2020深度文本匹配最新进展:精度、速度我都要!

文 | QvQ
编 | 兔子酱
在过去的几年里,信息检索(IR)领域见证了一系列神经排序模型的引入,这些模型多是基于表示或基于交互的,亦或二者的融合。然鹅,模型虽非常有效,尤其是基于 PLMs 的排序模型更是增加了几个数量级的计算成本。
为了在 IR 中协调效率和精度,一系列基于表征学习的后期交互类深度排序模型被一一提出,致力于基于交互范式来计算查询 query 和文档 doc 的相关性。
传统做法
传统的 Representation-Based 模型是如下图所示的双塔结构,分别计算 Query 端和 Doc 端的隐层表示,最后选择 Score function(如dot product,cosine similarity)计算相似度。这种方式由于失去了 Query-Doc 之间的交互,可能会产生语义漂移,精度相对来说不是太高,所以一般用来做向量召回或者粗排[1]。
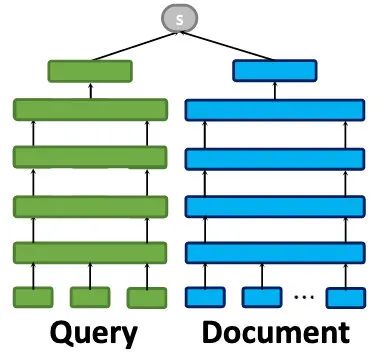
经典模型:DSSM, SNRM
-
优点: 计算量少,Document 可以离线处理得到其表征。线上运行时,只需要在线计算Query 的隐层表示,而 Doc 的隐层表示可以通过查询得到,非常适合精度要求不高,速度要求较快的场合。 -
缺点: 失去了交互信息,类似于 Word2Vec 的问题,学习出来的是一个静态向量,不同上下文场景下,都是同一个表征。
所以,Representation-Based 模型学习出来的语义表达有局限性,没有考虑上下文的信息。
今天介绍的三篇论文就是针对以上局限进行改进。
-
DC-BERT 通过解耦问题和文档实现有效的上下文编码。 -
ColBERT、Poly-encoders 则是在原始的 Representation-Based 模型中增加了弱交互,这种方法既丰富了模型的表达能力,又不会增加太大的计算量,并且 Doc 端还是能够预先处理,保证了在线运行的速度。
Arxiv访问慢的小伙伴也可以在 【夕小瑶的卖萌屋】订阅号后台回复关键词 【0910】 下载论文PDF~
DC-BERT
论文名称:SIGIR 2020 | DC-BERT: Decoupling Question and Document for Efficient Contextual Encoding
arxiv地址:
https://arxiv.org/pdf/2002.12591.pdf
自从预训练语言模型(BERT等)提出,有关开放域 QA 的研究取得了显著改进。目前开放域 QA 的主流方法是 “retrieve and read” 的 pipline 机制。一般通过使用 BERT 模型对retrieve 模块检索出的文档进行 rerank,选出和问句最相关的 Topk 个文档进行后续 read 分析。Rerank 的基本操作是将问题和检索到的每个文档进行拼接作为 BERT 的输入,输出相关性 score。
(向右滑动查看完整公式)
然鹅,由于每一个问题都需要与 retrieve 模块检索出的每一个文档进行拼接,这需要对大量检索文档进行重编码,非常耗时。
为了解决效率问题,DC-BERT 提出具有双重 BERT 模型的解耦上下文编码框架:在线的 BERT 只对问题进行一次编码,而离线的 BERT 对所有文档进行预编码并缓存它们的编码。DC-BERT 在文档检索上实现了 10 倍的加速,同时与最先进的开放域 QA 方法相比,保留了大部分(约98%)的 QA 问答性能。
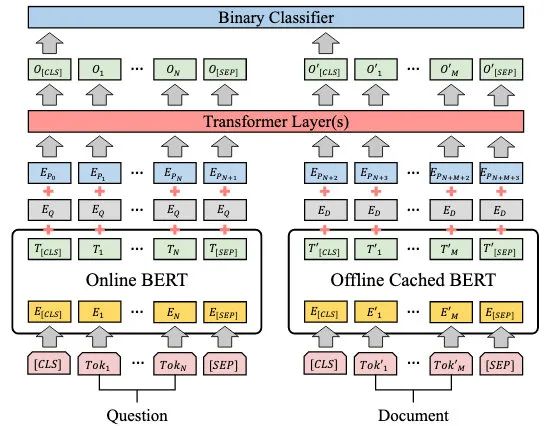
