仅用语音,AI就能“脑补”你的脸! | 技术头条


「2019 Python开发者日」,购票请扫码咨询 ↑↑↑
作者 | Wav2pix 研究团队
译者 | 刘畅
编辑 | Jane
出品 | AI科技大本营(公众号id:rgznai100)
【导语】之前我们为大家介绍过一项非常酸爽的研究“Talking Face Generation”:给定音频或视频后(输入),可以让任意一个人的面部特征与输入的音视频信息保持一致,也就是说出输入的这段话。当时营长就想到了“杨超越的声音+高晓松的脸”这样的神仙搭配。不过,近期一项新研究再度抓到了营长的眼睛!在最新的研究中,研究者仅需要音频信息就生成了人脸... ...如此鬼畜的操作,此乃头一次见啊!接下来营长就为大家介绍一下这项工作!

音频和图像是人类最常用的两种信号传输模式,图像传达的信息非常直观,而语音包含的信息其实比我们想象的要更丰富,包括说话人的身份,性别和情绪状态等等。从这两个信号中提取的特征通常是高度相关的,可以让人仅聆听声音就可以想象他的视觉外观。WAV2PIX 的工作就是仅利用语音输入,来生成说话者的人脸图像。其实这就是一个跨模态的视觉生成任务。
谈到这项研究的贡献,主要有三点:
提出了一个能够直接从原始的语音信号生成人脸的条件GAN:WAV2PIX;
提供了一个在语音和人脸两方面综合质量很高的一个数据集:Youtubers;
实验证明论文的方法可以生成真实多样的人脸。
论文收集了大V用户(Youtubers)上传到 Youtube 的演讲视频,这些视频通常具有高质量的说话环境、表达方式、人脸特征等。Youtubers 数据集主要由两部分组成:一个是自动生成的数据集和一个手动处理后的高质量的子集。
主要的预处理工作:
音频最初下载的是高级音频编码(AAC)格式,44100 Hz,立体声。因此转换为 WAV 格式,并重新采样到 16 kHz,每个样例占 16 位并转换为单声道。
采用基于 Haar 特征的人脸检测器来检测正脸。仅采纳置信度高的帧
保存检测出来的那帧图像及前后两秒的语音帧,以及一个标签(identity)。
方法介绍
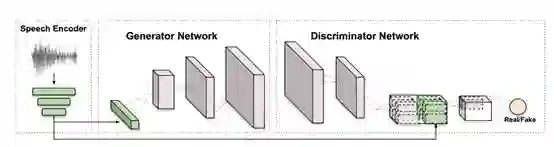
研究主要由三个模块构成:一个是语音编码器,一个是图片生成网络,一个是图片判别网络。
语音编码器(Speech Encoder):已有的方法大多数是手工提取音频特征,并不是针对生成网络的任务进行优化的,而 SEGAN 提出了一种在波形上用于语音处理的方法。因此作者在已有的工作 SEGAN 上进行修改。修改为具有 6 层一维网络,并且每层的 kernel 大小是 15x15,步长为 4,然后每层卷积网络后面使用 LeakyReLU 激活函数,网络的输入通道是 1。输入 16kHZ 下1 秒的语音片段,上述的卷积网络可以得到一个 4x1024 的张量,然后采用三个全连接网络将特征数量从 4x1024 降到 128。作为生成器网络的输入。
图片生成器(Image Generator Network):输入是语音编码器的 128 向量。采用二维转置卷积、插值、dropout 等方式将输入转为 64x64x3 或者 128x128x3 的张量。在 G 的损失函数中添加了一个辅助损失用于保持说话人的标签(Identity)。
图片判别器(Image Discriminator Network):判别器由几层步长为 2,kernel 大小是 4x4 的卷积网络组成,并使用谱归一化和 LeakyReLU 激活函数。当张量为 4x4 时,作者拼接了语音的输入,并采用最后一层网络来计算 D 网络的分数。
实验过程
训练:将手动处理后的数据集作为训练集,采用数据增强等手动。值得注意的是,在处理时将每张图像复制了 5 次,并将其与 4 秒音频里面随机采样的 5 个不同的1秒音频块进行匹配。因此总共有 24K 左右的图像-音频对用于模型训练。其它超参数采用参考的文献设置。
评估:下图给出了可视化的结果,虽然生成的图像都比较模糊,但基本可以观察到人的面部特征,并且有不同的面部表情。

作者进一步微调了一个预训练的 VGG-FACE Descriptor 网络,用于量化测试结果,在作者提供的数据集上,可以达到 76.81% 的语音识别准确率和 50.08% 的生成图像准确率。
为了评估模型生成图像的真实程度,作者定义了一个 68 个人脸关键点的精度检测分数。如下图所示,测试结果精度可以达到 90.25%。表明在大多数情况下生成的图像保留了基本的面部特征。

感兴趣的小伙伴们可以下载阅读研究一下~

(本文为 AI大本营编译文章,转载请微信联系 1092722531)
◆
精彩推荐
◆
「2019 Python开发者日」演讲议题全揭晓!这一次我们依然“只讲技术,拒绝空谈”10余位一线Python技术专家共同打造一场硬核技术大会。更有深度培训实操环节,为开发者们带来更多深度实战机会。更多详细信息请咨询13581782348(微信同号)。

推荐阅读:
定了!人社部等发布13项新职业,AI、无人驾驶、电竞上榜
首发 | 13篇京东CVPR 2019论文!你值得一读~ 技术头条
争论不休的TF 2.0与PyTorch,到底现在战局如何了? | 技术头条

❤点击“阅读原文”,查看历史精彩文章。


