近年来,以知识图谱快速增长的知识工程又重新兴起。然而,现有的知识图谱大多用纯符号表示,这损害了机器理解现实世界的能力。知识图谱的多模态化是实现人机智能的必然步骤。这一努力的结果是多模态知识图(MMKGs)。在本研究中,我们首先给出了由文本和图像构成的多模态任务的定义,然后对多模态任务和技术进行了初步探讨。然后,我们系统地回顾了MMKG在构建和应用方面所面临的挑战、进展和机遇,并详细分析了不同解决方案的优势和劣势。我们通过与MMKG相关的开放研究问题来完成这项综述。
引言
近年来,以知识图谱快速增长的知识工程又重新兴起。知识图谱本质上是一个以实体、概念为节点、以概念之间的各种语义关系为边的大规模语义网络。知识图谱在现实生活中广泛应用,包括文本理解、推荐系统和自然语言问题回答。越来越多的知识图谱被创建出来,包括常识知识(如Cyc[1]、ConceptNet[2])、词汇知识(如WordNet[3]、BabelNet[4])、百科知识(如Freebase[5]、DBpedia[6]、YAGO[7]、WikiData[8]、CN-Dbpedia[9])、分类知识(如Probase[10])和地理知识(如GeoNames[11])。
然而,现有的知识图谱大多是用纯符号表示的,以文本的形式表示,这削弱了机器对现实世界的描述和理解能力。人类如果没有与狗相处的经历,就无法理解狗是什么,这就启发了研究人员在符号dog和狗的经历之间建立联系,即将一个符号根植于它的物理世界,即[12],[13],[14]。同样,将符号形式与非符号体验相结合,有利于获得真实的交际意图[15]。例如,没有亲身体验过hand -in-waistcoat的顾客无法理解作为一种特殊姿势(手放在外套翻盖内)的含义,从而导致顾客对摄影师的要求做出错误的反应。因此,有必要将符号与相应的图像、声音和视频数据相对应,并将符号映射到物理世界中具有意义的对应对象,使机器在面对特定的实体Hand-in-waistcoat或抽象概念Dog时,能够产生类似于真实人类[12]的“体验”。另一方面,为了突破现实世界应用程序[16]、[17]、[18]的瓶颈,对知识的多模态需求日益增长。例如,在关系提取任务中,额外的图像通常会大大提高提取符号和文本中那些在视觉上很明显但难以识别的属性和关系的性能,例如:键盘和屏幕是笔记本电脑的一部分,颜色是(例如:香蕉通常是黄色或黄绿色,但不是蓝色)。在文本生成任务中,如果机器通过参考多模态KG (MMKG),被赋予识别图像中特定实体的能力,机器可以生成一个信息更丰富的实体级句子(例如唐纳德·特朗普正在发表演讲),而不是一个模糊的概念级描述(例如一个金发高个子男人正在发表演讲)。