如上图所示,DC-BERT 自底向上分为如下三个部分:
Dual-BERT component
DC-BERT 框架包含两个 BERT 模型,分别对问题和每个检索得到的文档进行编码。
-
在训练期间,算法将更新两个 BERT 模型的参数以优化学习目标;
-
训练模型后,我们会对所有文档进行预编码,并将其编码存储在离线缓存中;
-
在测试期间,我们只使用在线 BERT 模型对问题进行一次编码,并从缓存中读出由 retrieve 模块检索得到的所有候选文档的缓存编码。
这样做的优点在于 DC-BERT 只对 Query 进行一次编码,从而降低了底层 BERT 的编码计算成本。
Transformer component
通过 Dual-BERT component模块,获取到问题的编码 和文档编码 ,其中 是词嵌入的维数, 和 分别是问题和文档的长度。由于 rerank 是预测文档与问题的相关性,因此引入了一个带有训练 global embeddings 的Transformer 组件来使问题和文档进行交互。
具体来讲,全局 position embeddings 和 type embeddings 被加入到问题和文档的顶层编码中,用预训练 BERT 的 position embeddings 和 type embeddings 进行初始化,之后送入 Transformer 层进行深度交互,并在训练过程中进行更新。
Classifier component
DC-BERT 框架将 ReRank 任务作为一个二分类任务,通过计算候选文档是否与该问题相关来进行重排序。如下:
(向右滑动查看完整公式)
其中, 是问题和候选文档对; 和 分别是问题和文档的 token 经过 Transformer 模块的输出(经过交互后的输出)。
这篇论文的核心思路是采用两个 BERT 模型,一个 offline 模型提前向量化;一个online 的模型实时在线计算 query 的词级别向量表示,最后再用一层 Transformer 做线上相关性预测。
ColBERT
论文名称:SIGIR 2020 | ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT
arxiv地址:
https://arxiv.org/pdf/2004.12832.pdf
ColBERT 提出了一种新颖的后期交互范式。为了同时兼顾匹配的效率和doc中的上下文信息,ColBERT 提出了基于上下文(contextualized)的后期交互的排序模型,用于估计查询 query 和文档 doc 之间的相关性。query 和doc 分别通过各自的 encoder 编码,得到两组 token level 的 embedding 集合;然后,评估 query 和 doc 中的每个 item 的关联,得到快速排序的目的。
ColBERT 的模型结构整体还是类似于 Siamese 结构,分为 Query 端和 Doc 端,最后在进行交互计算文本分相似度。模型主体上分为 Query Encoder 、Document Encoder 、以及之后的 Late Interaction 部分。
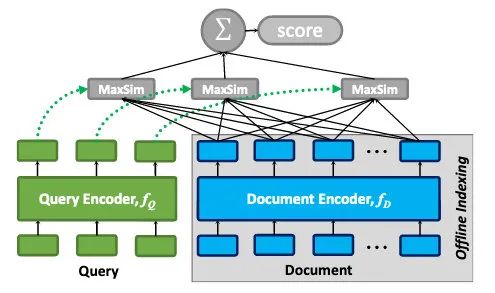
每个查询嵌入都通过 MaxSim 运算符与所有文档嵌入进行交互,该运算符会计算最大相似度(如余弦相似度),并且这些运算符的标量输出会在查询条件中相加。这种范例使 ColBERT 可以利用基于 LMs的深度表示,同时将离线编码文档的成本转移到所有排序文档中,并一次摊销编码查询的成本。
