深度 | 自然语言处理的一大步,应用Word2Vec模型学习单词向量表征
选自TowardsDataScience
作者:Suvro Banerjee
机器之心编译
参与:Pedro、张倩
在常见的自然语言处理系统中,单词的编码是任意的,因此无法向系统提供各个符号之间可能存在关系的有用信息,还会带来数据稀疏问题。使用向量对词进行表示可以克服其中的一些障碍。本文通过推理、范例及数学公式介绍了从原始文本中学习「词嵌入」的模型 Word2Vec。该模型通常用在预处理阶段,可以提高计算效率。

让我们用推理、范例及数学公式来介绍 Word2Vec
引言
Word2Vec 模型用于学习被称为「词嵌入」的单词向量表示,通常用在预处理阶段,之后,学习到的词向量可以被输入到一个判别模型(通常是一个 RNN)中,进而生成预测或被用于处理其他有趣的任务。
为什么要学习词的嵌入表示
图像和音频处理系统与丰富的高维数据集一起工作,其处理的图像数据被编码为各个原始像素强度的向量,因此所有信息都被编码在数据中,从而可以很容易地建立起系统中各种实体之间的关系(比如猫和狗)。
但是,在常见的自然语言处理系统中,单词被视为离散的原子符号,因此」猫」可以被表示为 Id537 而」狗」可以被表示为 Id143。这些编码是任意的,因而无法向系统提供各个符号之间可能存在关系的有用信息。这意味着该模型在处理关于「狗」的数据时无法充分利用关于「猫」的知识(例如它们都是动物、宠物、有四只脚等)。
将单词表示为独特、离散的序列号还会导致数据稀疏问题,这通常意味着我们可能需要更多数据才能成功地训练统计模型,而使用向量对词进行表示可以克服其中的一些障碍。
举例来说:
传统的自然语言处理方法涉及到许多语言学本身的知识。理解诸如音素和语素之类的术语是相当基础和必要的,因为有许多语言学分支致力于这样的研究。我们来看看传统的自然语言处理如何试图理解下面的单词。
假设我们的目标是收集关于这个词的一些信息(表征它的情感,找到它的定义等)。利用我们的语言学知识可以将这个词分解成 3 个部分。

深度学习最基本的层次是表示学习。在这里,我们将通过相同方法在大规模数据集上为单词构建向量表示。
词向量
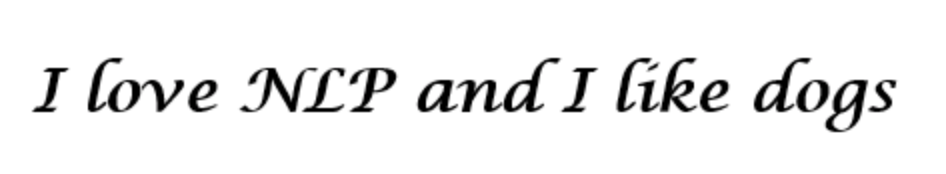
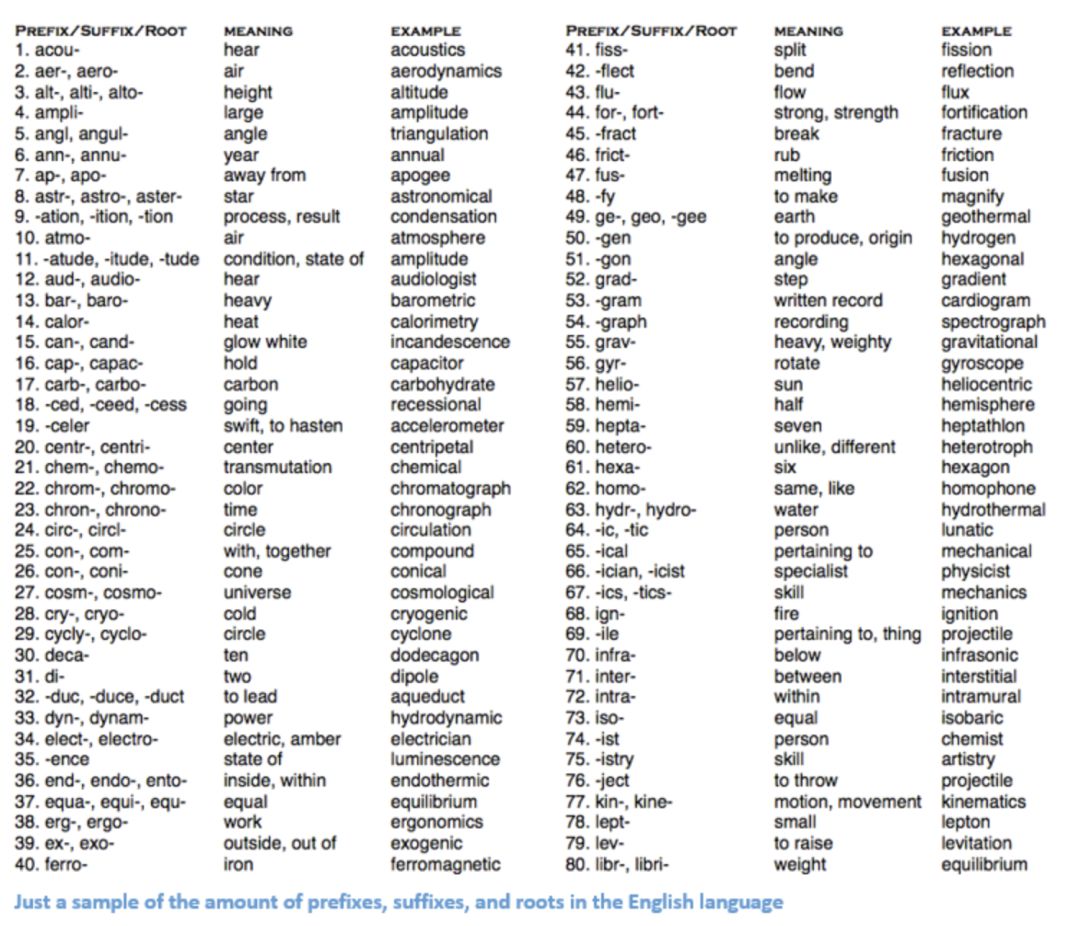
我们把每一个单词表示为一个 d 维的向量。在这里 d=6。我们希望根据这个句子,为每一个单独的词构建它的向量表示。

现在让我们来思考一下如何填充这些值。我们希望这些值能够一定程度上表示这个单词和它的上下文、含义或语义信息。一种方法是构建共现矩阵。
共现矩阵包含了语料库(或训练集)中每一个单词同出现在它后一个单词的统计信息。下表是上面所示句子的共现矩阵。