由于各种应用对多模态知识引导需求的快速增长,知识引导的多模态及其应用近年来蓬勃发展。但目前对这一新兴领域的研究进展、面临的挑战和面临的机遇还缺乏系统的综述。本文希望填补这一空白,系统地综述近年来有关MMKG的研究进展: 1) 构建。MMKG的构造可以在两个相反的方向上进行。一种是从图像到符号,即用KG表示符号来标注图像; 另一种是从符号到图像,即把KG中的符号对应到图像。在构建部分,我们将系统地介绍将各种符号知识(包括实体、概念、关系和事件)与它们在两个相反方向上的对应图像关联起来的挑战、进展和机遇。2)应用。MMKG的应用可以大致分为两类,一类是In-MMKG应用,目的是解决MMKG本身的质量或集成问题,另一类是MMKG外应用,这是一般的多模态任务,mmkg可以提供帮助。在应用部分,我们将介绍如何将mmkg应用于几个经过充分研究的多模态任务中。
综上所述,我们是第一个对现有的由文本和图像组成的MMKG的工作进行全面综述的。为了提升本次调查的价值,我们注意确保以下特点:1)全面调研。我们系统、全面地回顾了MMKG建设和应用方面的现有工作。2)深刻的分析。我们分析了不同解决方案在MMKG建设中的优缺点,并讨论了MMKG如何在各种下游应用中提供帮助。3)显示的机会。本文不仅指出了MMKG建设的一些潜在机遇,而且还列举了MMKG未来的发展方向。
本论文的其余部分组织如下: 第2节给出了MMKG的定义和初步。第3节全面回顾了MMKGs构建面临的挑战、进展和机遇,第4节介绍了MMKG如何应用于几个已深入研究的多模态应用中。第5节回顾了MMKG的一些未决问题,并强调了有前途的未来方向。第六节总结了本文。
多模态知识图谱构建
MMKG构建的实质是将传统KG中的符号知识(包括实体、概念、关系等)与相应的图像相关联。完成该任务有两种相反的方式: (1) 在图像上标注KG中的符号; (2) 在图像上标注KG中的对应符号。我们分别在第3.1节和第3.2节中阐述了两类解决方案。
从图像到符号:标注图像
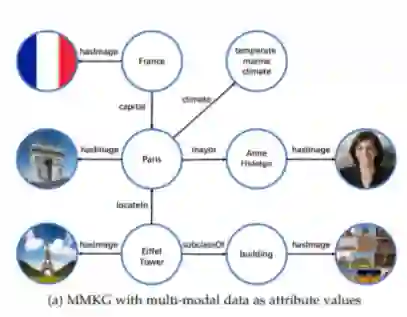
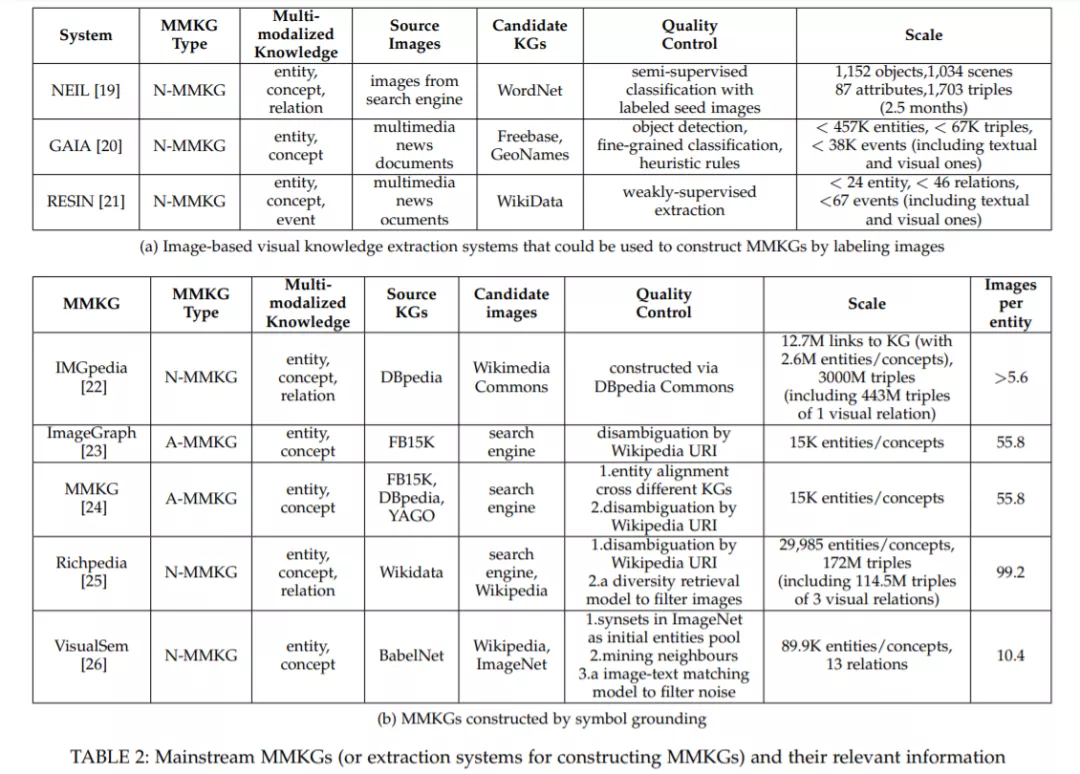
CV社区已经开发了许多图像标注解决方案,这些解决方案可用于在KG中使用知识符号标注图像。大多数图像标记解决方案学习从图像内容到各种各样的标签集的映射,包括对象、场景、实体、属性、关系、事件和其他符号。学习过程由人工标注的数据集监督,这需要人群工作者绘制边界框并标注带有给定标签的图像或图像区域,如图2所示。一些知名的基于图像的视觉知识提取系统如表2a所示,可以通过图像标记来构建MMKG。根据需要链接的符号类别,将图像与符号链接的过程分为几个细分任务: 视觉实体/概念提取(3.1.1)、视觉关系提取(3.1.2)和视觉事件提取(3.1.3)。