Query Encoder
Query Encoder计算如下:
(向右滑动查看完整公式)
通过在查询 query 之前添加特殊标记 ,在文档之前添加另一个标记 ,来区分与查询和文档相对应的输入序列。BERT 是编码器,CNN 是做维度变换,用来对 BERT 输出降维,Normalize 为了之后计算余弦相似度而做的正则化处理。
值得注意的是,文章对 query 填充掩码标记的另外一个目的是做 query augmentation,这一步骤允许 BERT 在与这些掩码相对应的位置上生成基于查询的新嵌入,这一机制旨在对 query 中新术语或者重要词进行重新编码学习。
Document Encoder
结构与query encoder类似,主要区别如下:
-
添加筛选器 Filter。因为 Doc 一般比较长,Filter 通过一个预定义的列表对文档中一些特殊的 token 以及标点符号进行过滤。 -
没有添加 mask token。
(向右滑动查看完整公式)
Late Interaction
这一步操作则是针对与Representation-Based方法的改进,对 query 和 doc 的信息进行了交互,具体公式如下:
计算 query 中每个 term 与 doc 的每个 term 的最大相似度,然后累加得到 score。由于之前进行过 Normalize,我们只需要计算 inner-products 得到的即为余弦相似度。
实验结论
文章采用了 Microsoft 于 2016 年引入的阅读理解的数据集 MS MARCO,它是从网页中收集的800万个段落的集合,这些段落是从必应收集到100万个实际查询的结果。
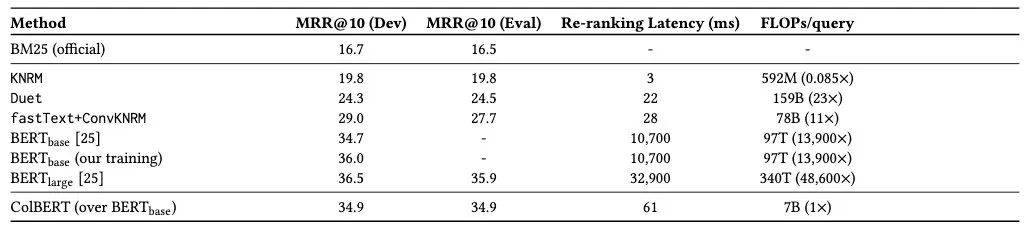
通过实验数据对比可以看出,ColBERT 的效果比传统 ConvKNRM 明显要好,此外检索的速度比 BERT-base 模型要快几个数量级。

Poly-encoders
论文名称:ICLR 2020 | Poly-encoders: Transformer Architectures and Pre-training Strategies for Fast and Accurate Multi-sentence Scoring
arxiv地址:
https://arxiv.org/pdf/1905.01969.pdf
在 BERT 兴起之后,基于 concat 的 self-attention 模型大量涌现。如下图所示,query 和 candidate 拼成一句话,使得模型可以对 query 和 doc 进行深度交互,充分发挥 BERT 的 next sentence 任务的作用。本篇论文实现的交互式匹配(Cross-encoder)也是基于这种架构。交互式匹配的核心思想是则是 query 和 candidates 时时刻刻都应相互感知,信息相互交融,从而更深刻地感受到相互之间是否足够匹配。
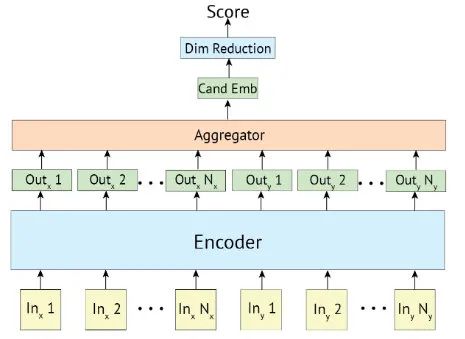
相较于 Siamese Network (Bi-encoder),这类交互式匹配方案可以在Q(Query)和D(Doc)之间实现更细粒度的匹配,所以通常可以取得更好的匹配效果。但是很显然,这类方案无法离线计算candidates 的表征向量,每处理一个 query 都只能遍历所有(query, candidate) 的 pairs 依次计算相关性,这种时间和计算开销在工业界是不被允许的。
模型结构