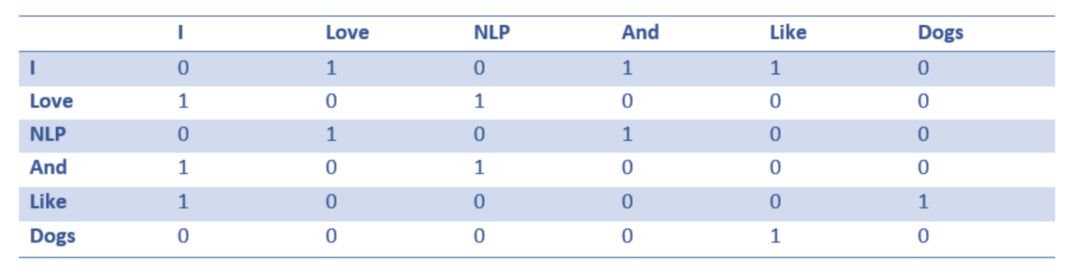

通过这个简单的矩阵,我们能够获得非常有用的信息。例如,「love」和「like」这两个词对名词(NLP 和 dogs)的计数都是 1。他们对「I」的计数也是 1,这表明这些词很可能是某种动词。对于远比一个句子更大的数据集,可以预料的是这种相似性会体现得更加清晰,因为「like」、」love」和其他具有相似上下文的同义词将开始具有相似的向量表示。
这是一个好的开始,但应该注意每个单词的维度将随着语料库的大小线性增加。如果我们有一百万词(在自然语言处理任务中并不算很多),我们将会得到一个一百万乘一百万的非常稀疏(有很多 0)的矩阵,存储效率很低。后来人们在探索更好的词向量表示上取得了很多进展。其中最著名的是 Word2Vec。
正式介绍
向量空间模型(VSM)表示(嵌入)连续向量空间中的单词,其中语义上相似的单词被映射到相邻的点(「都嵌在彼此附近」)。向量空间模型在自然语言处理中有着悠久、丰富的历史,但是所有方法都以某种方式依赖于分布假说,该假说认为出现在相同语境中的词语具有相似的语义。基于这一原则的方法可以被分为两类:
1. 基于计数的方法(例如隐性语义分析)
2. 预测方法(例如神经概率语言模型)
二者的区别在于:
基于计数的方法计算某个词在大型文本语料库中与其相邻词汇共同出现的频率的统计数据,然后将这些统计数据映射到每个词的小而密集的向量。
预测模型直接尝试根据学习到的近邻单词的小密集嵌入向量(考虑模型的参数)来预测单词。
Word2vec 是一种用于从原始文本中学习词嵌入的模型,它有很高的计算效率。它主要有两种实现方式,一种是连续词袋模型(CBOW),另一种是 Skip-Gram 模型。这两种方式在算法上是相似的,唯一的差别在于 CBOW 从源上下文单词中预测目标单词,而 Skip-Gram 则恰恰相反,它根据目标单词预测源上下文单词。
接下来,我们将重点讨论 skip-gram 模型。
应用到的数学知识
神经概率语言模型一般使用最大似然原则进行训练,其目标是要最大化在给定前面的单词 h(对于「history」)时的下一个单词 wt(对于「target」)的 softmax 概率
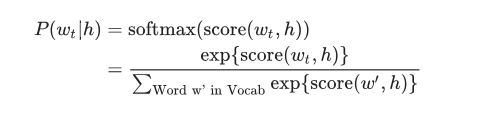
其中 score(wt, h) 计算目标词 wt 与上下文 h 的相容性(常用点积)。
我们通过在训练集上最大化它的对数似然来训练这个模型。所以,我们要最大化以下损失函数:
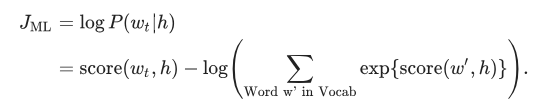
这为语言建模提供了一个合适的标准化概率模型。
我们可以用另一种形式来更好地展示这种方法,它可以清晰地展示在训练过程中为了最大化目标函数而不断改变的选择变量(或参数)。
我们的目标是找到可以用于预测当前单词的周围词汇的向量表示。我们尤其希望最大化我们在整个语料库上的平均对数概率:
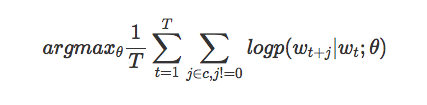
这个等式的主要含义是,在当前单词的一定窗口范围 c 内出现的单词 wt 存在一定的概率 p。这个概率同当前词 wt 和我们设定的参数 theta 相关。我们希望设定的参数 theta 可以最大化整个语料库的上述概率。
基本参数化:Softmax 模型
基本的 skip-gram 模型定义了经过 softmax 函数计算的概率 p。如果我们的词汇表中有 N 个词,而我们希望学习的嵌入向量的维度为 k,那么我们可以设定 wi 是 N 维的 ont-hot 向量,theta 是一个 N×K 的嵌入矩阵,从而有:
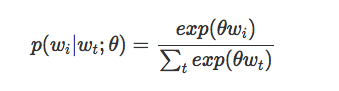
值得注意的是,在学习之后,矩阵 theta 可以被认为是嵌入查找矩阵。
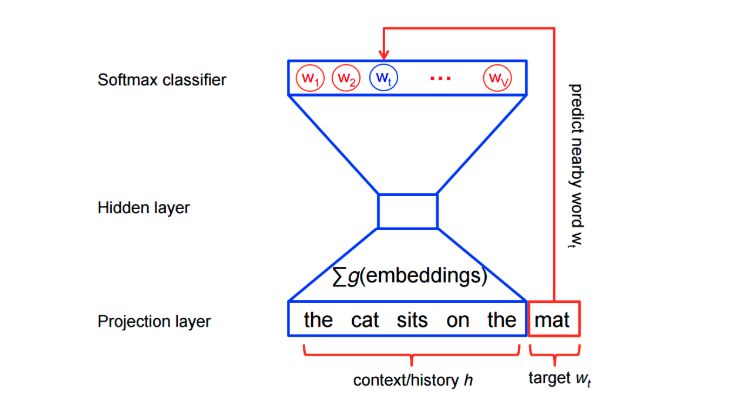
在架构方面,它是一个简单的三层神经网络。
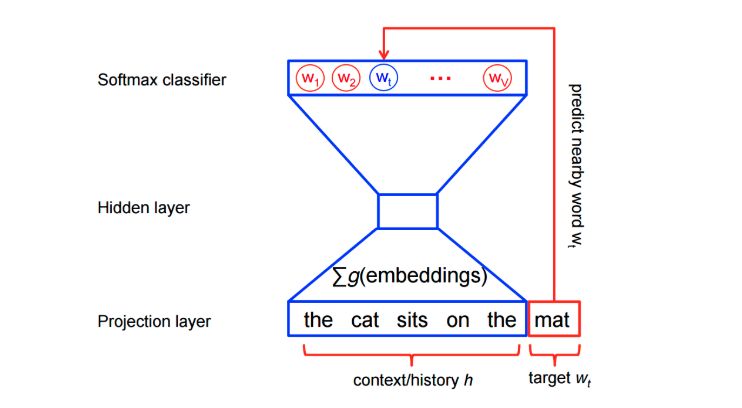
1. 使用一个 3 层神经网络(1 个输入层+ 1 个隐藏层+ 1 个输出层)。
2. 输入一个词,并训练模型来预测它的相邻词汇。
3. 删除最后一层(输出层)并保留输入和隐藏层。
4. 现在,输入一个词汇表中的单词。在隐藏层给出的输出是输入单词的「单词嵌入」。
限制这种参数化方法在大规模语料中的应用的一个主要缺点是计算的效率。具体来说,为了计算单次的正向传播过程,我们需要对整个语料库的词汇进行统计,以计算 softmax 函数。这对于大型数据集来说是非常昂贵的,所以我们希望能够在这个模型和计算效率之间找到一个平衡。
提高计算效率
对于 word2vec 中的特征学习,我们不需要完整的概率模型。CBOW 和 skip-gram 模型是使用二元分类目标(逻辑回归)来训练的,其目标是要在相同的上下文中将真实目标词语(wt)与 k 个伪(噪音)词语 -w 进行区分。
当模型给真实单词分配更高的概率并且将低概率分配给噪音词时,我们可以得到最大化的目标函数。从技术上来讲,我们一般称之为负采样,它提出的更新近似于 softmax 函数更新的极限。但是从计算角度来看,它拥有很高的效率,因为这样一来损失函数的复杂度仅仅依赖于我们选择的噪音词的数量(k)而不是词汇表(V)中的所有单词。这可以大大提高训练的速度。像 Tensorflow 这样的软件包使用了一种非常相似的损失函数,称为噪声对比估计(NCE)损失。
SKIP-GRAM 模型的直观感受
以这个数据集为例:
the quick brown fox jumped over the lazy dog