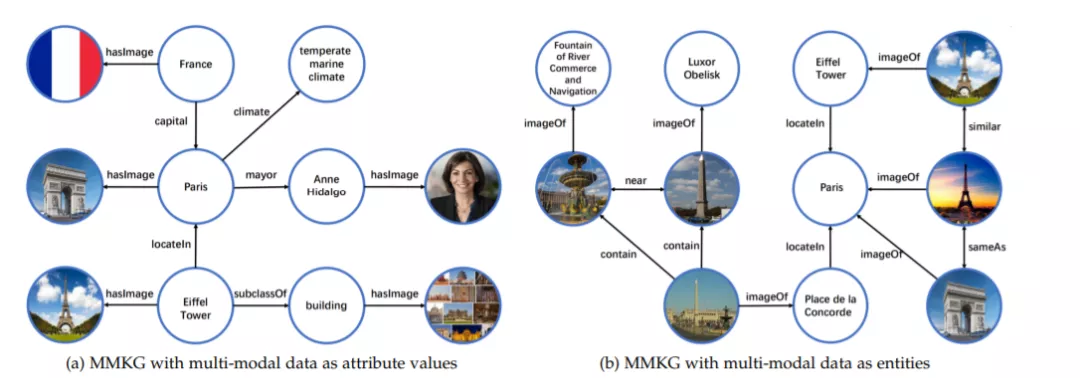
从符号到图像: 符号定位(Grounding)
符号定位符号Grounding是指寻找合适的多模态数据项(如图像)来表示传统KG中存在的符号知识的过程。与图像标注方式相比,符号定位方式在MMKG施工中应用更为广泛。大多数现有的MMKG都是以这种方式构建的,如表2b所示。在本小节的其余部分,我们将在几个细分任务中介绍将符号定位到图像的过程:实体定位(第3.2.1节)、概念定位(第3.2.2节)和关系定位(第3.2.3节)。
多模态知识图谱应用
在系统地回顾了MMKG的构建之后,本节探讨了如何将MMKG中的知识应用到各种各样的下游任务中并使之受益。为了快速概述,表5列出了一些主流应用任务、它们的基准数据集以及MMKG带来的优势。我们将这些任务分为(i) in-KG应用(4.1节)和(ii) out- kg应用程序(4.2节),如下所述
In-MMKG应用
In-MMKG应用是指在MMKG范围内进行的任务,在这些任务中,已经学习了实体、概念和关系的嵌入。因此,在介绍in-MMKG应用程序之前,我们先简要介绍MMKG中知识的分布式表示学习,也称为MMKG嵌入。其中,MMKG嵌入模型是从传统KGs上的嵌入模型发展而来的,即基于距离的模型[133],认为同一三联体的头实体和尾实体在投影空间上应该相近,基于翻译的模型TransE[134]及其变体[135],[136],[137],其中应符合t≈h + r的假设。h, t, r分别是三元组中头部实体、尾部实体和关系的向量表示。在处理多模态数据时,还有两个额外的问题:如何有效地编码图像中的视觉知识和信息,以及如何融合不同模态的知识。1)视觉编码器。尽管CV中已有许多现成的图像信息编码技术,但随着深度学习的发展,卷积神经网络的隐藏特征是MMKG表示中主要使用的图像嵌入方法[138]、[139]、[140],而其他显式视觉特征如灰度直方图描述符(GHD)、面向梯度直方图描述符(HOG)、颜色布局描述符(CLD)很难用于MMKG表示。2)知识融合。为了融合多模态的知识嵌入,考虑了多种融合方法,包括简单的拼接、多模态嵌入的平均值、基于归一化或加权的SVD和PCA[139],而有些方法[139]直接将融合结果作为MMKG嵌入,其他方法[140]进一步训练设计良好的目标函数上的单模态表示。
- 链接预测 Link Prediction
- 三元组分类 Triple Classification
- 实体链接 Entity Classification
- 实体对齐 Entity Alignment
out-of-KG 应用