总的来说,本文是对速度快但质量不足的 Bi-encoder 架构和质量高但速度慢的 Cross-encoder 架构的一种折中,其基本结构如下图:
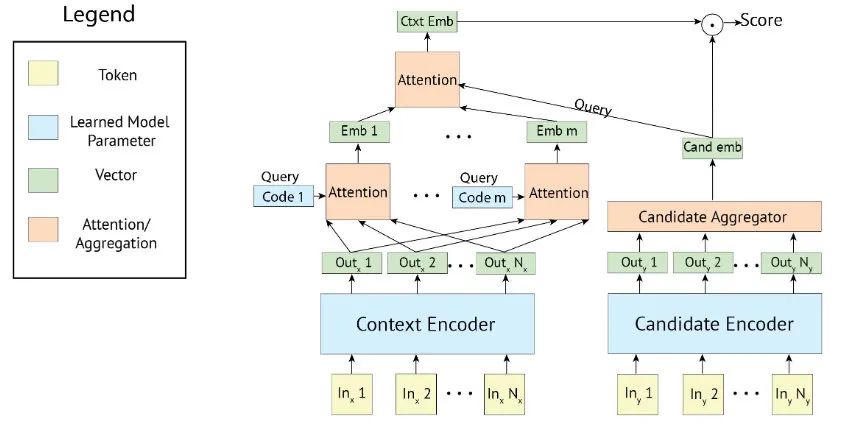
Poly-encoder的思想非常简单。将给定的候选标签用Bi-encoder中的一个向量表示,从而可以缓存候选 doc 的内容以加快推理时间。在推理阶段,将 query 的多种语义编码利用 attention 机制与候选 content 共同作用,从而可以提取更多信息。content 是 doc 文本经过离线 Candidate Encoder 编码得到语义向量。
具体来讲:
-
Poly-encoder首先是通过初始化多个attention模块,对每一个query产生不同的 ,以此获取 query 中一词多义或切词带来的不同语义信息;
(向右滑动查看完整公式)
-
将这些具有相同维度的query语义向量进行动态组合成最终的 ;
(向右滑动查看完整公式)
-
最后计算 与每一个由 Bi-encoder 编码的候选 的匹配程度。
很显然,Poly-encoder 架构在实际部署时是可以离线计算好所有 candidates 的向量 ,线上部分只需要计算 query 对应的 m 个 向量,再通过简单的 dot product 就可以快速计算 query 对应每个 candidate 的动态的得分 。看起来 Poly-encoder 享有 Bi-encoder 的速度,同时又有实现更精准匹配的潜力。
实验效果
本文选择了检索式对话数据集 ConvAI2、DSTC 7、Ubuntu v2 以及Wikipedia IR 数据集进行实验。负采样方式为:在训练过程中,使用同一个 batch 中的其他 query 对应的 response 作为负样本,而 Cross-encoder 的负采样方式为:在开始训练之前,随机采样 15 个 responses 作为负样本[2]。
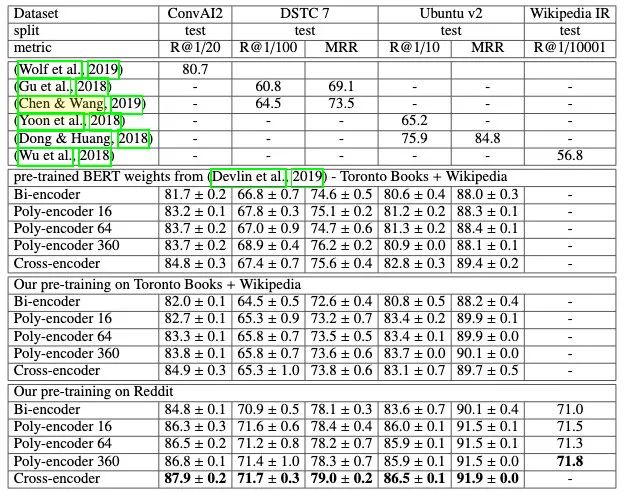
实验结果已经表明 Poly-encoder 明显优于 Bi-encoder架构,且性能逼近 Cross-encode 架构的效果。在检索耗时方面,其速度比 Cross-encoder 足足快了约 2600-3000倍!
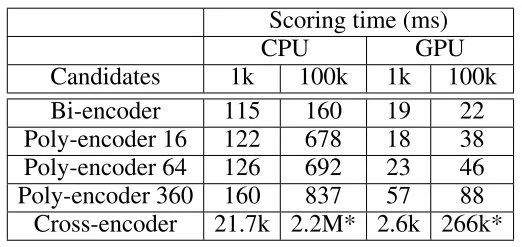
本文提出的 Poly-encoder 的核心思想虽然非常简单,但是却十分有效,确实在很多场景下可以作为 Bi-encoder 的替代,甚至在一些对速度要求较高的场景下可以作为 Cross-encoder 的替代。
参考文献
[1] 基于表征(Representation)文本匹配、信息检索、向量召回的方法总结
https://zhuanlan.zhihu.com/p/140323216
[2] PolyEncoder-Facebook的全新信息匹配架构-提速3000倍
https://zhuanlan.zhihu.com/p/119444637
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心![]() 。
。
欢迎加入AINLP技术交流群
进群请添加AINLP小助手微信 AINLPer(id: ainlper),备注NLP技术交流
![]()
推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。
![]()
阅读至此了,分享、点赞、在看三选一吧🙏