我们首先构建一个包含所有单词和它们的上下文的数据集。现在,让我们保持原始定义,并将「上下文」定义为目标单词左侧和右侧的窗口单词。设定窗口大小为 1,我们可以得到(上下文,目标)对形式的数据集。
([the, brown], quick), ([quick, fox], brown), ([brown, jumped], fox), ...
回想一下,skip-gram 会颠倒上下文和目标,试图根据目标词预测每个上下文单词,因此任务变为从」quick」预测」the」和」brown」以及从」brown」预测」quick」和」fox」等。
这样一来我们的数据集可以整理为(输入,输出)对,如下所示:
(quick, the), (quick, brown), (brown, quick), (brown, fox), ...
目标函数在定义上依赖于整个数据集,但是我们通常使用随机梯度下降(SGD)方法来对模型进行优化,即每次只使用一个例子(或者每次使用一小批数据,每批的数量通常在 16 到 512 之间)。接下来让我们看一下每一步的训练过程。
让我们想象一下上述例子的训练过程。这里的目标是从 the 预测 quick。我们从一个噪声分布 P(w)(通常是单字符分布)中选取 num_noise 个噪声样本(单字符分布假设每个单词的出现与所有其他单词无关,即我们可以将生成过程看作一个按序列掷骰子的过程)
为了简单起见,我们设定 num_noise = 1,我们选择 sheep 作为一个噪声样本。接下来我们计算这对观察到的和有噪声的例子的损失,即在」t」时刻的目标函数变成:
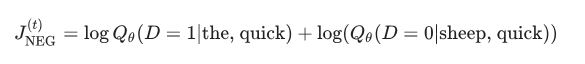
我们的目标是要对嵌入参数进行更新
theta 用来最大化这个目标函数。我们通过导出与之相关的损失梯度来实现这一目标。
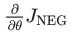
然后,我们通过向梯度方向迈出一小步来更新嵌入。当我们在整个训练集上重复进行这个过程时,可以对每个单词产生「移动」嵌入向量的效果,直到模型成功地区分真实单词和噪音单词为止。
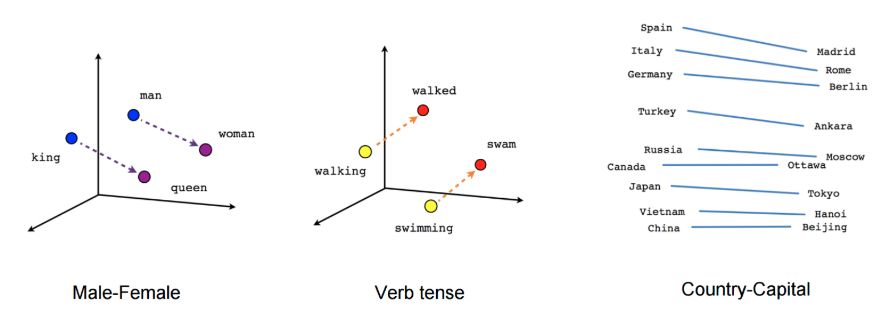
我们可以通过将它们向下投影到 2 维来可视化学习到的向量。当我们观察这些可视化时,很明显这些向量捕获到了一些关于单词的语义信息以及词与词之间的关系,这在实际中是非常有用的。

原文链接:https://towardsdatascience.com/word2vec-a-baby-step-in-deep-learning-but-a-giant-leap-towards-natural-language-processing-40fe4e8602ba
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