out-of-KG应用是指不受mmkg限制,但可以被mmkg辅助的下游应用。接下来,我们将介绍多模态命名实体识别和实体链接、视觉问答、图像-文本匹配、多模态生成和多模态推荐系统等应用实例。我们没有对这些任务的所有解决方案进行系统的回顾,而是主要介绍了MMKG是如何使用的。
- 多模态实体识别与链接 Multi-modal Entity Recognition and Linking
- 视觉问答 Visual Question Answering
- 图像文本匹配 Image-Text Matching
- 多模态生成任务 Multi-modal Generation Tasks
- 多模态推荐系统 Multi-modal Recommender System
多模态知识图谱开放问题
- 复杂符号知识定位Grounding Complex Symbolic Knowledge Grounding
除了实体、概念和关系的基础之外,一些下游应用还需要复杂的符号知识的基础,这些知识由多个相互具有密切语义关系的关系事实组成。这些多个关系事实可能是KG中的一条路径或一个子图。例如,对于KG中包含特朗普妻子、女儿、孙子等的子图,合适的背景图片可能是特朗普的家庭照片。这将促使多重关系基础,其目的是寻找表示包含在KG中的路径或子图中的知识的图像。多重关系定位是一种具有挑战性的grounding 方式,它涉及到多个关系的接地,并且这些多个grounding通常以复杂的方式交织在一起。我们必须找到充分体现复合语义关系的图像。在许多情况下,复合语义只是隐式表达的,并且可能随着时间而改变。
- 质量控制 Quality Control
通常,我们依赖于数据驱动的方法来构建大规模的MMKG。从大数据中自动获取的MMKG不可避免地会出现质量问题,即MMKG可能存在错误、缺少事实或过时的事实。例如,在基于搜索行为数据的多模态知识获取中,很容易将一个错误的图像与一个长尾实体相关联,因为该实体在Web上可能没有图像,因此任何点击的图像都会误导到一个错误的grounding。MMKG除了在精度、完整性、一致性和新鲜度等常见的质量问题上进行了广泛的讨论和研究外,还存在一些与图像质量有关的特殊问题。
- 效率 fficiency 在构建大规模KG时,效率始终是一个不可忽视的问题。构造MMKG的效率问题更引人注目,因为需要考虑处理多媒体数据的额外复杂性。例如,NEIL[19]需要大约350K CPU小时来为2273个对象收集400K的可视化实例,而在一个典型的KG中,我们需要接收数十亿个实例。在构建MMKG中,现有解决方案的可扩展性将受到极大的挑战。如果基础目标是视频数据,那么可扩展性问题甚至可能被放大。除了MMKG的构建,MMKG的在线应用还需要认真解决效率问题,因为MMKG需要实时服务于应用。解决方案的效率对于构建基于MMKG的在线应用至关重要。