只需要 36 万个参数:
ResNet 网络特征
ResNet 可以被看作并行和串行多个模块的结合
ResNet 上部分的输入和输出一样,所以看上去有点像 RNN,因此可以看做是一个更好的生物神经网络的模型
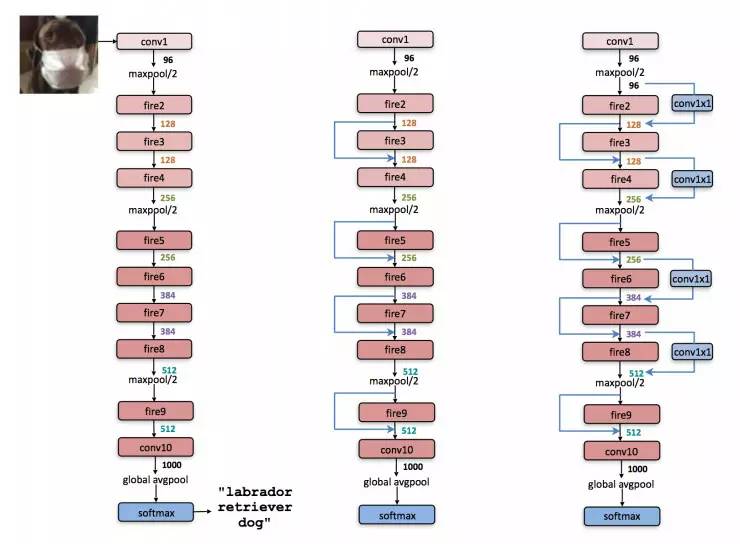
SqueezeNet
2016 年 11 月才发表的文章,一看论文的标题可以被镇住:SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and < 0.5MB model size。文章直接说 SqueezeNet 有着跟 AlexNet 一样的精度,但是参数却比 Alex 少了接近 50 倍并且参数只需要占用很小的内存空间。这里的设计就没有 SegNet 或者 GoogleNet 那样的设计架构惊艳了,但 SqueezeNet 却是能够保证同样的精度下使用更少的参数。
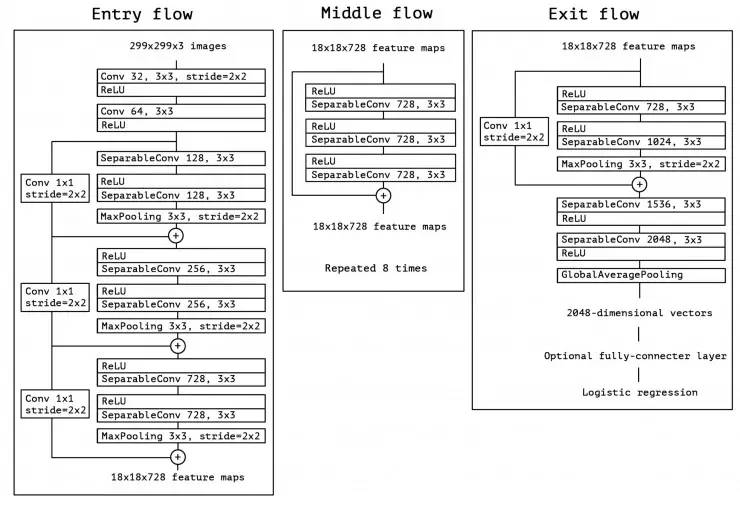
Xception
Xception 模型使用与 ResNet 和 Inception V4 一样简单且优雅的架构,并且改进了 Inception 模型。
从 Xception 模型我们可以看出来 Xception 模型的架构具有 36 个卷积层,与 ResNet-34 非常相似。但是模型的代码与 ResNet 一样简单,并且比 Inception V4 更容易理解。
从 here 或者 here 可以找到 Xception 的实现代码。
总结
我们再来回顾开篇的对比图。从图中我们可以看出来,AlexNet 一类的模型没有考虑太多权重参数的问题,因此圆圈比较大。一开始 AlexNet 只是希望用深度网络能够找到更多图像当中的高维特征,后来发现当网络越深的时候需要的参数越多,硬件总是跟不上软件的发展,这个时候如果加深网络的话 GPU 的显存塞不下更多的参数,因此硬件限制了深度网络的发展。为了能够提高网络的深度和精度,于是大神们不断地研究,尝试使用小的卷积核代替大的卷积核能够带来精度上的提升,并且大面积地减少参数,于是网络的深度不再受硬件而制约。
可是另外一方面,随着网络的深度越深,运算的时间就越慢,这也是个很蛋疼的事情,不能两全其美。作者相信在未来 2-3 年我们能够亲眼目睹比现有网络更深、精度更高、运算时间更少的网络出现。因为硬件也在快速地发展,特斯拉使用的 NVIDIA Driver PX 2 的运算速率已经比现在 Titan X 要快 7 倍。
后话
其实作者觉得神经网络的架构体系对于了解 “深度学习” 和对于了解深度学习的发展是非常重要的,因此强烈推荐大家去深入研读一下上面提到的网络架构对应的文章。
总是有一些人会问为什么我们需要那么多时间去了解这些深度网络的架构体系呢,而不是去研究数据然后了解数据背后的意义和如何对数据进行预处理呢?对于如何研究数据可以搜一下另外一篇文章《人工智能的特征工程问题》。对,数据很重要,同时模型也很重要。简单的举一个例子,如果你对某种图像数据很了解,但是不懂 CNN 如何对这些图像进行提取高维特征,那么最后可能还是会使用 HOG 或者传统的 SIFT 特征检测算法。
还要注意的是,在这里我们主要谈论计算机视觉的深度学习架构。类似的神经网络架构在其他领域还在不断地发展,如果你有精力和时间,那么可以去研究更多不一样的架构进化历。
引用
chenzomi12.github.io
LeNet
Dan Ciresan Net
AlexNet
Network-in-network
VGG
GoogleNet
Inception V3
Batch-normalized Layer
ResNet
SqueezeNet
Xception
Neural Network Architectures
————— 给爱学习的你的福利 —————
CCF-ADL81:从脑机接口到脑机融合
顶级学术阵容,50+学术大牛
入门类脑计算知识,了解类脑智能前沿资讯
课程链接:http://www.mooc.ai/course/114
或点击文末阅读原文

————————————————————


