机器学习基础篇--监督学习经典案例(Python实现)

机器学习基础篇--监督学习
前几章讲过,机器学习监督学习模型的任务重点在于,根据已有的经验知识对未知样本的目标/标记进行预测。根据目标预测变量的类型不同,我们把监督学习任务大体分为分类学习与回归预测两类。
监督学习的流程:
首先准备训练数据,可以是文本、图像、音频等;然后抽取所有需要特征,形成特征向量(Feature Vectors);接着,把这些特征向量连同对应的标记/目标(Labels)一并送入学习算法(Machine Learning Algorithm)中,训练出一个预测模型(Predictive Model);然后,采用同样的特征提取方法作用于新测试数据,得到用于测试的特征向量;最后,使用预测模型对这些待测的特征向量进行预测并得到结果(Expected Labels)。
分类学习是常见的监督学习问题,其中最基础的便是二分类(Binary Classification)问题,即判断是非,从两个类别中选择一个作为预测结果;除此之外还有多分类(Multiclass Classification)的问题,即在多于两个类别中选择一个;
实际应用场景:
在实际生活和工作中,会遇到很多多分类的问题,如:医生对肿瘤性质的判断;邮件系统对手写体邮编数字进行识别;互联网资讯公司对新闻进行分类;甚至我们还能对某些大灾难的经历者做是否生还预测。
模型介绍:
假设现在有一些数据,我们用一条直线对这些点进行拟合(该线称为最佳拟合直线),这个拟合过程就是回归。Logistic 回归(Logistic Regressive)进行分类的主要思想:根据现有数据对分类边界线建立回归公式,以此进行分类。
实战示例:
数据:
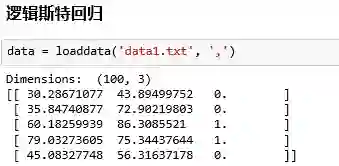
选择自变量和因变量:

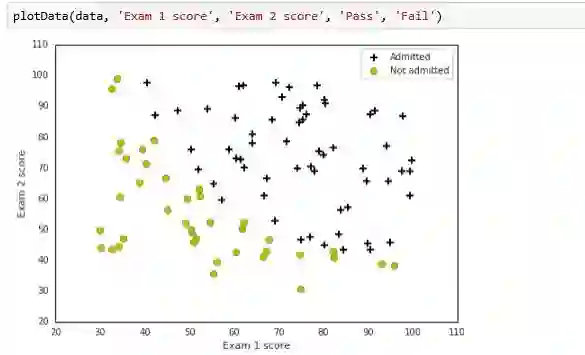
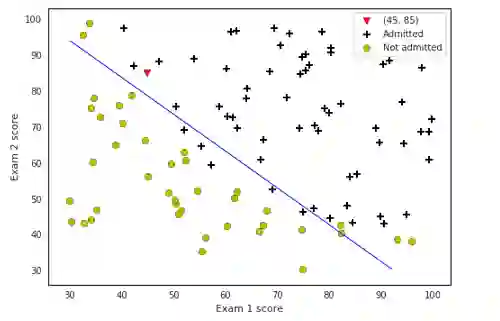
绘图展示:
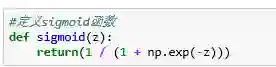
逻辑回归假设:
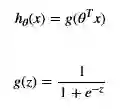
损失函数:
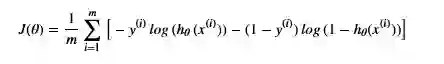
向量化的损失函数(矩阵形式):


求偏导(梯度):
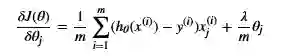
向量化的偏导(梯度):

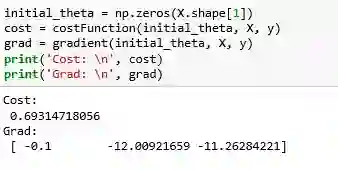
代码实现:

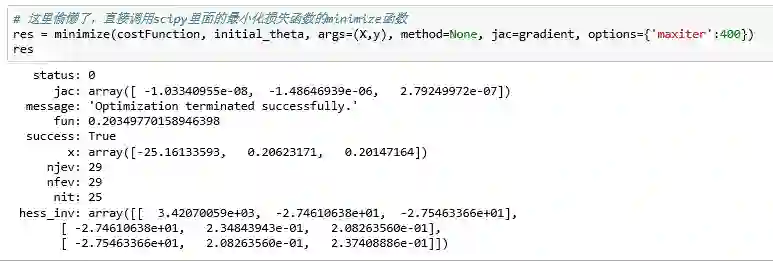
最小化损失函数(梯度下降)
预测部分:



画决策边界

今日赠言
笑着面对,不去埋怨。悠然,随心,随性,随缘。注定一生改变的,只再百年后,那一朵花开的时间。
——坦然面对吧,致彷徨的您
推荐阅读:
机器学习篇
自然语言处理中的Attention Model:是什么及为什么
python学习篇
参考文献:
Python机器学习及实践
机器学习
Mitchell,T.M 《Machine Learning》
http://www.cnblogs.com/pinard/p/5970503.html



