信息瓶颈提出者Naftali Tishby生前指导,129页博士论文「神经网络中的信息流」公布
这篇博士论文在 Tishby 的指导下完成,汇集了师徒二人及其他合著者在深度学习 + 信息论领域的研究成果,非常值得一读。


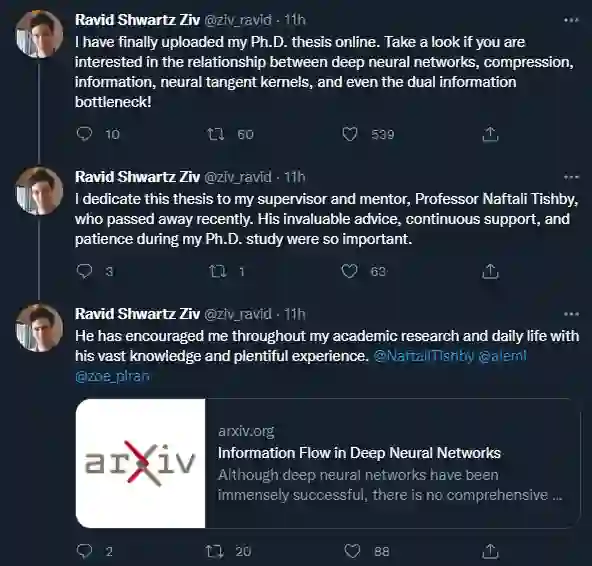






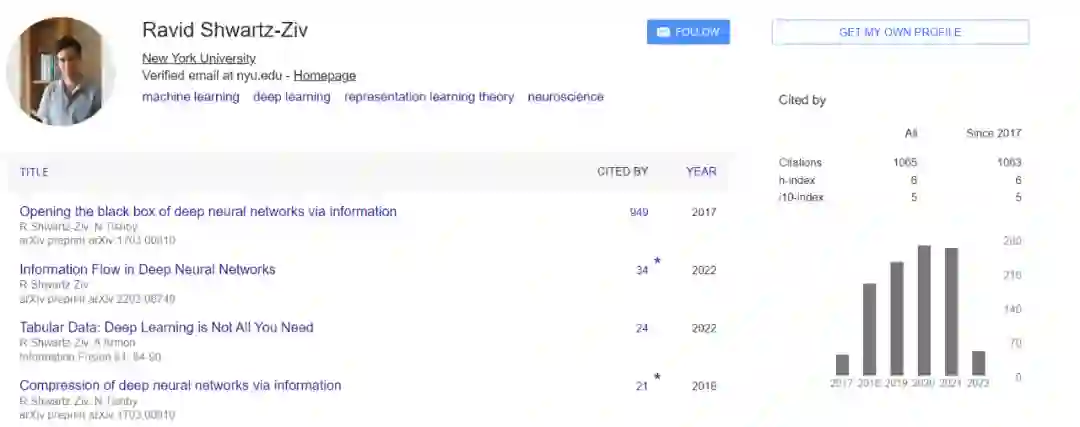

登录查看更多
相关内容
Arxiv
0+阅读 · 2022年4月17日
Arxiv
17+阅读 · 2021年6月18日
Arxiv
36+阅读 · 2021年5月27日




相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月17日
Arxiv
17+阅读 · 2021年6月18日
Arxiv
36+阅读 · 2021年5月27日